Internals:
https://github.com/ClickHouse/clickhouse-presentations/blob/master/meetup41/merge_tree.pdf
This is the multi-page printable view of this section. Click here to print.
| ReplacingMergeTree | CollapsingMergeTree |
|---|---|
| + very easy to use (always replace) | - more complex (accounting-alike, put ‘rollback’ records to fix something) |
| + you don’t need to store the previous state of the row | - you need to the store (somewhere) the previous state of the row, OR extract it from the table itself (point queries is not nice for ClickHouse®) |
| - no deletes | + support deletes |
| - w/o FINAL - you can can always see duplicates, you need always to ‘pay’ FINAL performance penalty | + properly crafted query can give correct results without final (i.e. sum(amount * sign) will be correct, no matter of you have duplicated or not) |
- only uniq()-alike things can be calculated in materialized views | + you can do basic counts & sums in materialized views |
Part name format is:
<partitionid>_<min_block_number>_<max_block_number>_<level>_<data_version>
system.parts contains all the information parsed.
partitionid is quite simple (it just comes from your partitioning key).
What are block_numbers?
DROP TABLE IF EXISTS part_names;
create table part_names (date Date, n UInt8, m UInt8) engine=MergeTree PARTITION BY toYYYYMM(date) ORDER BY n;
insert into part_names VALUES (now(), 0, 0);
select name, partition_id, min_block_number, max_block_number, level, data_version from system.parts where table = 'part_names' and active;
┌─name─────────┬─partition_id─┬─min_block_number─┬─max_block_number─┬─level─┬─data_version─┐
│ 202203_1_1_0 │ 202203 │ 1 │ 1 │ 0 │ 1 │
└──────────────┴──────────────┴──────────────────┴──────────────────┴───────┴──────────────┘
insert into part_names VALUES (now(), 0, 0);
select name, partition_id, min_block_number, max_block_number, level, data_version from system.parts where table = 'part_names' and active;
┌─name─────────┬─partition_id─┬─min_block_number─┬─max_block_number─┬─level─┬─data_version─┐
│ 202203_1_1_0 │ 202203 │ 1 │ 1 │ 0 │ 1 │
│ 202203_2_2_0 │ 202203 │ 2 │ 2 │ 0 │ 2 │
└──────────────┴──────────────┴──────────────────┴──────────────────┴───────┴──────────────┘
insert into part_names VALUES (now(), 0, 0);
select name, partition_id, min_block_number, max_block_number, level, data_version from system.parts where table = 'part_names' and active;
┌─name─────────┬─partition_id─┬─min_block_number─┬─max_block_number─┬─level─┬─data_version─┐
│ 202203_1_1_0 │ 202203 │ 1 │ 1 │ 0 │ 1 │
│ 202203_2_2_0 │ 202203 │ 2 │ 2 │ 0 │ 2 │
│ 202203_3_3_0 │ 202203 │ 3 │ 3 │ 0 │ 3 │
└──────────────┴──────────────┴──────────────────┴──────────────────┴───────┴──────────────┘
As you can see every insert creates a new incremental block_number which is written in part names both as <min_block_number> and <min_block_number> (and the level is 0 meaning that the part was never merged).
Those block numbering works in the scope of partition (for Replicated table) or globally across all partition (for plain MergeTree table).
ClickHouse® always merge only continuous blocks . And new part names always refer to the minimum and maximum block numbers.
OPTIMIZE TABLE part_names;
┌─name─────────┬─partition_id─┬─min_block_number─┬─max_block_number─┬─level─┬─data_version─┐
│ 202203_1_3_1 │ 202203 │ 1 │ 3 │ 1 │ 1 │
└──────────────┴──────────────┴──────────────────┴──────────────────┴───────┴──────────────┘
As you can see here - three parts (with block number 1,2,3) were merged and they formed the new part with name 1_3 as min/max block size. Level get incremented.
Now even while previous (merged) parts still exists in filesystem for a while (as inactive) ClickHouse is smart enough to understand that new part ‘covers’ same range of blocks as 3 parts of the prev ‘generation’
There might be a fifth section in the part name, data version.
Data version gets increased when a part mutates.
Every mutation takes one block number:
insert into part_names VALUES (now(), 0, 0);
insert into part_names VALUES (now(), 0, 0);
insert into part_names VALUES (now(), 0, 0);
select name, partition_id, min_block_number, max_block_number, level, data_version from system.parts where table = 'part_names' and active;
┌─name─────────┬─partition_id─┬─min_block_number─┬─max_block_number─┬─level─┬─data_version─┐
│ 202203_1_3_1 │ 202203 │ 1 │ 3 │ 1 │ 1 │
│ 202203_4_4_0 │ 202203 │ 4 │ 4 │ 0 │ 4 │
│ 202203_5_5_0 │ 202203 │ 5 │ 5 │ 0 │ 5 │
│ 202203_6_6_0 │ 202203 │ 6 │ 6 │ 0 │ 6 │
└──────────────┴──────────────┴──────────────────┴──────────────────┴───────┴──────────────┘
insert into part_names VALUES (now(), 0, 0);
alter table part_names update m=n where 1;
select name, partition_id, min_block_number, max_block_number, level, data_version from system.parts where table = 'part_names' and active;
┌─name───────────┬─partition_id─┬─min_block_number─┬─max_block_number─┬─level─┬─data_version─┐
│ 202203_1_3_1_7 │ 202203 │ 1 │ 3 │ 1 │ 7 │
│ 202203_4_4_0_7 │ 202203 │ 4 │ 4 │ 0 │ 7 │
│ 202203_5_5_0_7 │ 202203 │ 5 │ 5 │ 0 │ 7 │
│ 202203_6_6_0_7 │ 202203 │ 6 │ 6 │ 0 │ 7 │
│ 202203_8_8_0 │ 202203 │ 8 │ 8 │ 0 │ 8 │
└────────────────┴──────────────┴──────────────────┴──────────────────┴───────┴──────────────┘
OPTIMIZE TABLE part_names;
select name, partition_id, min_block_number, max_block_number, level, data_version from system.parts where table = 'part_names' and active;
┌─name───────────┬─partition_id─┬─min_block_number─┬─max_block_number─┬─level─┬─data_version─┐
│ 202203_1_8_2_7 │ 202203 │ 1 │ 8 │ 2 │ 7 │
└────────────────┴──────────────┴──────────────────┴──────────────────┴───────┴──────────────┘
Good order by usually has 3 to 5 columns, from lowest cardinal on the left (and the most important for filtering) to highest cardinal (and less important for filtering).
Practical approach to create a good ORDER BY for a table:
tenant_idsite_id, or source_id, or group_id or something similar.Some examples of good ORDER BY:
ORDER BY (tenantid, site_id, utm_source, clientid, timestamp)
ORDER BY (site_id, toStartOfHour(timestamp), sessionid, timestamp )
PRIMARY KEY (site_id, toStartOfHour(timestamp), sessionid)
(FWIW, the Altinity blog has a great article on the LowCardinality datatype .)
All dimensions go to ORDER BY, all metrics - outside of that.
The most important for filtering columns with the lowest cardinality should be the left-most.
If the number of dimensions is high, it typically makes sense to use a prefix of ORDER BY as a PRIMARY KEY to avoid polluting the sparse index.
Examples:
ORDER BY (tenant_id, hour, country_code, team_id, group_id, source_id)
PRIMARY KEY (tenant_id, hour, country_code, team_id)
You need to keep all ‘mutable’ columns outside of ORDER BY, and have some unique id (a base to collapse duplicates) inside. Typically the right-most column is some row identifier. And it’s often not needed in sparse index (so PRIMARY KEY can be a prefix of ORDER BY) The rest consideration are the same.
Examples:
ORDER BY (tenantid, site_id, eventid) -- utm_source is mutable, while tenantid, site_id is not
PRIMARY KEY (tenantid, site_id) -- eventid is not used for filtering, needed only for collapsing duplicates
Also read about LIGHT ORDER BY for speeding FINAL queries - https://kb.altinity.com/altinity-kb-queries-and-syntax/altinity-kb-final-clause-speed/#light-order-by
-- col1: high Cardinality
-- col2: low cardinality
CREATE TABLE tests.order_test
(
`col1` DateTime,
`col2` UInt8
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(col1)
ORDER BY (col1, col2)
--
SELECT count()
┌───count()─┐
│ 126371225 │
└───────────┘
So let’s put the highest cardinal column to the left and the least to the right in the ORDER BY definition. This will impact in queries like:
SELECT * FROM order_test
WHERE col1 > toDateTime('2020-10-01')
ORDER BY col1, col2
FORMAT `Null`
Here for the filtering it will use the skipping index to select the parts WHERE col1 > xxx and the result won’t be need to be ordered because the ORDER BY in the query aligns with the ORDER BY in the table and the data is already ordered in disk. (FWIW, Alexander Zaitsev and Mikhail Filimonov wrote a great post on skipping indexes and how they work
for the Altinity blog.)
executeQuery: (from [::ffff:192.168.11.171]:39428, user: admin) SELECT * FROM order_test WHERE col1 > toDateTime('2020-10-01') ORDER BY col1,col2 FORMAT Null; (stage: Complete)
ContextAccess (admin): Access granted: SELECT(col1, col2) ON tests.order_test
ContextAccess (admin): Access granted: SELECT(col1, col2) ON tests.order_test
InterpreterSelectQuery: FetchColumns -> Complete
tests.order_test (SelectExecutor): Key condition: (column 0 in [1601503201, +Inf))
tests.order_test (SelectExecutor): MinMax index condition: (column 0 in [1601503201, +Inf))
tests.order_test (SelectExecutor): Running binary search on index range for part 202010_367_545_8 (7612 marks)
tests.order_test (SelectExecutor): Running binary search on index range for part 202010_549_729_12 (37 marks)
tests.order_test (SelectExecutor): Running binary search on index range for part 202011_689_719_2 (1403 marks)
tests.order_test (SelectExecutor): Running binary search on index range for part 202012_550_730_12 (3 marks)
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 37
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 3
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 1403
tests.order_test (SelectExecutor): Found continuous range in 11 steps
tests.order_test (SelectExecutor): Found continuous range in 3 steps
tests.order_test (SelectExecutor): Running binary search on index range for part 202011_728_728_0 (84 marks)
tests.order_test (SelectExecutor): Found continuous range in 21 steps
tests.order_test (SelectExecutor): Running binary search on index range for part 202011_725_725_0 (128 marks)
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 84
tests.order_test (SelectExecutor): Running binary search on index range for part 202011_722_722_0 (128 marks)
tests.order_test (SelectExecutor): Found continuous range in 13 steps
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 128
tests.order_test (SelectExecutor): Found continuous range in 14 steps
tests.order_test (SelectExecutor): Running binary search on index range for part 202011_370_686_19 (5993 marks)
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 5993
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found continuous range in 25 steps
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 128
tests.order_test (SelectExecutor): Found continuous range in 14 steps
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 7612
tests.order_test (SelectExecutor): Found continuous range in 25 steps
tests.order_test (SelectExecutor): Selected 8/9 parts by partition key, 8 parts by primary key, 15380/15380 marks by primary key, 15380 marks to read from 8 ranges
Ok.
0 rows in set. Elapsed: 0.649 sec. Processed 125.97 million rows, 629.86 MB (194.17 million rows/s., 970.84 MB/s.)
If we change the ORDER BY expression in the query, ClickHouse will need to retrieve the rows and reorder them:
SELECT * FROM order_test
WHERE col1 > toDateTime('2020-10-01')
ORDER BY col2, col1
FORMAT `Null`
As seen In the MergingSortedTransform message, the ORDER BY in the table definition is not aligned with the ORDER BY in the query, so ClickHouse has to reorder the resultset.
executeQuery: (from [::ffff:192.168.11.171]:39428, user: admin) SELECT * FROM order_test WHERE col1 > toDateTime('2020-10-01') ORDER BY col2,col1 FORMAT Null; (stage: Complete)
ContextAccess (admin): Access granted: SELECT(col1, col2) ON tests.order_test
ContextAccess (admin): Access granted: SELECT(col1, col2) ON tests.order_test
InterpreterSelectQuery: FetchColumns -> Complete
tests.order_test (SelectExecutor): Key condition: (column 0 in [1601503201, +Inf))
tests.order_test (SelectExecutor): MinMax index condition: (column 0 in [1601503201, +Inf))
tests.order_test (SelectExecutor): Running binary search on index range for part 202010_367_545_8 (7612 marks)
tests.order_test (SelectExecutor): Running binary search on index range for part 202012_550_730_12 (3 marks)
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Running binary search on index range for part 202011_725_725_0 (128 marks)
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 3
tests.order_test (SelectExecutor): Running binary search on index range for part 202011_689_719_2 (1403 marks)
tests.order_test (SelectExecutor): Running binary search on index range for part 202010_549_729_12 (37 marks)
tests.order_test (SelectExecutor): Running binary search on index range for part 202011_728_728_0 (84 marks)
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found continuous range in 3 steps
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Running binary search on index range for part 202011_722_722_0 (128 marks)
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 7612
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 37
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found continuous range in 11 steps
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 1403
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 84
tests.order_test (SelectExecutor): Found continuous range in 25 steps
tests.order_test (SelectExecutor): Running binary search on index range for part 202011_370_686_19 (5993 marks)
tests.order_test (SelectExecutor): Found continuous range in 21 steps
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 128
tests.order_test (SelectExecutor): Found continuous range in 13 steps
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found continuous range in 14 steps
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 128
tests.order_test (SelectExecutor): Found (LEFT) boundary mark: 0
tests.order_test (SelectExecutor): Found continuous range in 14 steps
tests.order_test (SelectExecutor): Found (RIGHT) boundary mark: 5993
tests.order_test (SelectExecutor): Found continuous range in 25 steps
tests.order_test (SelectExecutor): Selected 8/9 parts by partition key, 8 parts by primary key, 15380/15380 marks by primary key, 15380 marks to read from 8 ranges
tests.order_test (SelectExecutor): MergingSortedTransform: Merge sorted 1947 blocks, 125972070 rows in 1.423973879 sec., 88465155.05499662 rows/sec., 423.78 MiB/sec
Ok.
0 rows in set. Elapsed: 1.424 sec. Processed 125.97 million rows, 629.86 MB (88.46 million rows/s., 442.28 MB/s.)
Things to consider:
The size of partitions you can check in system.parts table.
Examples:
-- for time-series:
PARTITION BY toYear(timestamp) -- long retention, not too much data
PARTITION BY toYYYYMM(timestamp) --
PARTITION BY toMonday(timestamp) --
PARTITION BY toDate(timestamp) --
PARTITION BY toStartOfHour(timestamp) -- short retention, lot of data
-- for table with some incremental (non time-bounded) counter
PARTITION BY intDiv(transaction_id, 1000000)
-- for some dimention tables (always requested with WHERE userid)
PARTITION BY userid % 16
For the small tables (smaller than few gigabytes) partitioning is usually not needed at all (just skip PARTITION BY expression when you create the table).
Q. What happens with columns which are not part of the ORDER BY key, nor have the AggregateFunction type?
A. it picks the first value met, (similar to any)
CREATE TABLE agg_test
(
`a` String,
`b` UInt8,
`c` SimpleAggregateFunction(max, UInt8)
)
ENGINE = AggregatingMergeTree
ORDER BY a;
INSERT INTO agg_test VALUES ('a', 1, 1);
INSERT INTO agg_test VALUES ('a', 2, 2);
SELECT * FROM agg_test FINAL;
┌─a─┬─b─┬─c─┐
│ a │ 1 │ 2 │
└───┴───┴───┘
INSERT INTO agg_test VALUES ('a', 3, 3);
SELECT * FROM agg_test;
┌─a─┬─b─┬─c─┐
│ a │ 1 │ 2 │
└───┴───┴───┘
┌─a─┬─b─┬─c─┐
│ a │ 3 │ 3 │
└───┴───┴───┘
OPTIMIZE TABLE agg_test FINAL;
SELECT * FROM agg_test;
┌─a─┬─b─┬─c─┐
│ a │ 1 │ 3 │
└───┴───┴───┘
CREATE TABLE test_last
(
`col1` Int32,
`col2` SimpleAggregateFunction(anyLast, Nullable(DateTime)),
`col3` SimpleAggregateFunction(anyLast, Nullable(DateTime))
)
ENGINE = AggregatingMergeTree
ORDER BY col1
Ok.
0 rows in set. Elapsed: 0.003 sec.
INSERT INTO test_last (col1, col2) VALUES (1, now());
Ok.
1 rows in set. Elapsed: 0.014 sec.
INSERT INTO test_last (col1, col3) VALUES (1, now())
Ok.
1 rows in set. Elapsed: 0.006 sec.
SELECT
col1,
anyLast(col2),
anyLast(col3)
FROM test_last
GROUP BY col1
┌─col1─┬───────anyLast(col2)─┬───────anyLast(col3)─┐
│ 1 │ 2020-01-16 20:57:46 │ 2020-01-16 20:57:51 │
└──────┴─────────────────────┴─────────────────────┘
1 rows in set. Elapsed: 0.005 sec.
SELECT *
FROM test_last
FINAL
┌─col1─┬────────────────col2─┬────────────────col3─┐
│ 1 │ 2020-01-16 20:57:46 │ 2020-01-16 20:57:51 │
└──────┴─────────────────────┴─────────────────────┘
1 rows in set. Elapsed: 0.003 sec.
Q. I have 2 Kafka topics from which I am storing events into 2 different tables (A and B) having the same unique ID. I want to create a single table that combines the data in tables A and B into one table C. The problem is that data is received asynchronously and not all the data is available when a row arrives in Table A or vice-versa.
A. You can use AggregatingMergeTree with Nullable columns and any aggregation function or Non-Nullable column and max aggregation function if it is acceptable for your data.
CREATE TABLE table_C (
id Int64,
colA SimpleAggregatingFunction(any,Nullable(UInt32)),
colB SimpleAggregatingFunction(max, String)
) ENGINE = AggregatingMergeTree()
ORDER BY id;
CREATE MATERIALIZED VIEW mv_A TO table_C AS
SELECT id,colA FROM Kafka_A;
CREATE MATERIALIZED VIEW mv_B TO table_C AS
SELECT id,colB FROM Kafka_B;
Here is a more complicated example (from here https://gist.github.com/den-crane/d03524eadbbce0bafa528101afa8f794 )
CREATE TABLE states_raw(
d date,
uid UInt64,
first_name String,
last_name String,
modification_timestamp_mcs DateTime64(3) default now64(3)
) ENGINE = Null;
CREATE TABLE final_states_by_month(
d date,
uid UInt64,
final_first_name AggregateFunction(argMax, String, DateTime64(3)),
final_last_name AggregateFunction(argMax, String, DateTime64(3)))
ENGINE = AggregatingMergeTree
PARTITION BY toYYYYMM(d)
ORDER BY (uid, d);
CREATE MATERIALIZED VIEW final_states_by_month_mv TO final_states_by_month AS
SELECT
d, uid,
argMaxState(first_name, if(first_name<>'', modification_timestamp_mcs, toDateTime64(0,3))) AS final_first_name,
argMaxState(last_name, if(last_name<>'', modification_timestamp_mcs, toDateTime64(0,3))) AS final_last_name
FROM states_raw
GROUP BY d, uid;
insert into states_raw(d,uid,first_name) values (today(), 1, 'Tom');
insert into states_raw(d,uid,last_name) values (today(), 1, 'Jones');
insert into states_raw(d,uid,first_name,last_name) values (today(), 2, 'XXX', '');
insert into states_raw(d,uid,first_name,last_name) values (today(), 2, 'YYY', 'YYY');
select uid, argMaxMerge(final_first_name) first_name, argMaxMerge(final_last_name) last_name
from final_states_by_month group by uid
┌─uid─┬─first_name─┬─last_name─┐
│ 2 │ YYY │ YYY │
│ 1 │ Tom │ Jones │
└─────┴────────────┴───────────┘
optimize table final_states_by_month final;
select uid, finalizeAggregation(final_first_name) first_name, finalizeAggregation(final_last_name) last_name
from final_states_by_month
┌─uid─┬─first_name─┬─last_name─┐
│ 1 │ Tom │ Jones │
│ 2 │ YYY │ YYY │
└─────┴────────────┴───────────┘
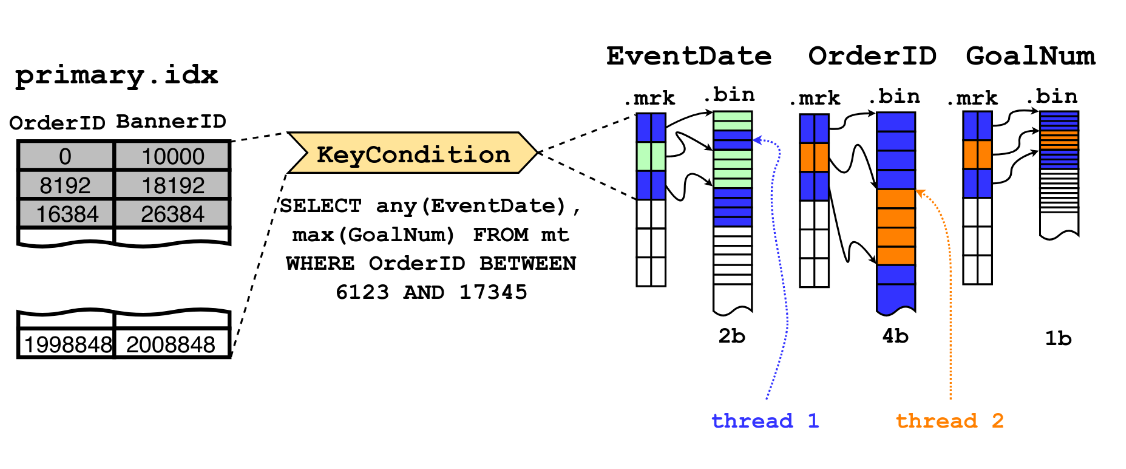
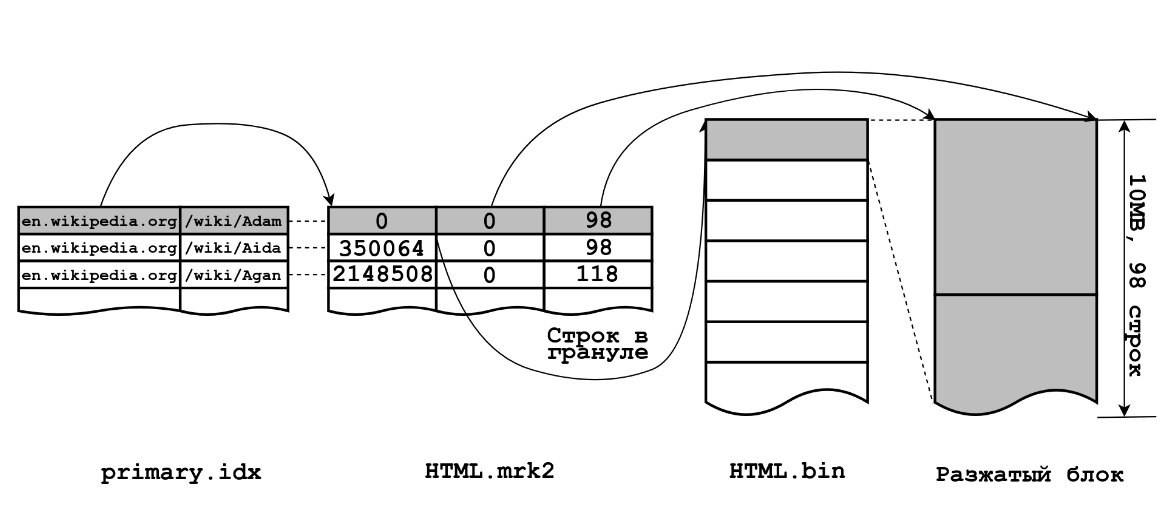
Main things affecting the merge speed are:
SELECT name, value
FROM system.merge_tree_settings
WHERE name LIKE '%vert%';
│ enable_vertical_merge_algorithm │ 1
│ vertical_merge_algorithm_min_rows_to_activate │ 131072
│ vertical_merge_algorithm_min_columns_to_activate │ 11
-- Disable Vertical Merges
ALTER TABLE test MODIFY SETTING enable_vertical_merge_algorithm = 0
When using
deduplicate
feature in OPTIMIZE FINAL, the question is which row will remain and won’t be deduped?
For SELECT operations ClickHouse® does not guarantee the order of the resultset unless you specify ORDER BY. This random ordering is affected by different parameters, like for example max_threads.
In a merge operation ClickHouse reads rows sequentially in storage order, which is determined by ORDER BY specified in CREATE TABLE statement, and only the first unique row in that order survives deduplication. So it is a bit different from how SELECT actually works. As FINAL clause is used then ClickHouse will merge all rows across all partitions (If it is not specified then the merge operation will be done per partition), and so the first unique row of the first partition will survive deduplication. Merges are single-threaded because it is too complicated to apply merge ops in-parallel, and it generally makes no sense.
CREATE TABLE x
(
`a` Nullable(UInt32),
`b` Nullable(UInt32),
`cnt` UInt32
)
ENGINE = SummingMergeTree
ORDER BY (a, b)
SETTINGS allow_nullable_key = 1;
INSERT INTO x VALUES (Null,2,1), (Null,Null,1), (3, Null, 1), (4,4,1);
INSERT INTO x VALUES (Null,2,1), (Null,Null,1), (3, Null, 1), (4,4,1);
SELECT * FROM x;
┌────a─┬────b─┬─cnt─┐
│ 3 │ null │ 2 │
│ 4 │ 4 │ 2 │
│ null │ 2 │ 2 │
│ null │ null │ 2 │
└──────┴──────┴─────┘
ReplacingMergeTree is a powerful ClickHouse® MergeTree engine. It is one of the techniques that can be used to guarantee unicity or exactly once delivery in ClickHouse.
Engine = ReplacingMergeTree([version_column],[is_deleted_column])
ORDER BY <list_of_columns>
INSERT INTO t values(..)SELECT FROM t finalINSERT INTO t(..., _version) values (...), insert with incremented versionINSERT INTO t(..., _version, is_deleted) values(..., 1)ClickHouse does not guarantee that merge will fire and replace rows using ReplacingMergeTree logic. FINAL keyword should be used in order to apply merge in a query time. It works reasonably fast when PK filter is used, but maybe slow for SELECT * type of queries:
See these links for reference:
Since 23.2, profile level final=1 can force final automatically, see https://github.com/ClickHouse/ClickHouse/pull/40945
ClickHouse merge parts only in scope of single partition, so if two rows with the same replacing key would land in different partitions, they would never be merged in single row. FINAL keyword works in other way, it merge all rows across all partitions. But that behavior can be changed viado_not_merge_across_partitions_select_final setting.
CREATE TABLE repl_tbl_part
(
`key` UInt32,
`value` UInt32,
`part_key` UInt32
)
ENGINE = ReplacingMergeTree
PARTITION BY part_key
ORDER BY key;
INSERT INTO repl_tbl_part SELECT
1 AS key,
number AS value,
number % 2 AS part_key
FROM numbers(4)
SETTINGS optimize_on_insert = 0;
SELECT * FROM repl_tbl_part;
┌─key─┬─value─┬─part_key─┐
│ 1 │ 1 │ 1 │
│ 1 │ 3 │ 1 │
└─────┴───────┴──────────┘
┌─key─┬─value─┬─part_key─┐
│ 1 │ 0 │ 0 │
│ 1 │ 2 │ 0 │
└─────┴───────┴──────────┘
SELECT * FROM repl_tbl_part FINAL;
┌─key─┬─value─┬─part_key─┐
│ 1 │ 3 │ 1 │
└─────┴───────┴──────────┘
SELECT * FROM repl_tbl_part FINAL SETTINGS do_not_merge_across_partitions_select_final=1;
┌─key─┬─value─┬─part_key─┐
│ 1 │ 3 │ 1 │
└─────┴───────┴──────────┘
┌─key─┬─value─┬─part_key─┐
│ 1 │ 2 │ 0 │
└─────┴───────┴──────────┘
OPTIMIZE TABLE repl_tbl_part FINAL;
SELECT * FROM repl_tbl_part;
┌─key─┬─value─┬─part_key─┐
│ 1 │ 3 │ 1 │
└─────┴───────┴──────────┘
┌─key─┬─value─┬─part_key─┐
│ 1 │ 2 │ 0 │
└─────┴───────┴──────────┘
ALTER TABLE t DELETE WHERE ... in PARTITION 'partition' – slow and asynchronous, rebuilds the partitionSELECT ... WHERE is_deleted = 0CREATE ROW POLICY delete_masking on t using is_deleted = 0 for ALL;ReplacingMergeTree(version, is_deleted) ORDER BY .. SETTINGS clean_deleted_rows='Always' (see https://github.com/ClickHouse/ClickHouse/pull/41005
)Other options:
ALTER TABLE t DROP PARTITION 'partition' – locks the table, drops full partition onlyDELETE FROM t WHERE ... – experimentalTested on ClickHouse 23.6 version FINAL is good in all cases
CREATE TABLE repl_tbl
(
`key` UInt32,
`val_1` UInt32,
`val_2` String,
`val_3` String,
`val_4` String,
`val_5` UUID,
`ts` DateTime
)
ENGINE = ReplacingMergeTree(ts)
ORDER BY key
SYSTEM STOP MERGES repl_tbl;
INSERT INTO repl_tbl SELECT number as key, rand() as val_1, randomStringUTF8(10) as val_2, randomStringUTF8(5) as val_3, randomStringUTF8(4) as val_4, generateUUIDv4() as val_5, now() as ts FROM numbers(10000000);
INSERT INTO repl_tbl SELECT number as key, rand() as val_1, randomStringUTF8(10) as val_2, randomStringUTF8(5) as val_3, randomStringUTF8(4) as val_4, generateUUIDv4() as val_5, now() as ts FROM numbers(10000000);
INSERT INTO repl_tbl SELECT number as key, rand() as val_1, randomStringUTF8(10) as val_2, randomStringUTF8(5) as val_3, randomStringUTF8(4) as val_4, generateUUIDv4() as val_5, now() as ts FROM numbers(10000000);
INSERT INTO repl_tbl SELECT number as key, rand() as val_1, randomStringUTF8(10) as val_2, randomStringUTF8(5) as val_3, randomStringUTF8(4) as val_4, generateUUIDv4() as val_5, now() as ts FROM numbers(10000000);
SELECT count() FROM repl_tbl
┌──count()─┐
│ 40000000 │
└──────────┘
-- GROUP BY
SELECT key, argMax(val_1, ts) as val_1, argMax(val_2, ts) as val_2, argMax(val_3, ts) as val_3, argMax(val_4, ts) as val_4, argMax(val_5, ts) as val_5, max(ts) FROM repl_tbl WHERE key = 10 GROUP BY key;
1 row in set. Elapsed: 0.008 sec.
-- ORDER BY LIMIT BY
SELECT * FROM repl_tbl WHERE key = 10 ORDER BY ts DESC LIMIT 1 BY key ;
1 row in set. Elapsed: 0.006 sec.
-- Subquery
SELECT * FROM repl_tbl WHERE key = 10 AND ts = (SELECT max(ts) FROM repl_tbl WHERE key = 10);
1 row in set. Elapsed: 0.009 sec.
-- FINAL
SELECT * FROM repl_tbl FINAL WHERE key = 10;
1 row in set. Elapsed: 0.008 sec.
-- GROUP BY
SELECT key, argMax(val_1, ts) as val_1, argMax(val_2, ts) as val_2, argMax(val_3, ts) as val_3, argMax(val_4, ts) as val_4, argMax(val_5, ts) as val_5, max(ts) FROM repl_tbl WHERE key IN (SELECT toUInt32(number) FROM numbers(1000000) WHERE number % 100) GROUP BY key FORMAT Null;
Peak memory usage (for query): 2.19 GiB.
0 rows in set. Elapsed: 1.043 sec. Processed 5.08 million rows, 524.38 MB (4.87 million rows/s., 502.64 MB/s.)
-- SET optimize_aggregation_in_order=1;
Peak memory usage (for query): 349.94 MiB.
0 rows in set. Elapsed: 0.901 sec. Processed 4.94 million rows, 506.55 MB (5.48 million rows/s., 562.17 MB/s.)
-- ORDER BY LIMIT BY
SELECT * FROM repl_tbl WHERE key IN (SELECT toUInt32(number) FROM numbers(1000000) WHERE number % 100) ORDER BY ts DESC LIMIT 1 BY key FORMAT Null;
Peak memory usage (for query): 1.12 GiB.
0 rows in set. Elapsed: 1.171 sec. Processed 5.08 million rows, 524.38 MB (4.34 million rows/s., 447.95 MB/s.)
-- Subquery
SELECT * FROM repl_tbl WHERE (key, ts) IN (SELECT key, max(ts) FROM repl_tbl WHERE key IN (SELECT toUInt32(number) FROM numbers(1000000) WHERE number % 100) GROUP BY key) FORMAT Null;
Peak memory usage (for query): 197.30 MiB.
0 rows in set. Elapsed: 0.484 sec. Processed 8.72 million rows, 507.33 MB (18.04 million rows/s., 1.05 GB/s.)
-- SET optimize_aggregation_in_order=1;
Peak memory usage (for query): 171.93 MiB.
0 rows in set. Elapsed: 0.465 sec. Processed 8.59 million rows, 490.55 MB (18.46 million rows/s., 1.05 GB/s.)
-- FINAL
SELECT * FROM repl_tbl FINAL WHERE key IN (SELECT toUInt32(number) FROM numbers(1000000) WHERE number % 100) FORMAT Null;
Peak memory usage (for query): 537.13 MiB.
0 rows in set. Elapsed: 0.357 sec. Processed 4.39 million rows, 436.28 MB (12.28 million rows/s., 1.22 GB/s.)
-- GROUP BY
SELECT key, argMax(val_1, ts) as val_1, argMax(val_2, ts) as val_2, argMax(val_3, ts) as val_3, argMax(val_4, ts) as val_4, argMax(val_5, ts) as val_5, max(ts) FROM repl_tbl GROUP BY key FORMAT Null;
Peak memory usage (for query): 16.08 GiB.
0 rows in set. Elapsed: 11.600 sec. Processed 40.00 million rows, 5.12 GB (3.45 million rows/s., 441.49 MB/s.)
-- SET optimize_aggregation_in_order=1;
Peak memory usage (for query): 865.76 MiB.
0 rows in set. Elapsed: 9.677 sec. Processed 39.82 million rows, 5.10 GB (4.12 million rows/s., 526.89 MB/s.)
-- ORDER BY LIMIT BY
SELECT * FROM repl_tbl ORDER BY ts DESC LIMIT 1 BY key FORMAT Null;
Peak memory usage (for query): 8.39 GiB.
0 rows in set. Elapsed: 14.489 sec. Processed 40.00 million rows, 5.12 GB (2.76 million rows/s., 353.45 MB/s.)
-- Subquery
SELECT * FROM repl_tbl WHERE (key, ts) IN (SELECT key, max(ts) FROM repl_tbl GROUP BY key) FORMAT Null;
Peak memory usage (for query): 2.40 GiB.
0 rows in set. Elapsed: 5.225 sec. Processed 79.65 million rows, 5.40 GB (15.24 million rows/s., 1.03 GB/s.)
-- SET optimize_aggregation_in_order=1;
Peak memory usage (for query): 924.39 MiB.
0 rows in set. Elapsed: 4.126 sec. Processed 79.67 million rows, 5.40 GB (19.31 million rows/s., 1.31 GB/s.)
-- FINAL
SELECT * FROM repl_tbl FINAL FORMAT Null;
Peak memory usage (for query): 834.09 MiB.
0 rows in set. Elapsed: 2.314 sec. Processed 38.80 million rows, 4.97 GB (16.77 million rows/s., 2.15 GB/s.)
Hi there, I have a question about replacing merge trees. I have set up a Materialized View with ReplacingMergeTree table, but even if I call optimize on it, the parts don’t get merged. I filled that table yesterday, nothing happened since then. What should I do?
Merges are eventual and may never happen. It depends on the number of inserts that happened after, the number of parts in the partition, size of parts. If the total size of input parts are greater than the maximum part size then they will never be merged.
https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/replacingmergetree ReplacingMergeTree is suitable for clearing out duplicate data in the background in order to save space, but it doesn’t guarantee the absence of duplicates.
When you are creating skip indexes
in non-regular (Replicated)MergeTree tables over non ORDER BY columns. ClickHouse® applies index condition on the first step of query execution, so it’s possible to get outdated rows.
--(1) create test table
drop table if exists test;
create table test
(
version UInt32
,id UInt32
,state UInt8
,INDEX state_idx (state) type set(0) GRANULARITY 1
) ENGINE ReplacingMergeTree(version)
ORDER BY (id);
--(2) insert sample data
INSERT INTO test (version, id, state) VALUES (1,1,1);
INSERT INTO test (version, id, state) VALUES (2,1,0);
INSERT INTO test (version, id, state) VALUES (3,1,1);
--(3) check the result:
-- expected 3, 1, 1
select version, id, state from test final;
┌─version─┬─id─┬─state─┐
│ 3 │ 1 │ 1 │
└─────────┴────┴───────┘
-- expected empty result
select version, id, state from test final where state=0;
┌─version─┬─id─┬─state─┐
│ 2 │ 1 │ 0 │
└─────────┴────┴───────┘
In certain conditions it could make sense to collapse one of dimensions to set of arrays. It’s usually profitable to do if this dimension is not commonly used in queries. It would reduce amount of rows in aggregated table and speed up queries which doesn’t care about this dimension in exchange of aggregation performance by collapsed dimension.
CREATE TABLE traffic
(
`key1` UInt32,
`key2` UInt32,
`port` UInt16,
`bits_in` UInt32 CODEC (T64,LZ4),
`bits_out` UInt32 CODEC (T64,LZ4),
`packets_in` UInt32 CODEC (T64,LZ4),
`packets_out` UInt32 CODEC (T64,LZ4)
)
ENGINE = SummingMergeTree
ORDER BY (key1, key2, port);
INSERT INTO traffic SELECT
number % 1000,
intDiv(number, 10000),
rand() % 20,
rand() % 753,
rand64() % 800,
rand() % 140,
rand64() % 231
FROM numbers(100000000);
CREATE TABLE default.traffic_map
(
`key1` UInt32,
`key2` UInt32,
`bits_in` UInt32 CODEC(T64, LZ4),
`bits_out` UInt32 CODEC(T64, LZ4),
`packets_in` UInt32 CODEC(T64, LZ4),
`packets_out` UInt32 CODEC(T64, LZ4),
`portMap.port` Array(UInt16),
`portMap.bits_in` Array(UInt32) CODEC(T64, LZ4),
`portMap.bits_out` Array(UInt32) CODEC(T64, LZ4),
`portMap.packets_in` Array(UInt32) CODEC(T64, LZ4),
`portMap.packets_out` Array(UInt32) CODEC(T64, LZ4)
)
ENGINE = SummingMergeTree
ORDER BY (key1, key2);
INSERT INTO traffic_map WITH rand() % 20 AS port
SELECT
number % 1000 AS key1,
intDiv(number, 10000) AS key2,
rand() % 753 AS bits_in,
rand64() % 800 AS bits_out,
rand() % 140 AS packets_in,
rand64() % 231 AS packets_out,
[port],
[bits_in],
[bits_out],
[packets_in],
[packets_out]
FROM numbers(100000000);
┌─table───────┬─column──────────────┬─────rows─┬─compressed─┬─uncompressed─┬──ratio─┐
│ traffic │ bits_out │ 80252317 │ 109.09 MiB │ 306.14 MiB │ 2.81 │
│ traffic │ bits_in │ 80252317 │ 108.34 MiB │ 306.14 MiB │ 2.83 │
│ traffic │ port │ 80252317 │ 99.21 MiB │ 153.07 MiB │ 1.54 │
│ traffic │ packets_out │ 80252317 │ 91.36 MiB │ 306.14 MiB │ 3.35 │
│ traffic │ packets_in │ 80252317 │ 84.61 MiB │ 306.14 MiB │ 3.62 │
│ traffic │ key2 │ 80252317 │ 47.88 MiB │ 306.14 MiB │ 6.39 │
│ traffic │ key1 │ 80252317 │ 1.38 MiB │ 306.14 MiB │ 221.42 │
│ traffic_map │ portMap.bits_out │ 10000000 │ 108.96 MiB │ 306.13 MiB │ 2.81 │
│ traffic_map │ portMap.bits_in │ 10000000 │ 108.32 MiB │ 306.13 MiB │ 2.83 │
│ traffic_map │ portMap.port │ 10000000 │ 92.00 MiB │ 229.36 MiB │ 2.49 │
│ traffic_map │ portMap.packets_out │ 10000000 │ 90.95 MiB │ 306.13 MiB │ 3.37 │
│ traffic_map │ portMap.packets_in │ 10000000 │ 84.19 MiB │ 306.13 MiB │ 3.64 │
│ traffic_map │ key2 │ 10000000 │ 23.46 MiB │ 38.15 MiB │ 1.63 │
│ traffic_map │ bits_in │ 10000000 │ 15.59 MiB │ 38.15 MiB │ 2.45 │
│ traffic_map │ bits_out │ 10000000 │ 15.59 MiB │ 38.15 MiB │ 2.45 │
│ traffic_map │ packets_out │ 10000000 │ 13.22 MiB │ 38.15 MiB │ 2.89 │
│ traffic_map │ packets_in │ 10000000 │ 12.62 MiB │ 38.15 MiB │ 3.02 │
│ traffic_map │ key1 │ 10000000 │ 180.29 KiB │ 38.15 MiB │ 216.66 │
└─────────────┴─────────────────────┴──────────┴────────────┴──────────────┴────────┘
-- Queries
SELECT
key1,
sum(packets_in),
sum(bits_out)
FROM traffic
GROUP BY key1
FORMAT `Null`
0 rows in set. Elapsed: 0.488 sec. Processed 80.25 million rows, 963.03 MB (164.31 million rows/s., 1.97 GB/s.)
SELECT
key1,
sum(packets_in),
sum(bits_out)
FROM traffic_map
GROUP BY key1
FORMAT `Null`
0 rows in set. Elapsed: 0.063 sec. Processed 10.00 million rows, 120.00 MB (159.43 million rows/s., 1.91 GB/s.)
SELECT
key1,
port,
sum(packets_in),
sum(bits_out)
FROM traffic
GROUP BY
key1,
port
FORMAT `Null`
0 rows in set. Elapsed: 0.668 sec. Processed 80.25 million rows, 1.12 GB (120.14 million rows/s., 1.68 GB/s.)
WITH arrayJoin(arrayZip(untuple(sumMap(portMap.port, portMap.packets_in, portMap.bits_out)))) AS tpl
SELECT
key1,
tpl.1 AS port,
tpl.2 AS packets_in,
tpl.3 AS bits_out
FROM traffic_map
GROUP BY key1
FORMAT `Null`
0 rows in set. Elapsed: 0.915 sec. Processed 10.00 million rows, 1.08 GB (10.93 million rows/s., 1.18 GB/s.)
When you have an incoming event stream with duplicates, updates, and deletes, building a consistent row state inside the ClickHouse® table is a big challenge.
The UPDATE/DELETE approach in the OLTP world won’t help with OLAP databases tuned to handle big batches. UPDATE/DELETE operations in ClickHouse are executed as “mutations,” rewriting a lot of data and being relatively slow. You can’t run such operations very often, as for OLTP databases. But the UPSERT operation (insert and replace) runs fast with the ReplacingMergeTree Engine. It’s even set as the default mode for INSERT without any special keyword. We can emulate UPDATE (or even DELETE) with the UPSERT operation.
There are a lot of blog posts on how to use ReplacingMergeTree Engine to handle mutated data streams. A properly designed table schema with ReplacingMergeTree Engine is a good instrument for building the DWH Dimensions table. But when maintaining metrics in Fact tables, there are several problems:
-- multiple partitions problem
CREATE TABLE RMT
(
`key` Int64,
`someCol` String,
`eventTime` DateTime
)
ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(eventTime)
ORDER BY key;
INSERT INTO RMT Values (1, 'first', '2024-04-25T10:16:21');
INSERT INTO RMT Values (1, 'second', '2024-05-02T08:36:59');
with merged as (select * from RMT FINAL)
select * from merged
where eventTime < '2024-05-01'
You will get a row with ‘first’, not an empty set, as one might expect with the FINAL processing of a whole table.
ClickHouse has other table engines, such as CollapsingMergeTree and VersionedCollapsingMergeTree, that can be used even better for UPSERT operation.
Both work by inserting a “rollback row” to compensate for the previous insert. The difference between CollapsingMergeTree and VersionedCollapsingMergeTree is in the algorithm of collapsing. For Cluster configurations, it’s essential to understand which row came first and who should replace whom. That is why using ReplicatedVersionedCollapsingMergeTree is mandatory for Replicated Clusters.
When dealing with such complicated data streams, it needs to be solved 3 tasks simultaneously:
It’s essential to understand how the collapsing algorithm of VersionedCollapsingMergeTree works. Quote from the documentation :
When ClickHouse merges data parts, it deletes each pair of rows that have the same primary key and version and different Sign. The order of rows does not matter.
The version column should increase over time. You may use a natural timestamp for that. Random-generated IDs are not suitable for the version column.
Let’s first fix the problem with mutated data in a different partition.
CREATE TABLE VCMT
(
key Int64,
someCol String,
eventTime DateTime,
sign Int8
)
ENGINE = VersionedCollapsingMergeTree(sign,eventTime)
PARTITION BY toYYYYMM(eventTime)
ORDER BY key;
INSERT INTO VCMT Values (1, 'first', '2024-04-25 10:16:21',1);
INSERT INTO VCMT Values (1, 'first', '2024-04-25 10:16:21',-1), (1, 'second', '2024-05-02 08:36:59',1);
set do_not_merge_across_partitions_select_final=1; -- for fast FINAL
select 'no rows after:';
with merged as
(select * from VCMT FINAL)
select * from merged
where eventTime < '2024-05-01';
With VersionedCollapsingMergeTree, we can use more partition strategies, even with columns not tied to the row’s primary key. This could facilitate the creation of faster queries, more convenient TTLs (Time-To-Live), and backups.
There are several ways to remove duplicates from the event stream. The most effective feature is block deduplication, which occurs when ClickHouse drops incoming blocks with the same checksum (or tag). However, this requires building a smart ingestor capable of saving positions in a transactional manner.
However, another method is possible: verifying whether a particular row already exists in the destination table to avoid redundant insertions. Together with block deduplication, that method also avoids using ReplacingMergeTree and FINAL during query time.
Ensuring accuracy and consistency in results requires executing this process on a single thread within one cluster node. This method is particularly suitable for less active event streams, such as those with up to 100,000 events per second. To boost performance, incoming streams should be segmented into several partitions (or ‘shards’) based on the table/event’s Primary Key, with each partition processed on a single thread.
An example of row deduplication:
create table Example1 (id Int64, metric UInt64)
engine = MergeTree order by id;
create table Example1Null engine = Null as Example1;
create materialized view __Example1 to Example1 as
select * from Example1Null
where id not in (
select id from Example1 where id in (
select id from Example1Null
)
);
Here is the trick:
In most cases, the insert block does not have too many rows (like 1000-100k), so checking the destination table for their existence by scanning the Primary Key (residing in memory) won’t take much time. However, due to the high table index granularity, it can still be noticeable on high load. To enhance performance, consider reducing index granularity to 4096 (from the default 8192) or even fewer values.
To process updates in CollapsingMergeTree, the ’last row state’ must be known before inserting the ‘compensation row.’ Sometimes, this is possible - CDC events coming from MySQL’s binlog or Postgres’s WAL contain not only ’new’ data but also ‘old’ values. If one of the columns includes a sequence-generated version or timestamp of the row’s update time, it can be used as the row’s ‘version’ for VersionedCollapsingMergeTree. When the incoming event stream lacks old metric values and suitable version information, we can retrieve that data by examining the ClickHouse table using the same method used for row deduplication in the previous example.
create table Example2 (id Int64, metric UInt64, sign Int8)
engine = CollapsingMergeTree(sign) order by id;
create table Example2Null engine = Null as Example2;
create materialized view __Example2 to Example2 as
with _old as (
select *, arrayJoin([-1,1]) as _sign
from Example2 where id in (select id from Example2Null)
)
select id,
if(_old._sign=-1, _old.metric, _new.metric) as metric
from Example2Null as _new
join _old using id;
I read more data from the Example2 table than from Example1. Instead of simply checking the row existence by the IN operator, a JOIN with existing rows is used to build a “compensate row.”
For UPSERT, the collapsing algorithm requires inserting two rows. So, I need to create two rows from any row that is found in the local table. It´s an essential part of the suggested approach, which allows me to produce proper rows for inserting with a human-readable code with clear if() statements. That is why I execute arrayJoin while reading old data.
Don’t try to run the code above. It’s just a short explanation of the idea, lacking many needed elements.
Here is a more realistic example with more checks that can be played with:
create table Example3
(
id Int32,
metric1 UInt32,
metric2 UInt32,
_version UInt64,
sign Int8 default 1
) engine = VersionedCollapsingMergeTree(sign, _version)
ORDER BY id
;
create table Stage engine=Null as Example3 ;
create materialized view Example3Transform to Example3 as
with __new as ( SELECT * FROM Stage order by _version desc, sign desc limit 1 by id ),
__old AS ( SELECT *, arrayJoin([-1,1]) AS _sign from
( select * FROM Example3 final
PREWHERE id IN (SELECT id FROM __new)
where sign = 1
)
)
select id,
if(__old._sign = -1, __old.metric1, __new.metric1) AS metric1,
if(__old._sign = -1, __old.metric2, __new.metric2) AS metric2,
if(__old._sign = -1, __old._version, __new._version) AS _version,
if(__old._sign = -1, -1, 1) AS sign
from __new left join __old
using id
where if(__new.sign=-1,
__old._sign = -1, -- insert only delete row if it's found in old data
__new._version > __old._version -- skip duplicates for updates
);
-- original
insert into Stage values (1,1,1,1,1), (2,2,2,1,1);
select 'step1',* from Example3 ;
-- no duplicates (with the same version) inserted
insert into Stage values (1,3,1,1,1),(2,3,2,1,1);
select 'step2',* from Example3 ;
-- delete a row with id=2. version for delete row does not have any meaning
insert into Stage values (2,2,2,0,-1);
select 'step3',* from Example3 final;
-- replace a row with id=1. row with sign=-1 not needed, but can be in the insert blocks (will be skipped)
insert into Stage values (1,1,1,0,-1),(1,3,3,2,1);
select 'step4',* from Example3 final;
Important additions:
set allow_experimental_analyzer=0;
create table Example3
(
id Int32,
Department String,
metric1 UInt32,
metric2 Float32,
_version UInt64,
sign Int8 default 1
) engine = VersionedCollapsingMergeTree(sign, _version)
ORDER BY id
partition by (id % 20)
settings index_granularity=4096
;
set do_not_merge_across_partitions_select_final=1;
-- make 100M table
INSERT INTO Example3
SELECT
number AS id,
['HR', 'Finance', 'Engineering', 'Sales', 'Marketing'][rand() % 5 + 1] AS Department,
rand() % 1000 AS metric1,
(rand() % 10000) / 100.0 AS metric2,
0 AS _version,
1 AS sign
FROM numbers(1E8);
create function timeSpent as () ->
date_diff('millisecond',(select ts from t1),now64(3));
-- measure plain INSERT time for 1M batch
create temporary table t1 (ts DateTime64(3)) as select now64(3);
INSERT INTO Example3
SELECT
number AS id,
['HR', 'Finance', 'Engineering', 'Sales', 'Marketing'][rand() % 5 + 1] AS Department,
rand() % 1000 AS metric1,
(rand() % 10000) / 100.0 AS metric2,
1 AS _version,
1 AS sign
FROM numbers(1E6);
select '---',timeSpent(),'INSERT';
--create table Stage engine=MergeTree order by id as Example3 ;
create table Stage engine=Null as Example3 ;
create materialized view Example3Transform to Example3 as
with __new as ( SELECT * FROM Stage order by _version desc,sign desc limit 1 by id ),
__old AS ( SELECT *, arrayJoin([-1,1]) AS _sign from
( select * FROM Example3 final
PREWHERE id IN (SELECT id FROM __new)
where sign = 1
)
)
select id,
if(__old._sign = -1, __old.Department, __new.Department) AS
Department,
if(__old._sign = -1, __old.metric1, __new.metric1) AS metric1,
if(__old._sign = -1, __old.metric2, __new.metric2) AS metric2,
if(__old._sign = -1, __old._version, __new._version) AS _version,
if(__old._sign = -1, -1, 1) AS sign
from __new left join __old using id
where if(__new.sign=-1,
__old._sign = -1, -- insert only delete row if it's found in old data
__new._version > __old._version -- skip duplicates for updates
);
-- calculate UPSERT time for 1M batch
drop table t1;
create temporary table t1 (ts DateTime64(3)) as select now64(3);
INSERT INTO Stage
SELECT
(rand() % 1E6)*100 AS id,
--number AS id,
['HR', 'Finance', 'Engineering', 'Sales', 'Marketing'][rand() % 5 + 1] AS Department,
rand() % 1000 AS metric1,
(rand() % 10000) / 100.0 AS metric2,
2 AS _version,
1 AS sign
FROM numbers(1E6);
select '---',timeSpent(),'UPSERT';
-- FINAL query
drop table t1;
create temporary table t1 (ts DateTime64(3)) as select now64(3);
select Department, count(), sum(metric1) from Example3 FINAL
group by Department order by Department
format Null
;
select '---',timeSpent(),'FINAL';
-- GROUP BY query
drop table t1;
create temporary table t1 (ts DateTime64(3)) as select now64(3);
select Department, sum(sign), sum(sign*metric1) from Example3
group by Department order by Department
format Null
;
select '---',timeSpent(),'GROUP BY';
optimize table Example3 final;
-- FINAL query
drop table t1;
create temporary table t1 (ts DateTime64(3)) as select now64(3);
select Department, count(), sum(metric1) from Example3 FINAL
group by Department order by Department
format Null
;
select '---',timeSpent(),'FINAL OPTIMIZED';
-- GROUP BY query
drop table t1;
create temporary table t1 (ts DateTime64(3)) as select now64(3);
select Department, sum(sign), sum(sign*metric1) from Example3
group by Department order by Department
format Null
;
select '---',timeSpent(),'GROUP BY OPTIMIZED';
You can use fiddle or clickhouse-local to run such a test:
cat test.sql | clickhouse-local -nm
Results (Mac A2 Pro), milliseconds:
--- 252 INSERT
--- 1710 UPSERT
--- 763 FINAL
--- 311 GROUP BY
--- 314 FINAL OPTIMIZED
--- 295 GROUP BY OPTIMIZED
UPSERT is six times slower than direct INSERT because it requires looking up the destination table. That is the price. It is better to use idempotent inserts with an exactly-once delivery guarantee. However, it’s not always possible.
The FINAL speed is quite good, especially if we split the table by 20 partitions, use do_not_merge_across_partitions_select_final setting, and keep most of the table’s partitions optimized (1 part per partition). But we can do it better.
Let’s add an aggregating projection, and also add a more useful updated_at timestamp instead of an abstract _version and replace String for Department dimension by LowCardinality(String). Let’s look at the difference in time execution.
https://fiddle.clickhouse.com/3140d341-ccc5-4f57-8fbf-55dbf4883a21
set allow_experimental_analyzer=0;
create table Example4
(
id Int32,
Department LowCardinality(String),
metric1 Int32,
metric2 Float32,
_version DateTime64(3) default now64(3),
sign Int8 default 1
) engine = VersionedCollapsingMergeTree(sign, _version)
ORDER BY id
partition by (id % 20)
settings index_granularity=4096
;
set do_not_merge_across_partitions_select_final=1;
-- make 100M table
INSERT INTO Example4
SELECT
number AS id,
['HR', 'Finance', 'Engineering', 'Sales', 'Marketing'][rand() % 5 + 1] AS Department,
rand() % 1000 AS metric1,
(rand() % 10000) / 100.0 AS metric2,
0 AS _version,
1 AS sign
FROM numbers(1E8);
create temporary table timeMark (ts DateTime64(3));
create function timeSpent as () ->
date_diff('millisecond',(select max(ts) from timeMark),now64(3));
-- measure plain INSERT time for 1M batch
insert into timeMark select now64(3);
INSERT INTO Example4(id,Department,metric1,metric2)
SELECT
number AS id,
['HR', 'Finance', 'Engineering', 'Sales', 'Marketing'][rand() % 5 + 1] AS Department,
rand() % 1000 AS metric1,
(rand() % 10000) / 100.0 AS metric2
FROM numbers(1E6);
select '---',timeSpent(),'INSERT';
--create table Stage engine=MergeTree order by id as Example4 ;
create table Stage engine=Null as Example4 ;
create materialized view Example4Transform to Example4 as
with __new as ( SELECT * FROM Stage order by _version desc,sign desc limit 1 by id ),
__old AS ( SELECT *, arrayJoin([-1,1]) AS _sign from
( select * FROM Example4 final
PREWHERE id IN (SELECT id FROM __new)
where sign = 1
)
)
select id,
if(__old._sign = -1, __old.Department, __new.Department) AS
Department,
if(__old._sign = -1, __old.metric1, __new.metric1) AS metric1,
if(__old._sign = -1, __old.metric2, __new.metric2) AS metric2,
if(__old._sign = -1, __old._version, __new._version) AS _version,
if(__old._sign = -1, -1, 1) AS sign
from __new left join __old using id
where if(__new.sign=-1,
__old._sign = -1, -- insert only delete row if it's found in old data
__new._version > __old._version -- skip duplicates for updates
);
-- calculate UPSERT time for 1M batch
insert into timeMark select now64(3);
INSERT INTO Stage(id,Department,metric1,metric2)
SELECT
(rand() % 1E6)*100 AS id,
--number AS id,
['HR', 'Finance', 'Engineering', 'Sales', 'Marketing'][rand() % 5 + 1] AS Department,
rand() % 1000 AS metric1,
(rand() % 10000) / 100.0 AS metric2
FROM numbers(1E6);
select '---',timeSpent(),'UPSERT';
-- FINAL query
insert into timeMark select now64(3);
select Department, count(), sum(metric1) from Example4 FINAL
group by Department order by Department
format Null
;
select '---',timeSpent(),'FINAL';
-- GROUP BY query
insert into timeMark select now64(3);
select Department, sum(sign), sum(sign*metric1) from Example4
group by Department order by Department
format Null
;
select '---',timeSpent(),'GROUP BY';
--select '--parts1',partition, count() from system.parts where active and table='Example4' group by partition;
insert into timeMark select now64(3);
optimize table Example4 final;
select '---',timeSpent(),'OPTIMIZE';
-- FINAL OPTIMIZED
insert into timeMark select now64(3);
select Department, count(), sum(metric1) from Example4 FINAL
group by Department order by Department
format Null
;
select '---',timeSpent(),'FINAL OPTIMIZED';
-- GROUP BY OPTIMIZED
insert into timeMark select now64(3);
select Department, sum(sign), sum(sign*metric1) from Example4
group by Department order by Department
format Null
;
select '---',timeSpent(),'GROUP BY OPTIMIZED';
-- UPSERT a little data to create more parts
INSERT INTO Stage(id,Department,metric1,metric2)
SELECT
number AS id,
['HR', 'Finance', 'Engineering', 'Sales', 'Marketing'][rand() % 5 + 1] AS Department,
rand() % 1000 AS metric1,
(rand() % 10000) / 100.0 AS metric2
FROM numbers(1000);
--select '--parts2',partition, count() from system.parts where active and table='Example4' group by partition;
-- GROUP BY SEMI-OPTIMIZED
insert into timeMark select now64(3);
select Department, sum(sign), sum(sign*metric1) from Example4
group by Department order by Department
format Null
;
select '---',timeSpent(),'GROUP BY SEMI-OPTIMIZED';
--alter table Example4 add column Smetric1 Int32 alias metric1*sign;
alter table Example4 add projection byDep (select Department, sum(sign), sum(sign*metric1) group by Department);
-- Materialize Projection
insert into timeMark select now64(3);
alter table Example4 materialize projection byDep settings mutations_sync=1;
select '---',timeSpent(),'Materialize Projection';
-- GROUP BY query Projected
insert into timeMark select now64(3);
select Department, sum(sign), sum(sign*metric1) from Example4
group by Department order by Department
settings force_optimize_projection=1
format Null
;
select '---',timeSpent(),'GROUP BY Projected';
Results (Mac A2 Pro), milliseconds:
--- 175 INSERT
--- 1613 UPSERT
--- 329 FINAL
--- 102 GROUP BY
--- 10498 OPTIMIZE
--- 103 FINAL OPTIMIZED
--- 90 GROUP BY OPTIMIZED
--- 94 GROUP BY SEMI-OPTIMIZED
--- 919 Materialize Projection
--- 5 GROUP BY Projected
Some thoughts:
The typical CDC event for DWH systems besides INSERT is UPSERT—a new row replaces the old one (with suitable aggregate corrections). But DELETE events are also supported (ones with column sign=-1). The Materialized View described above will correctly process the DELETE event by inserting only 1 row with sign=-1 if a row with a particular ID already exists in the table. In such cases, VersionedCollapsingMergeTree will wipe both rows (with sign=1 & -1) during merge or final operations.
However, it can lead to incorrect duplicate processing in some rare situations. Here is the scenario:
The probability of such a sequence is relatively low, especially in normal operations when the amount of DELETEs is not too significant. Processing events in big batches will reduce the probability even more.
The presented technique can be used to reimplement the AggregatingMergeTree algorithm to combine old and new row data using VersionedCollapsingMergeTree.
https://fiddle.clickhouse.com/e1d7e04c-f1d6-4a25-9aac-1fe2b543c693
create table Example5
(
id Int32,
metric1 UInt32,
metric2 Nullable(UInt32),
updated_at DateTime64(3) default now64(3),
sign Int8 default 1
) engine = VersionedCollapsingMergeTree(sign, updated_at)
ORDER BY id
;
create table Stage engine=Null as Example5 ;
create materialized view Example5Transform to Example5 as
with __new as ( SELECT * FROM Stage order by sign desc, updated_at desc limit 1 by id ),
__old AS ( SELECT *, arrayJoin([-1,1]) AS _sign from
( select * FROM Example5 final
PREWHERE id IN (SELECT id FROM __new)
where sign = 1
)
)
select id,
if(__old._sign = -1, __old.metric1, greatest(__new.metric1, __old.metric1)) AS metric1,
if(__old._sign = -1, __old.metric2, ifNull(__new.metric2, __old.metric2)) AS metric2,
if(__old._sign = -1, __old.updated_at, __new.updated_at) AS updated_at,
if(__old._sign = -1, -1, 1) AS sign
from __new left join __old using id
where if(__new.sign=-1,
__old._sign = -1, -- insert only delete row if it's found in old data
__new.updated_at > __old.updated_at -- skip duplicates for updates
);
-- original
insert into Stage(id) values (1), (2);
select 'step0',* from Example5 ;
insert into Stage(id,metric1) values (1,1), (2,2);
select 'step1',* from Example5 final;
insert into Stage(id,metric2) values (1,11), (2,12);
select 'step2',* from Example5 final ;
I used a simple, compact column with Int64 type for the primary key in previous examples. It’s better to go this route with monotonically growing IDs like autoincrement ID or SnowFlakeId (based on timestamp). However, in some cases, a more complex primary key is needed. For instance, when storing data for multiple tenants (Customers, partners, etc.) in the same table. This is not a problem for the suggested technique - use all the necessary columns in all filters and JOIN operations as Tuple.
create table Example6
(
id Int64,
tenant_id Int32,
metric1 UInt32,
_version UInt64,
sign Int8 default 1
) engine = VersionedCollapsingMergeTree(sign, _version)
ORDER BY (tenant_id,id)
;
create table Stage engine=Null as Example6 ;
create materialized view Example6Transform to Example6 as
with __new as ( SELECT * FROM Stage order by sign desc, _version desc limit 1 by tenant_id,id ),
__old AS ( SELECT *, arrayJoin([-1,1]) AS _sign from
( select * FROM Example6 final
PREWHERE (tenant_id,id) IN (SELECT tenant_id,id FROM __new)
where sign = 1
)
)
select id,tenant_id,
if(__old._sign = -1, __old.metric1, __new.metric1) AS metric1,
if(__old._sign = -1, __old._version, __new._version) AS _version,
if(__old._sign = -1, -1, 1) AS sign
from __new left join __old
using (tenant_id,id)
where if(__new.sign=-1,
__old._sign = -1, -- insert only delete row if it's found in old data
__new._version > __old._version -- skip duplicates for updates
);
The suggested approach works well when inserting data in a single thread on a single replica. This is suitable for up to 1M events per second. However, for higher traffic, it’s necessary to use multiple ingesting threads across several replicas. In such cases, collisions caused by parts manipulation and replication delay can disrupt the entire Collapsing algorithm.
But inserting different shards with a sharding key derived from ID works fine. Every shard will operate with its own non-intersecting set of IDs, and don’t interfere with each other.
The same approach can be implemented when inserting several threads into the same replica node. For big installations with high traffic and many shards and replicas, the ingesting app can split the data stream into a considerably large number of “virtual shards” (or partitions in Kafka terminology) and then map the “virtual shards” to the threads doing inserts to “physical shards.”
The incoming stream could be split into several ones by using an expression like cityHash64(id) % 50 = 0 as a sharding key. The ingesting app should calculate the shard number before sending data to internal buffers that will be flushed to INSERTs.
-- emulate insert into distributed table
INSERT INTO function remote('localhos{t,t,t}',default,Stage,id)
SELECT
(rand() % 1E6)*100 AS id,
--number AS id,
['HR', 'Finance', 'Engineering', 'Sales', 'Marketing'][rand() % 5 + 1] AS Department,
rand() % 1000 AS metric1,
(rand() % 10000) / 100.0 AS metric2,
2 AS _version,
1 AS sign
FROM numbers(1000)
settings prefer_localhost_replica=0;