Kafka main parsing loop
One of the threads from scheduled_pool (pre 20.9) / background_message_broker_schedule_pool (after 20.9) do that in infinite loop:
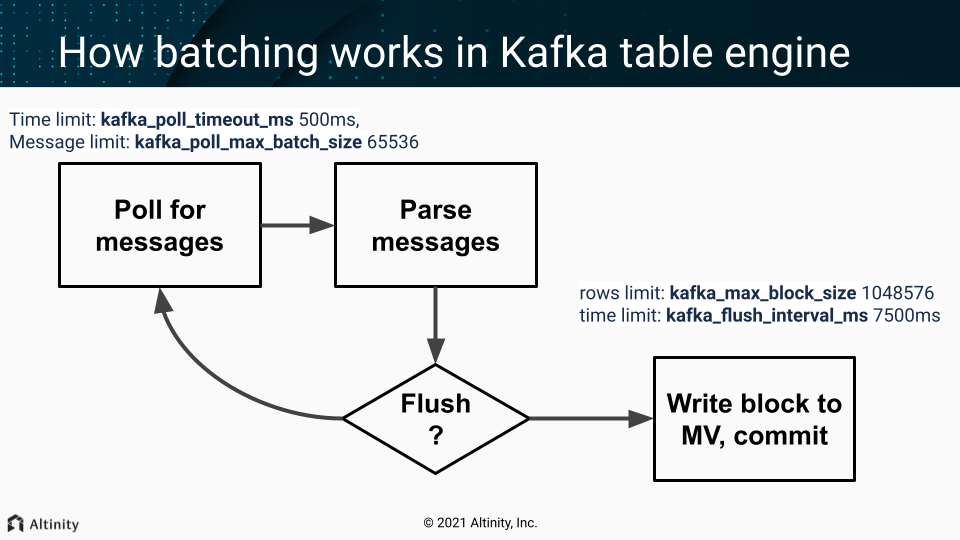
- Batch poll (time limit:
kafka_poll_timeout_ms500ms, messages limit:kafka_poll_max_batch_size65536) - Parse messages.
- If we don’t have enough data (rows limit:
kafka_max_block_size1048576) or time limit reached (kafka_flush_interval_ms7500ms) - continue polling (goto p.1) - Write a collected block of data to MV
- Do commit (commit after write = at-least-once).
On any error, during that process, Kafka client is restarted (leading to rebalancing - leave the group and get back in few seconds).
Important settings
These usually should not be adjusted:
kafka_poll_max_batch_size= max_block_size (65536)kafka_poll_timeout_ms= stream_poll_timeout_ms (500ms)
You may want to adjust those depending on your scenario:
kafka_flush_interval_ms= stream_poll_timeout_ms (7500ms)kafka_max_block_size= max_insert_block_size / kafka_num_consumers (for the single consumer: 1048576)
See also
https://github.com/ClickHouse/ClickHouse/pull/11388
Disable at-least-once delivery
kafka_commit_every_batch = 1 will change the loop logic mentioned above. Consumed batch commited to the Kafka and the block of rows send to Materialized Views only after that. It could be resembled as at-most-once delivery mode as prevent duplicate creation but allow loss of data in case of failures.