This is the multi-page printable view of this section. Click here to print.
Setup & maintenance
- 1: S3 & object storage
- 1.1: AWS S3 Recipes
- 1.2: Clean up orphaned objects on s3
- 1.3: How much data are written to S3 during mutations
- 1.4: Example of the table at s3 with cache
- 1.5: S3Disk
- 2: AggregateFunction(uniq, UUID) doubled after ClickHouse® upgrade
- 3: Can not connect to my ClickHouse® server
- 4: cgroups and kubernetes cloud providers
- 5: Transforming ClickHouse logs to ndjson using Vector.dev
- 6: Altinity Kubernetes Operator For ClickHouse®
- 7: ClickHouse® and different filesystems
- 8: ClickHouse® Access Control and Account Management (RBAC)
- 9: Client Timeouts
- 10: Compatibility layer for the Altinity Kubernetes Operator for ClickHouse®
- 11: How to convert uniqExact states to approximate uniq functions states
- 12: Custom Settings
- 13: Description of asynchronous_metrics
- 14: ClickHouse® data/disk encryption (at rest)
- 15: DR two DC
- 16: How ALTERs work in ClickHouse®
- 17: How to recreate a table in case of total corruption of the replication queue
- 18: http handler example
- 19: Jemalloc heap profiling
- 20: Logging
- 21: High Memory Usage During Merge in system.metric_log
- 22: Precreate parts using clickhouse-local
- 23: Recovery after complete data loss
- 24: How to Replicate ClickHouse RBAC Users and Grants with ZooKeeper/Keeper
- 25: Replication: Can not resolve host of another ClickHouse® server
- 26: source parts size is greater than the current maximum
- 27: Successful ClickHouse® deployment plan
- 28: sysall database (system tables on a cluster level)
- 29: Timeouts during OPTIMIZE FINAL
- 30: Use an executable dictionary as cron task
- 31: Useful settings to turn on/Defaults that should be reconsidered
- 32: Who ate my CPU
- 33: Zookeeper session has expired
- 34: Server configuration files
- 35: Aggressive merges
- 36: Altinity Backup for ClickHouse®
- 37: Altinity packaging compatibility >21.x and earlier
- 38: AWS EC2 Storage
- 39: ClickHouse® in Docker
- 40: ClickHouse® Monitoring
- 41: ClickHouse® versions
- 42: Configure ClickHouse® for low memory environments
- 43: Converting MergeTree to Replicated
- 44: Data Migration
- 44.1: MSSQL bcp pipe to clickhouse-client
- 44.2: Add/Remove a new replica to a ClickHouse® cluster
- 44.3: clickhouse-copier
- 44.3.1: clickhouse-copier 20.3 and earlier
- 44.3.2: clickhouse-copier 20.4 - 21.6
- 44.3.3: Kubernetes job for clickhouse-copier
- 44.4: Distributed table to ClickHouse® Cluster
- 44.5: Fetch Alter Table
- 44.6: Remote table function
- 44.7: Moving ClickHouse to Another Server
- 45: DDLWorker and DDL queue problems
- 46: Merge Shards
- 47: differential backups using clickhouse-backup
- 48: High CPU usage in ClickHouse®
- 49: Load balancers
- 50: memory configuration settings
- 51: Memory Overcommiter
- 52: Moving a table to another device
- 53: MultiDisk (JBOD) Balancing
- 54: Object consistency in a cluster
- 55: Production Cluster Configuration Guide
- 55.1: Backups
- 55.2: Cluster Configuration FAQ
- 55.3: Cluster Configuration Process
- 55.4: Hardware Requirements
- 55.5: Network Configuration
- 56: System tables ate my disk
- 57: ClickHouse® Replication problems
- 58: Replication queue
- 59: Schema migration tools for ClickHouse®
- 59.1: golang-migrate
- 60: Settings to adjust
- 61: Shutting down a node
- 62: SSL connection unexpectedly closed
- 63: Suspiciously many broken parts
- 64: Threads
- 65: Who ate my ClickHouse® memory?
- 66: X rows of Y total rows in filesystem are suspicious
- 67: ZooKeeper
- 67.1: clickhouse-keeper-initd
- 67.2: clickhouse-keeper-service
- 67.3: Install standalone Zookeeper for ClickHouse® on Ubuntu / Debian
- 67.4: How to check the list of watches
- 67.5: JVM sizes and garbage collector settings
- 67.6: Proper setup
- 67.7: Recovering from complete metadata loss in ZooKeeper
- 67.8: Using clickhouse-keeper
- 67.9: ZooKeeper backup
- 67.10: ZooKeeper cluster migration
- 67.11: ZooKeeper cluster migration when using K8s node local storage
- 67.12: ZooKeeper Monitoring
- 67.13: ZooKeeper schema
1 - S3 & object storage
1.1 - AWS S3 Recipes
Using AWS IAM — Identity and Access Management roles
For EC2 instance, there is an option to configure an IAM role:
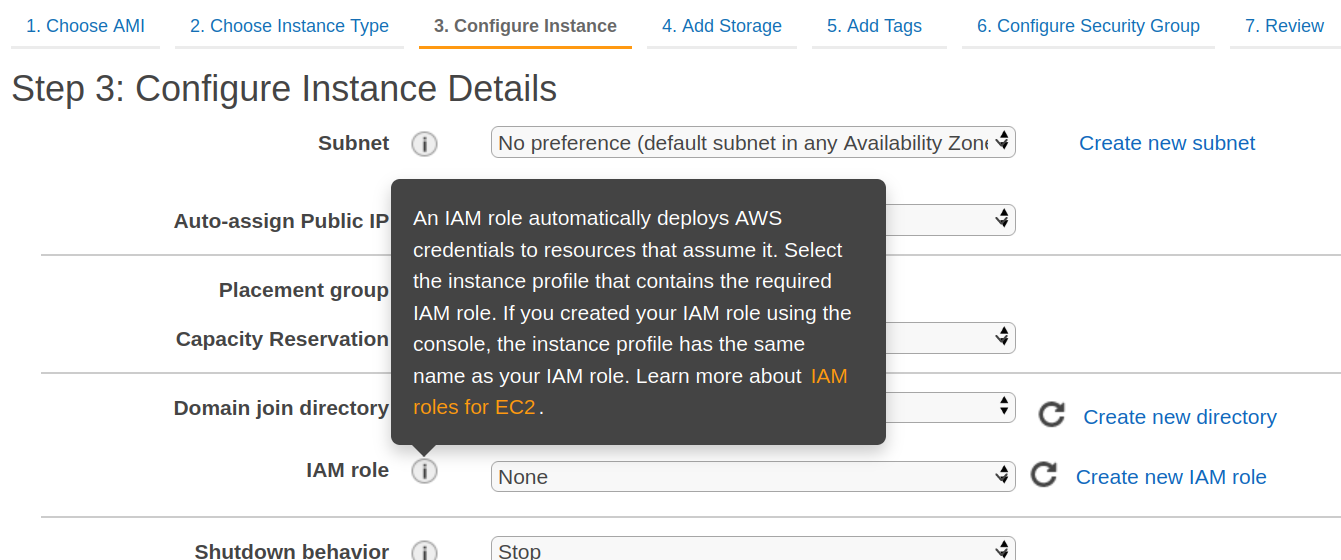
Role shall contain a policy with permissions like:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "allow-put-and-get",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::BUCKET_NAME/test_s3_disk/*"
}
]
}
Corresponding configuration of ClickHouse®:
<clickhouse>
<storage_configuration>
<disks>
<disk_s3>
<type>s3</type>
<endpoint>http://s3.us-east-1.amazonaws.com/BUCKET_NAME/test_s3_disk/</endpoint>
<use_environment_credentials>true</use_environment_credentials>
</disk_s3>
</disks>
<policies>
<policy_s3_only>
<volumes>
<volume_s3>
<disk>disk_s3</disk>
</volume_s3>
</volumes>
</policy_s3_only>
</policies>
</storage_configuration>
</clickhouse>
Small check:
CREATE TABLE table_s3 (number Int64) ENGINE=MergeTree() ORDER BY tuple() PARTITION BY tuple() SETTINGS storage_policy='policy_s3_only';
INSERT INTO table_s3 SELECT * FROM system.numbers LIMIT 100000000;
SELECT * FROM table_s3;
DROP TABLE table_s3;
How to use AWS IRSA and IAM in the Altinity Kubernetes Operator for ClickHouse to allow S3 backup without Explicit credentials
Install clickhouse-operator https://github.com/Altinity/clickhouse-operator/tree/master/docs/operator_installation_details.md
Create Role
Create service account with annotations
apiVersion: v1
kind: ServiceAccount
metadata:
name: <SERVICE ACOUNT NAME>
namespace: <NAMESPACE>
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::<ACCOUNT_ID>:role/<ROLE_NAME>
Link service account to podTemplate it will create AWS_ROLE_ARN and AWS_WEB_IDENTITY_TOKEN_FILE environment variables.
apiVersion: "clickhouse.altinity.com/v1"
kind: "ClickHouseInstallation"
metadata:
name: <NAME>
namespace: <NAMESPACE>
spec:
defaults:
templates:
podTemplate: <POD_TEMPLATE_NAME>
templates:
podTemplates:
- name: <POD_TEMPLATE_NAME>
spec:
serviceAccountName: <SERVICE ACCOUNT NAME>
containers:
- name: clickhouse-backup
For EC2 instances the same environment variables should be created:
AWS_ROLE_ARN=arn:aws:iam::<ACCOUNT_ID>:role/<ROLE_NAME>
AWS_WEB_IDENTITY_TOKEN_FILE=/var/run/secrets/eks.amazonaws.com/serviceaccount/token
1.2 - Clean up orphaned objects on s3
Problems
- TRUNCATE and DROP TABLE remove metadata only.
- Long-running queries, merges or other replicas may still reference parts, so ClickHouse delays removal.
- There are bugs in Clickhouse that leave orphaned files, especially after failures.
Solutions
- use our utility for garbage collection - https://github.com/Altinity/s3gc
- or create a separate path in the bucket for every table and every replica and remove the whole path in AWS console
- you can also use clickhouse-disk utility to delete s3 data:
clickhouse-disks --disk s3 --query "remove /cluster/database/table/replica1"
1.3 - How much data are written to S3 during mutations
Configuration
S3 disk with disabled merges
<clickhouse>
<storage_configuration>
<disks>
<s3disk>
<type>s3</type>
<endpoint>https://s3.us-east-1.amazonaws.com/mybucket/test/test/</endpoint>
<use_environment_credentials>1</use_environment_credentials> <!-- use IAM AWS role -->
<!--access_key_id>xxxx</access_key_id>
<secret_access_key>xxx</secret_access_key-->
</s3disk>
</disks>
<policies>
<s3tiered>
<volumes>
<default>
<disk>default</disk>
</default>
<s3disk>
<disk>s3disk</disk>
<prefer_not_to_merge>true</prefer_not_to_merge>
</s3disk>
</volumes>
</s3tiered>
</policies>
</storage_configuration>
</clickhouse>
Let’s create a table and load some synthetic data.
CREATE TABLE test_s3
(
`A` Int64,
`S` String,
`D` Date
)
ENGINE = MergeTree
PARTITION BY D
ORDER BY A
SETTINGS storage_policy = 's3tiered';
insert into test_s3 select number, number, today() - intDiv(number, 10000000) from numbers(7e8);
0 rows in set. Elapsed: 98.091 sec. Processed 700.36 million rows, 5.60 GB (7.14 million rows/s., 57.12 MB/s.)
select disk_name, partition, sum(rows), formatReadableSize(sum(bytes_on_disk)) size, count() part_count
from system.parts where table= 'test_s3' and active
group by disk_name, partition
order by partition;
┌─disk_name─┬─partition──┬─sum(rows)─┬─size──────┬─part_count─┐
│ default │ 2023-05-06 │ 10000000 │ 78.23 MiB │ 5 │
│ default │ 2023-05-07 │ 10000000 │ 78.31 MiB │ 6 │
│ default │ 2023-05-08 │ 10000000 │ 78.16 MiB │ 5 │
....
│ default │ 2023-07-12 │ 10000000 │ 78.21 MiB │ 5 │
│ default │ 2023-07-13 │ 10000000 │ 78.23 MiB │ 6 │
│ default │ 2023-07-14 │ 10000000 │ 77.39 MiB │ 5 │
└───────────┴────────────┴───────────┴───────────┴────────────┘
70 rows in set. Elapsed: 0.023 sec.
Performance of mutations for a local EBS (throughput: 500 MB/s)
select * from test_s3 where A=490000000;
1 row in set. Elapsed: 0.020 sec. Processed 8.19 thousand rows, 92.67 KB (419.17 thousand rows/s., 4.74 MB/s.)
select * from test_s3 where S='490000000';
1 row in set. Elapsed: 14.117 sec. Processed 700.00 million rows, 12.49 GB (49.59 million rows/s., 884.68 MB/s.)
delete from test_s3 where S = '490000000';
0 rows in set. Elapsed: 22.192 sec.
delete from test_s3 where A = '490000001';
0 rows in set. Elapsed: 2.243 sec.
alter table test_s3 delete where S = 590000000 settings mutations_sync=2;
0 rows in set. Elapsed: 21.387 sec.
alter table test_s3 delete where A = '590000001' settings mutations_sync=2;
0 rows in set. Elapsed: 3.372 sec.
alter table test_s3 update S='' where S = '690000000' settings mutations_sync=2;
0 rows in set. Elapsed: 20.265 sec.
alter table test_s3 update S='' where A = '690000001' settings mutations_sync=2;
0 rows in set. Elapsed: 1.979 sec.
Let’s move data to S3
alter table test_s3 modify TTL D + interval 10 day to disk 's3disk';
-- 10 minutes later
┌─disk_name─┬─partition──┬─sum(rows)─┬─size──────┬─part_count─┐
│ s3disk │ 2023-05-06 │ 10000000 │ 78.23 MiB │ 5 │
│ s3disk │ 2023-05-07 │ 10000000 │ 78.31 MiB │ 6 │
│ s3disk │ 2023-05-08 │ 10000000 │ 78.16 MiB │ 5 │
│ s3disk │ 2023-05-09 │ 10000000 │ 78.21 MiB │ 6 │
│ s3disk │ 2023-05-10 │ 10000000 │ 78.21 MiB │ 6 │
...
│ s3disk │ 2023-07-02 │ 10000000 │ 78.22 MiB │ 5 │
...
│ default │ 2023-07-11 │ 10000000 │ 78.20 MiB │ 6 │
│ default │ 2023-07-12 │ 10000000 │ 78.21 MiB │ 5 │
│ default │ 2023-07-13 │ 10000000 │ 78.23 MiB │ 6 │
│ default │ 2023-07-14 │ 10000000 │ 77.40 MiB │ 5 │
└───────────┴────────────┴───────────┴───────────┴────────────┘
70 rows in set. Elapsed: 0.007 sec.
Sizes of a table on S3 and a size of each column
select sum(rows), formatReadableSize(sum(bytes_on_disk)) size
from system.parts where table= 'test_s3' and active and disk_name = 's3disk';
┌─sum(rows)─┬─size─────┐
│ 600000000 │ 4.58 GiB │
└───────────┴──────────┘
SELECT
database,
table,
column,
formatReadableSize(sum(column_data_compressed_bytes) AS size) AS compressed
FROM system.parts_columns
WHERE (active = 1) AND (database LIKE '%') AND (table LIKE 'test_s3') AND (disk_name = 's3disk')
GROUP BY
database,
table,
column
ORDER BY column ASC
┌─database─┬─table───┬─column─┬─compressed─┐
│ default │ test_s3 │ A │ 2.22 GiB │
│ default │ test_s3 │ D │ 5.09 MiB │
│ default │ test_s3 │ S │ 2.33 GiB │
└──────────┴─────────┴────────┴────────────┘
S3 Statistics of selects
select *, _part from test_s3 where A=100000000;
┌─────────A─┬─S─────────┬──────────D─┬─_part──────────────────┐
│ 100000000 │ 100000000 │ 2023-07-08 │ 20230708_106_111_1_738 │
└───────────┴───────────┴────────────┴────────────────────────┘
1 row in set. Elapsed: 0.104 sec. Processed 8.19 thousand rows, 65.56 KB (79.11 thousand rows/s., 633.07 KB/s.)
┌─S3GetObject─┬─S3PutObject─┬─ReadBufferFromS3─┬─WriteBufferFromS3─┐
│ 6 │ 0 │ 70.58 KiB │ 0.00 B │
└─────────────┴─────────────┴──────────────────┴───────────────────┘
Select by primary key read only 70.58 KiB from S3
Size of this part
SELECT
database, table, column,
formatReadableSize(sum(column_data_compressed_bytes) AS size) AS compressed
FROM system.parts_columns
WHERE (active = 1) AND (database LIKE '%') AND (table LIKE 'test_s3') AND (disk_name = 's3disk')
and name = '20230708_106_111_1_738'
GROUP BY database, table, column ORDER BY column ASC
┌─database─┬─table───┬─column─┬─compressed─┐
│ default │ test_s3 │ A │ 22.51 MiB │
│ default │ test_s3 │ D │ 51.47 KiB │
│ default │ test_s3 │ S │ 23.52 MiB │
└──────────┴─────────┴────────┴────────────┘
select * from test_s3 where S='100000000';
┌─────────A─┬─S─────────┬──────────D─┐
│ 100000000 │ 100000000 │ 2023-07-08 │
└───────────┴───────────┴────────────┘
1 row in set. Elapsed: 86.745 sec. Processed 700.00 million rows, 12.49 GB (8.07 million rows/s., 144.04 MB/s.)
┌─S3GetObject─┬─S3PutObject─┬─ReadBufferFromS3─┬─WriteBufferFromS3─┐
│ 947 │ 0 │ 2.36 GiB │ 0.00 B │
└─────────────┴─────────────┴──────────────────┴───────────────────┘
Select using fullscan of S column read only 2.36 GiB from S3, the whole S column (2.33 GiB) plus parts of A and D.
delete from test_s3 where A=100000000;
0 rows in set. Elapsed: 17.429 sec.
┌─q──┬─S3GetObject─┬─S3PutObject─┬─ReadBufferFromS3─┬─WriteBufferFromS3─┐
│ Q3 │ 2981 │ 6 │ 23.06 MiB │ 27.25 KiB │
└────┴─────────────┴─────────────┴──────────────────┴───────────────────┘
insert into test select 'Q3' q, event,value from system.events where event like '%S3%';
delete from test_s3 where S='100000001';
0 rows in set. Elapsed: 31.417 sec.
┌─q──┬─S3GetObject─┬─S3PutObject─┬─ReadBufferFromS3─┬─WriteBufferFromS3─┐
│ Q4 │ 4209 │ 6 │ 2.39 GiB │ 27.25 KiB │
└────┴─────────────┴─────────────┴──────────────────┴───────────────────┘
insert into test select 'Q4' q, event,value from system.events where event like '%S3%';
alter table test_s3 delete where A=110000000 settings mutations_sync=2;
0 rows in set. Elapsed: 19.521 sec.
┌─q──┬─S3GetObject─┬─S3PutObject─┬─ReadBufferFromS3─┬─WriteBufferFromS3─┐
│ Q5 │ 2986 │ 15 │ 42.27 MiB │ 41.72 MiB │
└────┴─────────────┴─────────────┴──────────────────┴───────────────────┘
insert into test select 'Q5' q, event,value from system.events where event like '%S3%';
alter table test_s3 delete where S='110000001' settings mutations_sync=2;
0 rows in set. Elapsed: 29.650 sec.
┌─q──┬─S3GetObject─┬─S3PutObject─┬─ReadBufferFromS3─┬─WriteBufferFromS3─┐
│ Q6 │ 4212 │ 15 │ 2.42 GiB │ 41.72 MiB │
└────┴─────────────┴─────────────┴──────────────────┴───────────────────┘
insert into test select 'Q6' q, event,value from system.events where event like '%S3%';
1.4 - Example of the table at s3 with cache
Storage configuration
cat /etc/clickhouse-server/config.d/s3.xml
<clickhouse>
<storage_configuration>
<disks>
<s3disk>
<type>s3</type>
<endpoint>https://s3.us-east-1.amazonaws.com/mybucket/test/s3cached/</endpoint>
<use_environment_credentials>1</use_environment_credentials> <!-- use IAM AWS role -->
<!--access_key_id>xxxx</access_key_id>
<secret_access_key>xxx</secret_access_key-->
</s3disk>
<cache>
<type>cache</type>
<disk>s3disk</disk>
<path>/var/lib/clickhouse/disks/s3_cache/</path>
<max_size>50Gi</max_size> <!-- 50GB local cache to cache remote data -->
</cache>
</disks>
<policies>
<s3tiered>
<volumes>
<default>
<disk>default</disk>
<max_data_part_size_bytes>50000000000</max_data_part_size_bytes> <!-- only for parts less than 50GB after they moved to s3 during merges -->
</default>
<s3cached>
<disk>cache</disk> <!-- sandwich cache plus s3disk -->
<!-- prefer_not_to_merge>true</prefer_not_to_merge>
<perform_ttl_move_on_insert>false</perform_ttl_move_on_insert-->
</s3cached>
</volumes>
</s3tiered>
</policies>
</storage_configuration>
</clickhouse>
select * from system.disks
┌─name────┬─path──────────────────────────────┬───────────free_space─┬──────────total_space─┬
│ cache │ /var/lib/clickhouse/disks/s3disk/ │ 18446744073709551615 │ 18446744073709551615 │
│ default │ /var/lib/clickhouse/ │ 149113987072 │ 207907635200 │
│ s3disk │ /var/lib/clickhouse/disks/s3disk/ │ 18446744073709551615 │ 18446744073709551615 │
└─────────┴───────────────────────────────────┴──────────────────────┴──────────────────────┴
select * from system.storage_policies;
┌─policy_name─┬─volume_name─┬─volume_priority─┬─disks───────┬─volume_type─┬─max_data_part_size─┬─move_factor─┬─prefer_not_to_merge─┐
│ default │ default │ 1 │ ['default'] │ JBOD │ 0 │ 0 │ 0 │
│ s3tiered │ default │ 1 │ ['default'] │ JBOD │ 50000000000 │ 0.1 │ 0 │
│ s3tiered │ s3cached │ 2 │ ['s3disk'] │ JBOD │ 0 │ 0.1 │ 0 │
└─────────────┴─────────────┴─────────────────┴─────────────┴─────────────┴────────────────────┴─────────────┴─────────────────────┘
example with a new table
CREATE TABLE test_s3
(
`A` Int64,
`S` String,
`D` Date
)
ENGINE = MergeTree
PARTITION BY D
ORDER BY A
SETTINGS storage_policy = 's3tiered';
insert into test_s3 select number, number, '2023-01-01' from numbers(1e9);
0 rows in set. Elapsed: 270.285 sec. Processed 1.00 billion rows, 8.00 GB (3.70 million rows/s., 29.60 MB/s.)
Table size is 7.65 GiB and it at the default disk (EBS):
select disk_name, partition, sum(rows), formatReadableSize(sum(bytes_on_disk)) size, count() part_count
from system.parts where table= 'test_s3' and active
group by disk_name, partition;
┌─disk_name─┬─partition──┬──sum(rows)─┬─size─────┬─part_count─┐
│ default │ 2023-01-01 │ 1000000000 │ 7.65 GiB │ 8 │
└───────────┴────────────┴────────────┴──────────┴────────────┘
It seems my EBS write speed is slower than S3 write speed:
alter table test_s3 move partition '2023-01-01' to volume 's3cached';
0 rows in set. Elapsed: 98.979 sec.
alter table test_s3 move partition '2023-01-01' to volume 'default';
0 rows in set. Elapsed: 127.741 sec.
Queries performance against EBS:
select * from test_s3 where A = 443;
1 row in set. Elapsed: 0.002 sec. Processed 8.19 thousand rows, 71.64 KB (3.36 million rows/s., 29.40 MB/s.)
select uniq(A) from test_s3;
1 row in set. Elapsed: 11.439 sec. Processed 1.00 billion rows, 8.00 GB (87.42 million rows/s., 699.33 MB/s.)
select count() from test_s3 where S like '%4422%'
1 row in set. Elapsed: 17.484 sec. Processed 1.00 billion rows, 17.89 GB (57.20 million rows/s., 1.02 GB/s.)
Let’s move data to S3
alter table test_s3 move partition '2023-01-01' to volume 's3cached';
0 rows in set. Elapsed: 81.068 sec.
select disk_name, partition, sum(rows), formatReadableSize(sum(bytes_on_disk)) size, count() part_count
from system.parts where table= 'test_s3' and active
group by disk_name, partition;
┌─disk_name─┬─partition──┬──sum(rows)─┬─size─────┬─part_count─┐
│ s3disk │ 2023-01-01 │ 1000000000 │ 7.65 GiB │ 8 │
└───────────┴────────────┴────────────┴──────────┴────────────┘
The first query execution against S3, the second against the cache (local EBS):
select * from test_s3 where A = 443;
1 row in set. Elapsed: 0.458 sec. Processed 8.19 thousand rows, 71.64 KB (17.88 thousand rows/s., 156.35 KB/s.)
1 row in set. Elapsed: 0.003 sec. Processed 8.19 thousand rows, 71.64 KB (3.24 million rows/s., 28.32 MB/s.)
select uniq(A) from test_s3;
1 row in set. Elapsed: 26.601 sec. Processed 1.00 billion rows, 8.00 GB (37.59 million rows/s., 300.74 MB/s.)
1 row in set. Elapsed: 8.675 sec. Processed 1.00 billion rows, 8.00 GB (115.27 million rows/s., 922.15 MB/s.)
select count() from test_s3 where S like '%4422%'
1 row in set. Elapsed: 33.586 sec. Processed 1.00 billion rows, 17.89 GB (29.77 million rows/s., 532.63 MB/s.)
1 row in set. Elapsed: 16.551 sec. Processed 1.00 billion rows, 17.89 GB (60.42 million rows/s., 1.08 GB/s.)
Cache introspection
select cache_base_path, formatReadableSize(sum(size)) from system.filesystem_cache group by 1;
┌─cache_base_path─────────────────────┬─formatReadableSize(sum(size))─┐
│ /var/lib/clickhouse/disks/s3_cache/ │ 7.64 GiB │
└─────────────────────────────────────┴───────────────────────────────┘
system drop FILESYSTEM cache;
select cache_base_path, formatReadableSize(sum(size)) from system.filesystem_cache group by 1;
0 rows in set. Elapsed: 0.005 sec.
select * from test_s3 where A = 443;
1 row in set. Elapsed: 0.221 sec. Processed 8.19 thousand rows, 71.64 KB (37.10 thousand rows/s., 324.47 KB/s.)
select cache_base_path, formatReadableSize(sum(size)) from system.filesystem_cache group by 1;
┌─cache_base_path─────────────────────┬─formatReadableSize(sum(size))─┐
│ /var/lib/clickhouse/disks/s3_cache/ │ 105.95 KiB │
└─────────────────────────────────────┴───────────────────────────────┘
No data is stored locally (except system log tables).
select name, formatReadableSize(free_space) free_space, formatReadableSize(total_space) total_space from system.disks;
┌─name────┬─free_space─┬─total_space─┐
│ cache │ 16.00 EiB │ 16.00 EiB │
│ default │ 48.97 GiB │ 49.09 GiB │
│ s3disk │ 16.00 EiB │ 16.00 EiB │
└─────────┴────────────┴─────────────┘
example with an existing table
The mydata table is created without the explicitly defined storage_policy, it means that implicitly storage_policy=default / volume=default / disk=default.
select disk_name, partition, sum(rows), formatReadableSize(sum(bytes_on_disk)) size, count() part_count
from system.parts where table='mydata' and active
group by disk_name, partition
order by partition;
┌─disk_name─┬─partition─┬─sum(rows)─┬─size───────┬─part_count─┐
│ default │ 202201 │ 516666677 │ 4.01 GiB │ 13 │
│ default │ 202202 │ 466666657 │ 3.64 GiB │ 13 │
│ default │ 202203 │ 16666666 │ 138.36 MiB │ 10 │
│ default │ 202301 │ 516666677 │ 4.01 GiB │ 10 │
│ default │ 202302 │ 466666657 │ 3.64 GiB │ 10 │
│ default │ 202303 │ 16666666 │ 138.36 MiB │ 10 │
└───────────┴───────────┴───────────┴────────────┴────────────┘
-- Let's change the storage policy, this command instant and changes only metadata of the table, and possible because the new storage policy and the old has the volume `default`.
alter table mydata modify setting storage_policy = 's3tiered';
0 rows in set. Elapsed: 0.057 sec.
straightforward (heavy) approach
-- Let's add TTL, it's a heavy command and takes a lot time and creates the performance impact, because it reads `D` column and moves parts to s3.
alter table mydata modify TTL D + interval 1 year to volume 's3cached';
0 rows in set. Elapsed: 140.661 sec.
┌─disk_name─┬─partition─┬─sum(rows)─┬─size───────┬─part_count─┐
│ s3disk │ 202201 │ 516666677 │ 4.01 GiB │ 13 │
│ s3disk │ 202202 │ 466666657 │ 3.64 GiB │ 13 │
│ s3disk │ 202203 │ 16666666 │ 138.36 MiB │ 10 │
│ default │ 202301 │ 516666677 │ 4.01 GiB │ 10 │
│ default │ 202302 │ 466666657 │ 3.64 GiB │ 10 │
│ default │ 202303 │ 16666666 │ 138.36 MiB │ 10 │
└───────────┴───────────┴───────────┴────────────┴────────────┘
gentle (manual) approach
-- alter modify TTL changes only metadata of the table and applied to only newly insterted data.
set materialize_ttl_after_modify=0;
alter table mydata modify TTL D + interval 1 year to volume 's3cached';
0 rows in set. Elapsed: 0.049 sec.
-- move data slowly partition by partition
alter table mydata move partition id '202201' to volume 's3cached';
0 rows in set. Elapsed: 49.410 sec.
alter table mydata move partition id '202202' to volume 's3cached';
0 rows in set. Elapsed: 36.952 sec.
alter table mydata move partition id '202203' to volume 's3cached';
0 rows in set. Elapsed: 4.808 sec.
-- data can be optimized to reduce number of parts before moving it to s3
optimize table mydata partition id '202301' final;
0 rows in set. Elapsed: 66.551 sec.
alter table mydata move partition id '202301' to volume 's3cached';
0 rows in set. Elapsed: 33.332 sec.
┌─disk_name─┬─partition─┬─sum(rows)─┬─size───────┬─part_count─┐
│ s3disk │ 202201 │ 516666677 │ 4.01 GiB │ 13 │
│ s3disk │ 202202 │ 466666657 │ 3.64 GiB │ 13 │
│ s3disk │ 202203 │ 16666666 │ 138.36 MiB │ 10 │
│ s3disk │ 202301 │ 516666677 │ 4.01 GiB │ 1 │ -- optimized partition
│ default │ 202302 │ 466666657 │ 3.64 GiB │ 13 │
│ default │ 202303 │ 16666666 │ 138.36 MiB │ 10 │
└───────────┴───────────┴───────────┴────────────┴────────────┘
S3 and ClickHouse® start time
Let’s create a table with 1000 parts and move them to s3.
CREATE TABLE test_s3( A Int64, S String, D Date)
ENGINE = MergeTree PARTITION BY D ORDER BY A
SETTINGS storage_policy = 's3tiered';
insert into test_s3 select number, number, toDate('2000-01-01') + intDiv(number,1e6) from numbers(1e9);
optimize table test_s3 final settings optimize_skip_merged_partitions = 1;
select disk_name, sum(rows), formatReadableSize(sum(bytes_on_disk)) size, count() part_count
from system.parts where table= 'test_s3' and active group by disk_name;
┌─disk_name─┬──sum(rows)─┬─size─────┬─part_count─┐
│ default │ 1000000000 │ 7.64 GiB │ 1000 │
└───────────┴────────────┴──────────┴────────────┘
alter table test_s3 modify ttl D + interval 1 year to disk 's3disk';
select disk_name, sum(rows), formatReadableSize(sum(bytes_on_disk)) size, count() part_count
from system.parts where table= 'test_s3' and active
group by disk_name;
┌─disk_name─┬─sum(rows)─┬─size─────┬─part_count─┐
│ default │ 755000000 │ 5.77 GiB │ 755 │
│ s3disk │ 245000000 │ 1.87 GiB │ 245 │
└───────────┴───────────┴──────────┴────────────┘
---- several minutes later ----
┌─disk_name─┬──sum(rows)─┬─size─────┬─part_count─┐
│ s3disk │ 1000000000 │ 7.64 GiB │ 1000 │
└───────────┴────────────┴──────────┴────────────┘
start time
:) select name, value from system.merge_tree_settings where name = 'max_part_loading_threads';
┌─name─────────────────────┬─value─────┐
│ max_part_loading_threads │ 'auto(4)' │
└──────────────────────────┴───────────┘
# systemctl stop clickhouse-server
# time systemctl start clickhouse-server / real 4m26.766s
# systemctl stop clickhouse-server
# time systemctl start clickhouse-server / real 4m24.263s
# cat /etc/clickhouse-server/config.d/max_part_loading_threads.xml
<?xml version="1.0"?>
<clickhouse>
<merge_tree>
<max_part_loading_threads>128</max_part_loading_threads>
</merge_tree>
</clickhouse>
# systemctl stop clickhouse-server
# time systemctl start clickhouse-server / real 0m11.225s
# systemctl stop clickhouse-server
# time systemctl start clickhouse-server / real 0m10.797s
<max_part_loading_threads>256</max_part_loading_threads>
# systemctl stop clickhouse-server
# time systemctl start clickhouse-server / real 0m8.474s
# systemctl stop clickhouse-server
# time systemctl start clickhouse-server / real 0m8.130s
1.5 - S3Disk
Settings
<clickhouse>
<storage_configuration>
<disks>
<s3>
<type>s3</type>
<endpoint>http://s3.us-east-1.amazonaws.com/BUCKET_NAME/test_s3_disk/</endpoint>
<access_key_id>ACCESS_KEY_ID</access_key_id>
<secret_access_key>SECRET_ACCESS_KEY</secret_access_key>
<skip_access_check>true</skip_access_check>
<send_metadata>true</send_metadata>
</s3>
</disks>
</storage_configuration>
</clickhouse>
skip_access_check — if true, it’s possible to use read only credentials with regular MergeTree table. But you would need to disable merges (
prefer_not_to_mergesetting) on s3 volume as well.send_metadata — if true, ClickHouse® will populate s3 object with initial part & file path, which allow you to recover metadata from s3 and make debug easier.
Restore metadata from S3
Default
Limitations:
- ClickHouse need RW access to this bucket
In order to restore metadata, you would need to create restore file in metadata_path/_s3_disk_name_ directory:
touch /var/lib/clickhouse/disks/_s3_disk_name_/restore
In that case ClickHouse would restore to the same bucket and path and update only metadata files in s3 bucket.
Custom
Limitations:
- ClickHouse needs RO access to the old bucket and RW to the new.
- ClickHouse will copy objects in case of restoring to a different bucket or path.
If you would like to change bucket or path, you need to populate restore file with settings in key=value format:
cat /var/lib/clickhouse/disks/_s3_disk_name_/restore
source_bucket=s3disk
source_path=vol1/
Links
2 - AggregateFunction(uniq, UUID) doubled after ClickHouse® upgrade
What happened
After ClickHouse® upgrade from version pre 21.6 to version after 21.6, count of unique UUID in AggregatingMergeTree tables nearly doubled in case of merging of data which was generated in different ClickHouse versions.
Why happened
In pull request which changed the internal representation of big integers data types (and UUID). SipHash64 hash-function used for uniq aggregation function for UUID data type was replaced with intHash64, which leads to different result for the same UUID value across different ClickHouse versions. Therefore, it results in doubling of counts, when uniqState created by different ClickHouse versions being merged together.
Related issue .
Solution
You need to replace any occurrence of uniqState(uuid) in MATERIALIZED VIEWs with uniqState(sipHash64(uuid)) and change data type for already saved data from AggregateFunction(uniq, UUID) to AggregateFunction(uniq, UInt64), because result data type of sipHash64 is UInt64.
-- On ClickHouse version 21.3
CREATE TABLE uniq_state
(
`key` UInt32,
`value` AggregateFunction(uniq, UUID)
)
ENGINE = MergeTree
ORDER BY key
INSERT INTO uniq_state SELECT
number % 10000 AS key,
uniqState(reinterpretAsUUID(number))
FROM numbers(1000000)
GROUP BY key
Ok.
0 rows in set. Elapsed: 0.404 sec. Processed 1.05 million rows, 8.38 MB (2.59 million rows/s., 20.74 MB/s.)
SELECT
key % 20,
uniqMerge(value)
FROM uniq_state
GROUP BY key % 20
┌─modulo(key, 20)─┬─uniqMerge(value)─┐
│ 0 │ 50000 │
│ 1 │ 50000 │
│ 2 │ 50000 │
│ 3 │ 50000 │
│ 4 │ 50000 │
│ 5 │ 50000 │
│ 6 │ 49999 │
│ 7 │ 50000 │
│ 8 │ 49999 │
│ 9 │ 50000 │
│ 10 │ 50000 │
│ 11 │ 50000 │
│ 12 │ 50000 │
│ 13 │ 50000 │
│ 14 │ 50000 │
│ 15 │ 50000 │
│ 16 │ 50000 │
│ 17 │ 50000 │
│ 18 │ 50000 │
│ 19 │ 50000 │
└─────────────────┴──────────────────┘
-- After upgrade of ClickHouse to 21.8
SELECT
key % 20,
uniqMerge(value)
FROM uniq_state
GROUP BY key % 20
┌─modulo(key, 20)─┬─uniqMerge(value)─┐
│ 0 │ 50000 │
│ 1 │ 50000 │
│ 2 │ 50000 │
│ 3 │ 50000 │
│ 4 │ 50000 │
│ 5 │ 50000 │
│ 6 │ 49999 │
│ 7 │ 50000 │
│ 8 │ 49999 │
│ 9 │ 50000 │
│ 10 │ 50000 │
│ 11 │ 50000 │
│ 12 │ 50000 │
│ 13 │ 50000 │
│ 14 │ 50000 │
│ 15 │ 50000 │
│ 16 │ 50000 │
│ 17 │ 50000 │
│ 18 │ 50000 │
│ 19 │ 50000 │
└─────────────────┴──────────────────┘
20 rows in set. Elapsed: 0.240 sec. Processed 10.00 thousand rows, 1.16 MB (41.72 thousand rows/s., 4.86 MB/s.)
CREATE TABLE uniq_state_2
ENGINE = MergeTree
ORDER BY key AS
SELECT *
FROM uniq_state
Ok.
0 rows in set. Elapsed: 0.128 sec. Processed 10.00 thousand rows, 1.16 MB (78.30 thousand rows/s., 9.12 MB/s.)
INSERT INTO uniq_state_2 SELECT
number % 10000 AS key,
uniqState(reinterpretAsUUID(number))
FROM numbers(1000000)
GROUP BY key
Ok.
0 rows in set. Elapsed: 0.266 sec. Processed 1.05 million rows, 8.38 MB (3.93 million rows/s., 31.48 MB/s.)
SELECT
key % 20,
uniqMerge(value)
FROM uniq_state_2
GROUP BY key % 20
┌─modulo(key, 20)─┬─uniqMerge(value)─┐
│ 0 │ 99834 │ <- Count of unique values nearly doubled.
│ 1 │ 100219 │
│ 2 │ 100128 │
│ 3 │ 100457 │
│ 4 │ 100272 │
│ 5 │ 100279 │
│ 6 │ 99372 │
│ 7 │ 99450 │
│ 8 │ 99974 │
│ 9 │ 99632 │
│ 10 │ 99562 │
│ 11 │ 100660 │
│ 12 │ 100439 │
│ 13 │ 100252 │
│ 14 │ 100650 │
│ 15 │ 99320 │
│ 16 │ 100095 │
│ 17 │ 99632 │
│ 18 │ 99540 │
│ 19 │ 100098 │
└─────────────────┴──────────────────┘
20 rows in set. Elapsed: 0.356 sec. Processed 20.00 thousand rows, 2.33 MB (56.18 thousand rows/s., 6.54 MB/s.)
CREATE TABLE uniq_state_3
ENGINE = MergeTree
ORDER BY key AS
SELECT *
FROM uniq_state
0 rows in set. Elapsed: 0.126 sec. Processed 10.00 thousand rows, 1.16 MB (79.33 thousand rows/s., 9.24 MB/s.)
-- Option 1, create separate column
ALTER TABLE uniq_state_3
ADD COLUMN `value_2` AggregateFunction(uniq, UInt64) DEFAULT unhex(hex(value));
ALTER TABLE uniq_state_3
UPDATE value_2 = value_2 WHERE 1;
SELECT *
FROM system.mutations
WHERE is_done = 0;
Ok.
0 rows in set. Elapsed: 0.008 sec.
INSERT INTO uniq_state_3 (key, value_2) SELECT
number % 10000 AS key,
uniqState(sipHash64(reinterpretAsUUID(number)))
FROM numbers(1000000)
GROUP BY key
Ok.
0 rows in set. Elapsed: 0.337 sec. Processed 1.05 million rows, 8.38 MB (3.11 million rows/s., 24.89 MB/s.)
SELECT
key % 20,
uniqMerge(value),
uniqMerge(value_2)
FROM uniq_state_3
GROUP BY key % 20
┌─modulo(key, 20)─┬─uniqMerge(value)─┬─uniqMerge(value_2)─┐
│ 0 │ 50000 │ 50000 │
│ 1 │ 50000 │ 50000 │
│ 2 │ 50000 │ 50000 │
│ 3 │ 50000 │ 50000 │
│ 4 │ 50000 │ 50000 │
│ 5 │ 50000 │ 50000 │
│ 6 │ 49999 │ 49999 │
│ 7 │ 50000 │ 50000 │
│ 8 │ 49999 │ 49999 │
│ 9 │ 50000 │ 50000 │
│ 10 │ 50000 │ 50000 │
│ 11 │ 50000 │ 50000 │
│ 12 │ 50000 │ 50000 │
│ 13 │ 50000 │ 50000 │
│ 14 │ 50000 │ 50000 │
│ 15 │ 50000 │ 50000 │
│ 16 │ 50000 │ 50000 │
│ 17 │ 50000 │ 50000 │
│ 18 │ 50000 │ 50000 │
│ 19 │ 50000 │ 50000 │
└─────────────────┴──────────────────┴────────────────────┘
20 rows in set. Elapsed: 0.768 sec. Processed 20.00 thousand rows, 4.58 MB (26.03 thousand rows/s., 5.96 MB/s.)
-- Option 2, modify column in-place with String as intermediate data type.
ALTER TABLE uniq_state_3
MODIFY COLUMN `value` String
Ok.
0 rows in set. Elapsed: 0.280 sec.
ALTER TABLE uniq_state_3
MODIFY COLUMN `value` AggregateFunction(uniq, UInt64)
Ok.
0 rows in set. Elapsed: 0.254 sec.
INSERT INTO uniq_state_3 (key, value) SELECT
number % 10000 AS key,
uniqState(sipHash64(reinterpretAsUUID(number)))
FROM numbers(1000000)
GROUP BY key
Ok.
0 rows in set. Elapsed: 0.554 sec. Processed 1.05 million rows, 8.38 MB (1.89 million rows/s., 15.15 MB/s.)
SELECT
key % 20,
uniqMerge(value),
uniqMerge(value_2)
FROM uniq_state_3
GROUP BY key % 20
┌─modulo(key, 20)─┬─uniqMerge(value)─┬─uniqMerge(value_2)─┐
│ 0 │ 50000 │ 50000 │
│ 1 │ 50000 │ 50000 │
│ 2 │ 50000 │ 50000 │
│ 3 │ 50000 │ 50000 │
│ 4 │ 50000 │ 50000 │
│ 5 │ 50000 │ 50000 │
│ 6 │ 49999 │ 49999 │
│ 7 │ 50000 │ 50000 │
│ 8 │ 49999 │ 49999 │
│ 9 │ 50000 │ 50000 │
│ 10 │ 50000 │ 50000 │
│ 11 │ 50000 │ 50000 │
│ 12 │ 50000 │ 50000 │
│ 13 │ 50000 │ 50000 │
│ 14 │ 50000 │ 50000 │
│ 15 │ 50000 │ 50000 │
│ 16 │ 50000 │ 50000 │
│ 17 │ 50000 │ 50000 │
│ 18 │ 50000 │ 50000 │
│ 19 │ 50000 │ 50000 │
└─────────────────┴──────────────────┴────────────────────┘
20 rows in set. Elapsed: 0.589 sec. Processed 30.00 thousand rows, 6.87 MB (50.93 thousand rows/s., 11.66 MB/s.)
SHOW CREATE TABLE uniq_state_3;
CREATE TABLE default.uniq_state_3
(
`key` UInt32,
`value` AggregateFunction(uniq, UInt64),
`value_2` AggregateFunction(uniq, UInt64) DEFAULT unhex(hex(value))
)
ENGINE = MergeTree
ORDER BY key
SETTINGS index_granularity = 8192
-- Option 3, CAST uniqState(UInt64) to String.
CREATE TABLE uniq_state_4
ENGINE = MergeTree
ORDER BY key AS
SELECT *
FROM uniq_state
Ok.
0 rows in set. Elapsed: 0.146 sec. Processed 10.00 thousand rows, 1.16 MB (68.50 thousand rows/s., 7.98 MB/s.)
INSERT INTO uniq_state_4 (key, value) SELECT
number % 10000 AS key,
CAST(uniqState(sipHash64(reinterpretAsUUID(number))), 'String')
FROM numbers(1000000)
GROUP BY key
Ok.
0 rows in set. Elapsed: 0.476 sec. Processed 1.05 million rows, 8.38 MB (2.20 million rows/s., 17.63 MB/s.)
SELECT
key % 20,
uniqMerge(value)
FROM uniq_state_4
GROUP BY key % 20
┌─modulo(key, 20)─┬─uniqMerge(value)─┐
│ 0 │ 50000 │
│ 1 │ 50000 │
│ 2 │ 50000 │
│ 3 │ 50000 │
│ 4 │ 50000 │
│ 5 │ 50000 │
│ 6 │ 49999 │
│ 7 │ 50000 │
│ 8 │ 49999 │
│ 9 │ 50000 │
│ 10 │ 50000 │
│ 11 │ 50000 │
│ 12 │ 50000 │
│ 13 │ 50000 │
│ 14 │ 50000 │
│ 15 │ 50000 │
│ 16 │ 50000 │
│ 17 │ 50000 │
│ 18 │ 50000 │
│ 19 │ 50000 │
└─────────────────┴──────────────────┘
20 rows in set. Elapsed: 0.281 sec. Processed 20.00 thousand rows, 2.33 MB (71.04 thousand rows/s., 8.27 MB/s.)
SHOW CREATE TABLE uniq_state_4;
CREATE TABLE default.uniq_state_4
(
`key` UInt32,
`value` AggregateFunction(uniq, UUID)
)
ENGINE = MergeTree
ORDER BY key
SETTINGS index_granularity = 8192
3 - Can not connect to my ClickHouse® server
Can not connect to my ClickHouse® server
Errors like “Connection reset by peer, while reading from socket”
Ensure that the
clickhouse-serveris runningsystemctl status clickhouse-serverIf server was restarted recently and don’t accept the connections after the restart - most probably it still just starting. During the startup sequence it need to iterate over all data folders in /var/lib/clickhouse-server In case if you have a very high number of folders there (usually caused by a wrong partitioning, or a very high number of tables / databases) that startup time can take a lot of time (same can happen if disk is very slow, for example NFS).
You can check that by looking for ‘Ready for connections’ line in
/var/log/clickhouse-server/clickhouse-server.log(Informationlog level needed)Ensure you use the proper port ip / interface?
Ensure you’re not trying to connect to secure port without tls / https or vice versa.
For
clickhouse-client- pay attention on host / port / secure flags.Ensure the interface you’re connecting to is the one which ClickHouse listens (by default ClickHouse listens only localhost).
Note: If you uncomment line
<listen_host>0.0.0.0</listen_host>only - ClickHouse will listen only ipv4 interfaces, while the localhost (used byclickhouse-client) may be resolved to ipv6 address. Andclickhouse-clientmay be failing to connect.How to check which interfaces / ports do ClickHouse listen?
sudo lsof -i -P -n | grep LISTEN echo listen_host sudo clickhouse-extract-from-config --config=/etc/clickhouse-server/config.xml --key=listen_host echo tcp_port sudo clickhouse-extract-from-config --config=/etc/clickhouse-server/config.xml --key=tcp_port echo tcp_port_secure sudo clickhouse-extract-from-config --config=/etc/clickhouse-server/config.xml --key=tcp_port_secure echo http_port sudo clickhouse-extract-from-config --config=/etc/clickhouse-server/config.xml --key=http_port echo https_port sudo clickhouse-extract-from-config --config=/etc/clickhouse-server/config.xml --key=https_portFor secure connection:
- ensure that server uses some certificate which can be validated by the client
- OR disable certificate checks on the client (UNSECURE)
Check for errors in /var/log/clickhouse-server/clickhouse-server.err.log ?
Is ClickHouse able to serve some trivial tcp / http requests from localhost?
curl 127.0.0.1:9200 curl 127.0.0.1:8123Check number of sockets opened by ClickHouse
sudo lsof -i -a -p $(pidof clickhouse-server) # or (adjust 9000 / 8123 ports if needed) netstat -tn 2>/dev/null | tail -n +3 | awk '{ printf("%s\t%s\t%s\t%s\t%s\t%s\n", $1, $2, $3, $4, $5, $6) }' | clickhouse-local -S "Proto String, RecvQ Int64, SendQ Int64, LocalAddress String, ForeignAddress String, State LowCardinality(String)" --query="SELECT * FROM table WHERE LocalAddress like '%:9000' FORMAT PrettyCompact" netstat -tn 2>/dev/null | tail -n +3 | awk '{ printf("%s\t%s\t%s\t%s\t%s\t%s\n", $1, $2, $3, $4, $5, $6) }' | clickhouse-local -S "Proto String, RecvQ Int64, SendQ Int64, LocalAddress String, ForeignAddress String, State LowCardinality(String)" --query="SELECT * FROM table WHERE LocalAddress like '%:8123' FORMAT PrettyCompact"ClickHouse has a limit of number of open connections (4000 by default).
Check also:
# system overall support limited number of connections it can handle netstat # you can also be reaching of of the process ulimits (Max open files) cat /proc/$(pidof -s clickhouse-server)/limitsCheck firewall / selinux rules (if used)
4 - cgroups and kubernetes cloud providers
Why my ClickHouse® is slow after upgrade to version 22.2 and higher?
The probable reason is that ClickHouse 22.2 started to respect cgroups (Respect cgroups limits in max_threads autodetection. #33342 (JaySon ).
You can observe that max_threads = 1
SELECT
name,
value
FROM system.settings
WHERE name = 'max_threads'
┌─name────────┬─value─────┐
│ max_threads │ 'auto(1)' │
└─────────────┴───────────┘
This makes ClickHouse to execute all queries with a single thread (normal behavior is half of available CPU cores, cores = 64, then ‘auto(32)’).
We observe this cgroups behavior with AWS EKS (Kubernetes) environment and Altinity ClickHouse Operator in case if requests.cpu and limits.cpu are not set for a resource.
Workaround
We suggest to set requests.cpu = half of available CPU cores, and limits.cpu = CPU cores.
For example in case of 16 CPU cores:
resources:
requests:
memory: ...
cpu: 8
limits:
memory: ....
cpu: 16
Then you should get a new result:
SELECT
name,
value
FROM system.settings
WHERE name = 'max_threads'
┌─name────────┬─value─────┐
│ max_threads │ 'auto(8)' │
└─────────────┴───────────┘
in depth
For some reason AWS EKS sets cgroup kernel parameters in case of empty requests.cpu & limits.cpu into these:
# cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
-1
# cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
100000
# cat /sys/fs/cgroup/cpu/cpu.shares
2
This makes ClickHouse to set max_threads = 1 because of
cgroup_share = /sys/fs/cgroup/cpu/cpu.shares (2)
PER_CPU_SHARES = 1024
share_count = ceil( cgroup_share / PER_CPU_SHARES ) ---> ceil(2 / 1024) ---> 1
Fix
Incorrect calculation was fixed in https://github.com/ClickHouse/ClickHouse/pull/35815 and will work correctly on newer releases.
5 - Transforming ClickHouse logs to ndjson using Vector.dev
ClickHouse 22.8
Starting from 22.8 version, ClickHouse support writing logs in JSON format:
<?xml version="1.0"?>
<clickhouse>
<logger>
<!-- Structured log formatting:
You can specify log format(for now, JSON only). In that case, the console log will be printed
in specified format like JSON.
For example, as below:
{"date_time":"1650918987.180175","thread_name":"#1","thread_id":"254545","level":"Trace","query_id":"","logger_name":"BaseDaemon","message":"Received signal 2","source_file":"../base/daemon/BaseDaemon.cpp; virtual void SignalListener::run()","source_line":"192"}
To enable JSON logging support, just uncomment <formatting> tag below.
-->
<formatting>json</formatting>
</logger>
</clickhouse>
Transforming ClickHouse logs to ndjson using Vector.dev"
Installation of vector.dev
# arm64
wget https://packages.timber.io/vector/0.15.2/vector_0.15.2-1_arm64.deb
# amd64
wget https://packages.timber.io/vector/0.15.2/vector_0.15.2-1_amd64.deb
dpkg -i vector_0.15.2-1_*.deb
systemctl stop vector
mkdir /var/log/clickhouse-server-json
chown vector.vector /var/log/clickhouse-server-json
usermod -a -G clickhouse vector
vector config
# cat /etc/vector/vector.toml
data_dir = "/var/lib/vector"
[sources.clickhouse-log]
type = "file"
include = [ "/var/log/clickhouse-server/clickhouse-server.log" ]
fingerprinting.strategy = "device_and_inode"
message_start_indicator = '^\d+\.\d+\.\d+ \d+:\d+:\d+'
multi_line_timeout = 1000
[transforms.clickhouse-log-text]
inputs = [ "clickhouse-log" ]
type = "remap"
source = '''
. |= parse_regex!(.message, r'^(?P<timestamp>\d+\.\d+\.\d+ \d+:\d+:\d+\.\d+) \[\s?(?P<thread_id>\d+)\s?\] \{(?P<query_id>.*)\} <(?P<severity>\w+)> (?s)(?P<message>.*$)')
'''
[sinks.emit-clickhouse-log-json]
type = "file"
inputs = [ "clickhouse-log-text" ]
compression = "none"
path = "/var/log/clickhouse-server-json/clickhouse-server.%Y-%m-%d.ndjson"
encoding.only_fields = ["timestamp", "thread_id", "query_id", "severity", "message" ]
encoding.codec = "ndjson"
start
systemctl start vector
tail /var/log/clickhouse-server-json/clickhouse-server.2022-04-21.ndjson
{"message":"DiskLocal: Reserving 1.00 MiB on disk `default`, having unreserved 166.80 GiB.","query_id":"","severity":"Debug","thread_id":"283239","timestamp":"2022.04.21 13:43:21.164660"}
{"message":"MergedBlockOutputStream: filled checksums 202204_67118_67118_0 (state Temporary)","query_id":"","severity":"Trace","thread_id":"283239","timestamp":"2022.04.21 13:43:21.166810"}
{"message":"system.metric_log (e3365172-4c9b-441b-b803-756ae030e741): Renaming temporary part tmp_insert_202204_67118_67118_0 to 202204_171703_171703_0.","query_id":"","severity":"Trace","thread_id":"283239","timestamp":"2022.04.21 13:43:21.167226"}
....
sink logs into ClickHouse table
Be careful with logging ClickHouse messages into the same ClickHouse instance, it will cause endless recursive self-logging.
create table default.clickhouse_logs(
timestamp DateTime64(3),
host LowCardinality(String),
thread_id LowCardinality(String),
severity LowCardinality(String),
query_id String,
message String)
Engine = MergeTree
Partition by toYYYYMM(timestamp)
Order by (toStartOfHour(timestamp), host, severity, query_id);
create user vector identified by 'vector1234';
grant insert on default.clickhouse_logs to vector;
create settings profile or replace profile_vector settings log_queries=0 readonly TO vector;
[sinks.clickhouse-output-clickhouse]
inputs = ["clickhouse-log-text"]
type = "clickhouse"
host = "http://localhost:8123"
database = "default"
auth.strategy = "basic"
auth.user = "vector"
auth.password = "vector1234"
healthcheck = true
table = "clickhouse_logs"
encoding.timestamp_format = "unix"
buffer.type = "disk"
buffer.max_size = 104900000
buffer.when_full = "block"
request.in_flight_limit = 20
encoding.only_fields = ["host", "timestamp", "thread_id", "query_id", "severity", "message"]
select * from default.clickhouse_logs limit 10;
┌───────────────timestamp─┬─host───────┬─thread_id─┬─severity─┬─query_id─┬─message─────────────────────────────────────────────────────
│ 2022-04-21 19:08:13.443 │ clickhouse │ 283155 │ Debug │ │ HTTP-Session: 13e87050-7824-46b0-9bd5-29469a1b102f Authentic
│ 2022-04-21 19:08:13.443 │ clickhouse │ 283155 │ Debug │ │ HTTP-Session: 13e87050-7824-46b0-9bd5-29469a1b102f Authentic
│ 2022-04-21 19:08:13.443 │ clickhouse │ 283155 │ Debug │ │ HTTP-Session: 13e87050-7824-46b0-9bd5-29469a1b102f Creating
│ 2022-04-21 19:08:13.447 │ clickhouse │ 283155 │ Debug │ │ MemoryTracker: Peak memory usage (for query): 4.00 MiB.
│ 2022-04-21 19:08:13.447 │ clickhouse │ 283155 │ Debug │ │ HTTP-Session: 13e87050-7824-46b0-9bd5-29469a1b102f Destroyin
│ 2022-04-21 19:08:13.495 │ clickhouse │ 283155 │ Debug │ │ HTTP-Session: f7eb829f-7b3a-4c43-8a41-a2e6676177fb Authentic
│ 2022-04-21 19:08:13.495 │ clickhouse │ 283155 │ Debug │ │ HTTP-Session: f7eb829f-7b3a-4c43-8a41-a2e6676177fb Authentic
│ 2022-04-21 19:08:13.495 │ clickhouse │ 283155 │ Debug │ │ HTTP-Session: f7eb829f-7b3a-4c43-8a41-a2e6676177fb Creating
│ 2022-04-21 19:08:13.496 │ clickhouse │ 283155 │ Debug │ │ MemoryTracker: Peak memory usage (for query): 4.00 MiB.
│ 2022-04-21 19:08:13.496 │ clickhouse │ 283155 │ Debug │ │ HTTP-Session: f7eb829f-7b3a-4c43-8a41-a2e6676177fb Destroyin
└─────────────────────────┴────────────┴───────────┴──────────┴──────────┴─────────────────────────────────────────────────────────────
6 - Altinity Kubernetes Operator For ClickHouse®
Altinity Kubernetes Operator for ClickHouse® Documentation
https://github.com/Altinity/clickhouse-operator/blob/master/docs/README.md
7 - ClickHouse® and different filesystems
In general ClickHouse® should work with any POSIX-compatible filesystem.
- hard links and soft links support is mandatory.
- ClickHouse can use O_DIRECT mode to bypass the cache (and async io)
- ClickHouse can use renameat2 command for some atomic operations (not all the filesystems support that).
- depending on the schema and details of the usage the filesystem load can vary between the setup. The most natural load - is high throughput, with low or moderate IOPS.
- data is compressed in ClickHouse (LZ4 by default), while indexes / marks / metadata files - no. Enabling disk-level compression can sometimes improve the compression, but can affect read / write speed.
ext4
no issues, fully supported.
The minimum kernel version required is 3.15 (newer are recommended)
XFS
Performance issues reported by users, use on own risk. Old kernels are not recommended (4.0 or newer is recommended).
According to the users’ feedback, XFS behaves worse with ClickHouse under heavy load. We don’t have real proofs/benchmarks though, example reports:
- In GitHub there are complaints about XFS from Cloudflare.
- Recently my colleague discovered that two of ClickHouse servers perform worse in a cluster than others and they found that they accidentally set up those servers with XFS instead of Ext4.
- in the system journal you can sometimes see reports like ’task XYZ blocked for more than 120 seconds’ and stack trace pointing to XFS code (example: https://gist.github.com/filimonov/85b894268f978c2ccc18ea69bae5adbd )
- system goes to 99% io kernel under load sometimes.
- we have XFS, sometimes ClickHouse goes to “sleep” because XFS daemon is doing smth unknown
Maybe the above problem can be workaround by some tuning/settings, but so far we do not have a working and confirmed way to do this.
ZFS
Limitations exist, extra tuning may be needed, and having more RAM is recommended. Old kernels are not recommended.
Memory usage control - ZFS adaptive replacement cache (ARC) can take a lot of RAM. It can be the reason of out-of-memory issues when memory is also requested by the ClickHouse.
- It seems that the most important thing is zfs_arc_max - you just need to limit the maximum size of the ARC so that the sum of the maximum size of the arc + the CH itself does not exceed the size of the available RAM. For example, we set a limit of 80% RAM for ClickHouse and 10% for ARC. 10% will remain for the system and other applications
Tuning:
- another potentially interesting setting is primarycache=metadata, see benchmark example: https://www.ikus-soft.com/en/blog/2018-05-23-proxmox-primarycache-all-metadata/
- examples of tuning ZFS for MySQL https://wiki.freebsd.org/ZFSTuningGuide - perhaps some of this can also be useful (atime, recordsize) but everything needs to be carefully checked with benchmarks (I have no way).
- best practices: https://efim360.ru/zfs-best-practices-guide/
important note: In versions before 2.2 ZFS does not support the renameat2 command, which is used by the Atomic database engine, and
therefore some of the Atomic functionality will not be available.
In old versions of ClickHouse, you can face issues with the O_DIRECT mode.
Also there is a well-known (and controversial) Linus Torvalds opinion: “Don’t Use ZFS on Linux” [1] , [2] , [3] .
BTRFS
Not enough information. Some users report performance improvement for their use case.
ReiserFS
Not enough information.
Lustre
There are reports that some people successfully use it in their setups. A fast network is required.
There were some reports about data damage on the disks on older ClickHouse versions, which could be caused by the issues with O_DIRECT or async io support on Lustre.
NFS (and EFS)
According to the reports - it works, throughput depends a lot on the network speed. IOPS / number of file operations per seconds can be super low (due to the locking mechanism).
https://github.com/ClickHouse/ClickHouse/issues/31113
MooseFS
There are installations using that. No extra info.
GlusterFS
There are installations using that. No extra info.
Ceph
There are installations using that. Some information: https://github.com/ClickHouse/ClickHouse/issues/8315
8 - ClickHouse® Access Control and Account Management (RBAC)
Documentation https://clickhouse.com/docs/en/operations/access-rights/
Enable ClickHouse® RBAC and create admin user
Create an admin user like (root in MySQL or postgres in PostgreSQL) to do the DBA/admin ops in the user.xml file and set the access management property for the admin user
<clickhouse>
<users>
<default>
....
</default>
<admin>
<!--
Password could be specified in plaintext or in SHA256 (in hex format).
If you want to specify password in plaintext (not recommended), place it in 'password' element.
Example: <password>qwerty</password>.
Password could be empty.
If you want to specify SHA256, place it in 'password_sha256_hex' element.
Example: <password_sha256_hex>65e84be33532fb784c48129675f9eff3a682b27168c0ea744b2cf58ee02337c5</password_sha256_hex>
Restrictions of SHA256: impossibility to connect to ClickHouse using MySQL JS client (as of July 2019).
If you want to specify double SHA1, place it in 'password_double_sha1_hex' element.
Example: <password_double_sha1_hex>e395796d6546b1b65db9d665cd43f0e858dd4303</password_double_sha1_hex>
-->
<password></password>
<networks>
<ip>::/0</ip>
</networks>
<!-- Settings profile for user. -->
<profile>default</profile>
<!-- Quota for user. -->
<quota>default</quota>
<!-- Set This parameter to Enable RBAC
Admin user can create other users and grant rights to them. -->
<access_management>1</access_management>
</admin>
...
</clickhouse>
default user
As default is used for many internal and background operations, so it is not convenient to set it up with a password, because you would have to change it in many configs/parts. Best way to secure the default user is only allow localhost or trusted network connections like this in users.xml:
<clickhouse>
<users>
<default>
......
<networks>
<ip>127.0.0.1/8</ip>
<ip>10.10.10.0/24</ip>
</networks>
......
</default>
</clickhouse>
replication user
The replication user is defined by interserver_http_credential tag. It does not relate to a ClickHouse client credentials configuration. If this tag is ommited then authentication is not used during replication. Ports 9009 and 9010(tls) provide low-level data access between servers. This ports should not be accessible from untrusted networks. You can specify credentials for authentication between replicas. This is required when interserver_https_port is accessible from untrusted networks. You can do so by defining user and password to the interserver credentials. Then replication protocol will use basic access authentication when connecting by HTTP/HTTPS to other replicas:
<interserver_http_credentials>
<user>replication</user>
<password>password</password>
</interserver_http_credentials>
Create users and roles
Now we can setup users/roles using a generic best-practice approach for RBAC from other databases, like using roles, granting permissions to roles, creating users for different applications, etc…
Example: 3 roles (dba, dashboard_ro, ingester_rw)
create role dba on cluster '{cluster}';
grant all on *.* to dba on cluster '{cluster}';
create user `user1` identified by 'pass1234' on cluster '{cluster}';
grant dba to user1 on cluster '{cluster}';
create role dashboard_ro on cluster '{cluster}';
grant select on default.* to dashboard_ro on cluster '{cluster}';
grant dictGet on *.* to dashboard_ro on cluster '{cluster}';
create settings profile or replace profile_dashboard_ro on cluster '{cluster}'
settings max_concurrent_queries_for_user = 10 READONLY,
max_threads = 16 READONLY,
max_memory_usage_for_user = '30G' READONLY,
max_memory_usage = '30G' READONLY,
max_execution_time = 60 READONLY,
max_rows_to_read = 1000000000 READONLY,
max_bytes_to_read = '5000G' READONLY
TO dashboard_ro;
create user `dash1` identified by 'pass1234' on cluster '{cluster}';
grant dashboard_ro to dash1 on cluster '{cluster}';
create role ingester_rw on cluster '{cluster}';
grant select,insert on default.* to ingester_rw on cluster '{cluster}';
create settings profile or replace profile_ingester_rw on cluster '{cluster}'
settings max_concurrent_queries_for_user = 40 READONLY, -- user can run 40 queries (select, insert ...) simultaneously
max_threads = 10 READONLY, -- each query can use up to 10 cpu (READONLY means user cannot override a value)
max_memory_usage_for_user = '30G' READONLY, -- all queries of the user can use up to 30G RAM
max_memory_usage = '25G' READONLY, -- each query can use up to 25G RAM
max_execution_time = 200 READONLY, -- each query can executes no longer 200 seconds
max_rows_to_read = 1000000000 READONLY, -- each query can read up to 1 billion rows
max_bytes_to_read = '5000G' READONLY -- each query can read up to 5 TB from a MergeTree
TO ingester_rw;
create user `ingester_app1` identified by 'pass1234' on cluster '{cluster}';
grant ingester_rw to ingester_app1 on cluster '{cluster}';
check
$ clickhouse-client -u dash1 --password pass1234
create table test ( A Int64) Engine=Log;
DB::Exception: dash1: Not enough privileges
$ clickhouse-client -u user1 --password pass1234
create table test ( A Int64) Engine=Log;
Ok.
drop table test;
Ok.
$ clickhouse-client -u ingester_app1 --password pass1234
select count() from system.numbers limit 1000000000000;
DB::Exception: Received from localhost:9000. DB::Exception: Limit for rows or bytes to read exceeded, max rows: 1.00 billion
clean up
show profiles;
┌─name─────────────────┐
│ default │
│ profile_dashboard_ro │
│ profile_ingester_rw │
│ readonly │
└──────────────────────┘
drop profile if exists readonly on cluster '{cluster}';
drop profile if exists profile_dashboard_ro on cluster '{cluster}';
drop profile if exists profile_ingester_rw on cluster '{cluster}';
show roles;
┌─name─────────┐
│ dashboard_ro │
│ dba │
│ ingester_rw │
└──────────────┘
drop role if exists dba on cluster '{cluster}';
drop role if exists dashboard_ro on cluster '{cluster}';
drop role if exists ingester_rw on cluster '{cluster}';
show users;
┌─name──────────┐
│ dash1 │
│ default │
│ ingester_app1 │
│ user1 │
└───────────────┘
drop user if exists ingester_app1 on cluster '{cluster}';
drop user if exists user1 on cluster '{cluster}';
drop user if exists dash1 on cluster '{cluster}';
9 - Client Timeouts
Timeout settings are related to the client, server, and network. They can be tuned to solve sporadic timeout issues.
It’s important to understand that network devices (routers, NATs, load balancers ) could have their own timeouts. Sometimes, they won’t respect TCP keep-alive and close the session due to inactivity. Only application-level keepalives could prevent TCP sessions from closing.
Below are the settings that will work only if you set them in the default user profile. The problem is that they should be applied before the connection happens. And if you send them with a query/connection, it’s already too late:
SETTINGS
receive_timeout = 3600,
send_timeout = 3600,
http_receive_timeout = 3600,
http_send_timeout = 3600,
http_connection_timeout = 2
Those can be set on the query level (but in the profile, too):
SETTINGS
tcp_keep_alive_timeout = 3600,
--!!!send_progress_in_http_headers = 1,
http_headers_progress_interval_ms = 10000,
http_wait_end_of_query = 1,
max_execution_time = 3600
https://clickhouse.com/docs/en/integrations/language-clients/javascript#keep-alive-nodejs-only
send_progress_in_http_headers will not be applied in this way because here we can configure the JDBC driver’s client options only (this
), but there is an option called custom_settings (this
) that will apply custom ch query settings for every query before the actual connection is created. The correct JDBC connection string will look like this:
jdbc:clickhouse://"${clickhouse.host}"/"${clickhouse.db}"?ssl=true&socket_timeout=3600000&socket_keepalive=true&custom_settings=send_progress_in_http_headers=1
Description
http_send_timeout & send_timeout: The timeout for sending data to the socket. If the server takes longer than this value to send data, the connection will be terminated (i.e., when the server pushes data to the client, and the client is not reading that for some reason).http_receive_timeout & receive_timeout:The timeout for receiving data from the socket. If the server takes longer than this value to receive the entire request from the client, the connection will be terminated. This setting ensures that the server is not kept waiting indefinitely for slow or unresponsive clients (i.e., the server tries to get some data from the client, but the client does not send anything).http_connection_timeout & connect_timeout: Defines how long ClickHouse should wait when it connects to another server. If the connection cannot be established within this time frame, it will be terminated. This does not impact the clients which connect to ClickHouse using HTTP (it only matters when ClickHouse works as a TCP/HTTP client).keep_alive_timeout: This is for ‘Connection: keep-alive’ in HTTP 1.1, only for HTTP. It defines how long ClickHouse can wait for the next request in the same connection to arrive after serving the previous one. It does not lead to any SOCKET_TIMEOUT exception, just closes the socket if the client doesn’t start a new request after that time.
sync_request_timeout– timeout for server ping. Defaults to 5 seconds.
In some cases, if the data sync request time out, it may be caused by many different reasons, basically it shouldn’t take more than 5 seconds for synchronous request-result protocol call (like Ping or TableStatus) in most of the normal circumstances, thus if time out setting too long, eg. 5 minutes or longer than that, then you will run into more overall performance issues. This is not good for any application on the server.
How to check the current timeouts:
SELECT
name,
value,
changed,
description
FROM system.settings
WHERE (name ILIKE '%send_timeout%') OR (name ILIKE '%receive_timeout%') OR (name ILIKE '%keep_alive%') OR (name ILIKE '%_http_headers') OR (name ILIKE 'http_headers_progres_%') OR (name ILIKE 'http_connection_%')
10 - Compatibility layer for the Altinity Kubernetes Operator for ClickHouse®
It’s possible to expose clickhouse-server metrics in the style used by the Altinity Kubernetes Operator for ClickHouse®. It’s for the clickhouse-operator grafana dashboard.
CREATE VIEW system.operator_compatible_metrics
(
`name` String,
`value` Float64,
`help` String,
`labels` Map(String, String),
`type` String
) AS
SELECT
concat('chi_clickhouse_event_', event) AS name,
CAST(value, 'Float64') AS value,
description AS help,
map('hostname', hostName()) AS labels,
'counter' AS type
FROM system.events
UNION ALL
SELECT
concat('chi_clickhouse_metric_', metric) AS name,
CAST(value, 'Float64') AS value,
description AS help,
map('hostname', hostName()) AS labels,
'gauge' AS type
FROM system.metrics
UNION ALL
SELECT
concat('chi_clickhouse_metric_', metric) AS name,
value,
'' AS help,
map('hostname', hostName()) AS labels,
'gauge' AS type
FROM system.asynchronous_metrics
UNION ALL
SELECT
'chi_clickhouse_metric_MemoryDictionaryBytesAllocated' AS name,
CAST(sum(bytes_allocated), 'Float64') AS value,
'Memory size allocated for dictionaries' AS help,
map('hostname', hostName()) AS labels,
'gauge' AS type
FROM system.dictionaries
UNION ALL
SELECT
'chi_clickhouse_metric_LongestRunningQuery' AS name,
CAST(max(elapsed), 'Float64') AS value,
'Longest running query time' AS help,
map('hostname', hostName()) AS labels,
'gauge' AS type
FROM system.processes
UNION ALL
WITH
['chi_clickhouse_table_partitions', 'chi_clickhouse_table_parts', 'chi_clickhouse_table_parts_bytes', 'chi_clickhouse_table_parts_bytes_uncompressed', 'chi_clickhouse_table_parts_rows', 'chi_clickhouse_metric_DiskDataBytes', 'chi_clickhouse_metric_MemoryPrimaryKeyBytesAllocated'] AS names,
[uniq(partition), count(), sum(bytes), sum(data_uncompressed_bytes), sum(rows), sum(bytes_on_disk), sum(primary_key_bytes_in_memory_allocated)] AS values,
arrayJoin(arrayZip(names, values)) AS tpl
SELECT
tpl.1 AS name,
CAST(tpl.2, 'Float64') AS value,
'' AS help,
map('database', database, 'table', table, 'active', toString(active), 'hostname', hostName()) AS labels,
'gauge' AS type
FROM system.parts
GROUP BY
active,
database,
table
UNION ALL
WITH
['chi_clickhouse_table_mutations', 'chi_clickhouse_table_mutations_parts_to_do'] AS names,
[CAST(count(), 'Float64'), CAST(sum(parts_to_do), 'Float64')] AS values,
arrayJoin(arrayZip(names, values)) AS tpl
SELECT
tpl.1 AS name,
tpl.2 AS value,
'' AS help,
map('database', database, 'table', table, 'hostname', hostName()) AS labels,
'gauge' AS type
FROM system.mutations
WHERE is_done = 0
GROUP BY
database,
table
UNION ALL
WITH if(coalesce(reason, 'unknown') = '', 'detached_by_user', coalesce(reason, 'unknown')) AS detach_reason
SELECT
'chi_clickhouse_metric_DetachedParts' AS name,
CAST(count(), 'Float64') AS value,
'' AS help,
map('database', database, 'table', table, 'disk', disk, 'hostname', hostName()) AS labels,
'gauge' AS type
FROM system.detached_parts
GROUP BY
database,
table,
disk,
reason
ORDER BY name ASC
nano /etc/clickhouse-server/config.d/operator_metrics.xml
<clickhouse>
<http_handlers>
<rule>
<url>/metrics</url>
<methods>POST,GET</methods>
<handler>
<type>predefined_query_handler</type>
<query>SELECT * FROM system.operator_compatible_metrics FORMAT Prometheus</query>
<content_type>text/plain; charset=utf-8</content_type>
</handler>
</rule>
<defaults/>
<rule>
<url>/</url>
<methods>POST,GET</methods>
<headers><pragma>no-cache</pragma></headers>
<handler>
<type>dynamic_query_handler</type>
<query_param_name>query</query_param_name>
</handler>
</rule>
</http_handlers>
</clickhouse>
curl http://localhost:8123/metrics
# HELP chi_clickhouse_metric_Query Number of executing queries
# TYPE chi_clickhouse_metric_Query gauge
chi_clickhouse_metric_Query{hostname="LAPTOP"} 1
# HELP chi_clickhouse_metric_Merge Number of executing background merges
# TYPE chi_clickhouse_metric_Merge gauge
chi_clickhouse_metric_Merge{hostname="LAPTOP"} 0
# HELP chi_clickhouse_metric_PartMutation Number of mutations (ALTER DELETE/UPDATE)
# TYPE chi_clickhouse_metric_PartMutation gauge
chi_clickhouse_metric_PartMutation{hostname="LAPTOP"} 0
11 - How to convert uniqExact states to approximate uniq functions states
uniqExactState
uniqExactState is stored in two parts: a count of values in LEB128 format + list values without a delimiter.
Depending on the orignial datatype of the values to count, the datatype of the list values differ.
Numeric Values
In case of numeric values like UInt8, UInt64 etc. the representation of uniqExactState is just a simple array of the unique values encountered.
Therefore it is easy to recover the values from the state which have appeared:
┌─hex(uniqExactState(arrayJoin([1, 3])))─┐
│ 020103 │
└────────────────────────────────────────┘
02 01 03
^ ^ ^
LEB128 hex(1::UInt8) hex(3::UInt8)
┌─finalizeAggregation(CAST(unhex('020103'), 'AggregateFunction(groupArray, UInt8)'))─┐
│ [1,3] │
└────────────────────────────────────────────────────────────────────────────────────┘
String Values
Internal Representation
In case of values of data type String, ClickHouse® applies a hashing algorithm before storing the values into the internal array, otherwise the amount of space needed could get enormous.
┌─hex(uniqExactState(toString(arrayJoin([1]))))─┐
│ 01E2756D8F7A583CA23016E03447724DE7 │
└───────────────────────────────────────────────┘
01 E2756D8F7A583CA23016E03447724DE7
^ ^
LEB128 hash of '1'
┌─hex(uniqExactState(toString(arrayJoin([1, 2]))))───────────────────┐
│ 024809CB4528E00621CF626BE9FA14E2BFE2756D8F7A583CA23016E03447724DE7 │
└────────────────────────────────────────────────────────────────────┘
02 4809CB4528E00621CF626BE9FA14E2BF E2756D8F7A583CA23016E03447724DE7
^ ^ ^
LEB128 hash of '2' hash of '1'
So, our task is to find how we can generate such values by ourself, speak what hash function is used.
In case of String data type, it is just the simple sipHash128 function.
┌─hex(sipHash128(toString(2)))─────┬─hex(sipHash128(toString(1)))─────┐
│ 4809CB4528E00621CF626BE9FA14E2BF │ E2756D8F7A583CA23016E03447724DE7 │
└──────────────────────────────────┴──────────────────────────────────┘
Getting the Hash Values
The second task: now that we know how the state is formed, how can we demangle it and convert it into an Array of values.
Unfortunatelly it is not possible to get the original values back, as sipHash128 is a one way conversion, but at least we can try to get an Array of hashes.
Luckily for us, ClickHouse® use the exact same serialization (LEB128 + list of values) for Arrays (in this case if uniqExactState and Array are serialized into RowBinary format).
One way to “convert” the uniqExactState to an Array of hashes would be via an external helper
UDF function to do that conversion:
cat /etc/clickhouse-server/pipe_function.xml
<clickhouse>
<function>
<type>executable</type>
<execute_direct>0</execute_direct>
<name>pipe</name>
<return_type>Array(FixedString(16))</return_type>
<argument>
<type>String</type>
</argument>
<format>RowBinary</format>
<command>cat</command>
<send_chunk_header>0</send_chunk_header>
</function>
</clickhouse>
This UDF – pipe converts uniqExactState to the Array(FixedString(16)):
┌─arrayMap(x -> hex(x), pipe(uniqExactState(toString(arrayJoin([1, 2])))))──────────────┐
│ ['4809CB4528E00621CF626BE9FA14E2BF','E2756D8F7A583CA23016E03447724DE7'] │
└───────────────────────────────────────────────────────────────────────────────────────┘
This way only works if you have direct access to your ClickHouse® installation.
However if you are on a managed platform like Altinity.Cloud installing executable UDFs is typically not supported for security reasons.
Luckily we know that the internal representation of sipHash128 is FixedString(16) which has exactly 128 bit. UInt128 also takes up exactly 128 bit.
Therefore we can consider the uniqExactState(String) as a representation of Array(UInt128).
Again, we can therefore convert our state to an Array:
┌─arrayMap(lambda(tuple(x), hex(reinterpretAsFixedString(x))), finalizeAggregation(CAST(unhex(hex(uniqExactState(arrayJoin(['1', '2'])))), 'AggregateFunction(groupArray, UInt128)')))─┐
│ ['4809CB4528E00621CF626BE9FA14E2BF','E2756D8F7A583CA23016E03447724DE7'] │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
As you can see the Array is identical to the one we created with the pipe function.
Full Example of Conversion
And here is the full example, how you can convert uniqExactState(string) to any approximate uniq function like uniqState(string) or uniqCombinedState(string) by reinterpret and arrayReduce('func', [..]).
-- Generate demo with random data, uniqs are stored as heavy uniqExact
CREATE TABLE aggregates
(
`id` UInt32,
`uniqExact` AggregateFunction(uniqExact, String)
)
ENGINE = AggregatingMergeTree
ORDER BY id as
SELECT
number % 10000 AS id,
uniqExactState(toString(number))
FROM numbers(10000000)
GROUP BY id;
0 rows in set. Elapsed: 2.042 sec. Processed 10.01 million rows, 80.06 MB (4.90 million rows/s., 39.21 MB/s.)
-- Let's add a new columns to store optimized, approximate uniq & uniqCombined
ALTER TABLE aggregates
ADD COLUMN `uniq` AggregateFunction(uniq, FixedString(16)),
ADD COLUMN `uniqCombined` AggregateFunction(uniqCombined, FixedString(16));
-- Materialize values in the new columns
ALTER TABLE aggregates
UPDATE
uniqCombined = arrayReduce('uniqCombinedState', arrayMap(x -> reinterpretAsFixedString(x), finalizeAggregation(unhex(hex(uniqExact))::AggregateFunction(groupArray, UInt128)))),
uniq = arrayReduce('uniqState', arrayMap(x -> reinterpretAsFixedString(x), finalizeAggregation(unhex(hex(uniqExact))::AggregateFunction(groupArray, UInt128))))
WHERE 1
SETTINGS mutations_sync=2;
-- Check results, results are slighty different, because uniq & uniqCombined are approximate functions
SELECT
id % 20 AS key,
uniqExactMerge(uniqExact),
uniqCombinedMerge(uniqCombined),
uniqMerge(uniq)
FROM aggregates
GROUP BY key
┌─key─┬─uniqExactMerge(uniqExact)─┬─uniqCombinedMerge(uniqCombined)─┬─uniqMerge(uniq)─┐
│ 0 │ 500000 │ 500195 │ 500455 │
│ 1 │ 500000 │ 502599 │ 501549 │
│ 2 │ 500000 │ 498058 │ 504428 │
│ 3 │ 500000 │ 499748 │ 500195 │
│ 4 │ 500000 │ 500791 │ 500836 │
│ 5 │ 500000 │ 502430 │ 497558 │
│ 6 │ 500000 │ 500262 │ 501785 │
│ 7 │ 500000 │ 501514 │ 495758 │
│ 8 │ 500000 │ 500121 │ 498597 │
│ 9 │ 500000 │ 502173 │ 500455 │
│ 10 │ 500000 │ 499144 │ 498386 │
│ 11 │ 500000 │ 500525 │ 503139 │
│ 12 │ 500000 │ 503624 │ 497103 │
│ 13 │ 500000 │ 499986 │ 497992 │
│ 14 │ 500000 │ 502027 │ 494833 │
│ 15 │ 500000 │ 498831 │ 500983 │
│ 16 │ 500000 │ 501103 │ 500836 │
│ 17 │ 500000 │ 499409 │ 496791 │
│ 18 │ 500000 │ 501641 │ 502991 │
│ 19 │ 500000 │ 500648 │ 500881 │
└─────┴───────────────────────────┴─────────────────────────────────┴─────────────────┘
20 rows in set. Elapsed: 2.312 sec. Processed 10.00 thousand rows, 7.61 MB (4.33 thousand rows/s., 3.29 MB/s.)
Now, lets repeat the same insert, but in that case we will also populate uniq & uniqCombined with values converted via sipHash128 function.
If we did everything right, uniq counts will not change, because we inserted the exact same values.
INSERT INTO aggregates SELECT
number % 10000 AS id,
uniqExactState(toString(number)),
uniqState(sipHash128(toString(number))),
uniqCombinedState(sipHash128(toString(number)))
FROM numbers(10000000)
GROUP BY id;
0 rows in set. Elapsed: 5.386 sec. Processed 10.01 million rows, 80.06 MB (1.86 million rows/s., 14.86 MB/s.)
SELECT
id % 20 AS key,
uniqExactMerge(uniqExact),
uniqCombinedMerge(uniqCombined),
uniqMerge(uniq)
FROM aggregates
GROUP BY key
┌─key─┬─uniqExactMerge(uniqExact)─┬─uniqCombinedMerge(uniqCombined)─┬─uniqMerge(uniq)─┐
│ 0 │ 500000 │ 500195 │ 500455 │
│ 1 │ 500000 │ 502599 │ 501549 │
│ 2 │ 500000 │ 498058 │ 504428 │
│ 3 │ 500000 │ 499748 │ 500195 │
│ 4 │ 500000 │ 500791 │ 500836 │
│ 5 │ 500000 │ 502430 │ 497558 │
│ 6 │ 500000 │ 500262 │ 501785 │
│ 7 │ 500000 │ 501514 │ 495758 │
│ 8 │ 500000 │ 500121 │ 498597 │
│ 9 │ 500000 │ 502173 │ 500455 │
│ 10 │ 500000 │ 499144 │ 498386 │
│ 11 │ 500000 │ 500525 │ 503139 │
│ 12 │ 500000 │ 503624 │ 497103 │
│ 13 │ 500000 │ 499986 │ 497992 │
│ 14 │ 500000 │ 502027 │ 494833 │
│ 15 │ 500000 │ 498831 │ 500983 │
│ 16 │ 500000 │ 501103 │ 500836 │
│ 17 │ 500000 │ 499409 │ 496791 │
│ 18 │ 500000 │ 501641 │ 502991 │
│ 19 │ 500000 │ 500648 │ 500881 │
└─────┴───────────────────────────┴─────────────────────────────────┴─────────────────┘
20 rows in set. Elapsed: 3.318 sec. Processed 20.00 thousand rows, 11.02 MB (6.03 thousand rows/s., 3.32 MB/s.)
Let’s compare the data size, uniq won in this case, but check this article Functions to count uniqs
, mileage may vary.
optimize table aggregates final;
SELECT
column,
formatReadableSize(sum(column_data_compressed_bytes) AS size) AS compressed,
formatReadableSize(sum(column_data_uncompressed_bytes) AS usize) AS uncompressed
FROM system.parts_columns
WHERE (active = 1) AND (table LIKE 'aggregates') and column like '%uniq%'
GROUP BY column
ORDER BY size DESC;
┌─column───────┬─compressed─┬─uncompressed─┐
│ uniqExact │ 153.21 MiB │ 152.61 MiB │
│ uniqCombined │ 76.62 MiB │ 76.32 MiB │
│ uniq │ 38.33 MiB │ 38.18 MiB │
└──────────────┴────────────┴──────────────┘
12 - Custom Settings
Using custom settings in config
You can not use the custom settings in config file ‘as is’, because ClickHouse® don’t know which datatype should be used to parse it.
cat /etc/clickhouse-server/users.d/default_profile.xml
<?xml version="1.0"?>
<yandex>
<profiles>
<default>
<custom_data_version>1</custom_data_version> <!-- will not work! see below -->
</default>
</profiles>
</yandex>
That will end up with the following error:
2021.09.24 12:50:37.369259 [ 264905 ] {} <Error> ConfigReloader: Error updating configuration from '/etc/clickhouse-server/users.xml' config.: Code: 536. DB::Exception: Couldn't restore Field from dump: 1: while parsing value '1' for setting 'custom_data_version'. (CANNOT_RESTORE_FROM_FIELD_DUMP), Stack trace (when copying this message, always include the lines below):
0. DB::Exception::Exception(std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, int, bool) @ 0x9440eba in /usr/lib/debug/.build-id/ba/25f6646c3be7aa95f452ec85461e96178aa365.debug
1. DB::Field::restoreFromDump(std::__1::basic_string_view<char, std::__1::char_traits<char> > const&)::$_4::operator()() const @ 0x10449da0 in /usr/lib/debug/.build-id/ba/25f6646c3be7aa95f452ec85461e96178aa365.debug
2. DB::Field::restoreFromDump(std::__1::basic_string_view<char, std::__1::char_traits<char> > const&) @ 0x10449bf1 in /usr/lib/debug/.build-id/ba/25f6646c3be7aa95f452ec85461e96178aa365.debug
3. DB::BaseSettings<DB::SettingsTraits>::stringToValueUtil(std::__1::basic_string_view<char, std::__1::char_traits<char> > const&, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&) @ 0x1042e2bf in /usr/lib/debug/.build-id/ba/25f6646c3be7aa95f452ec85461e96178aa365.debug
4. DB::UsersConfigAccessStorage::parseFromConfig(Poco::Util::AbstractConfiguration const&) @ 0x1041a097 in /usr/lib/debug/.build-id/ba/25f6646c3be7aa95f452ec85461e96178aa365.debug
5. void std::__1::__function::__policy_invoker<void (Poco::AutoPtr<Poco::Util::AbstractConfiguration>, bool)>::__call_impl<std::__1::__function::__default_alloc_func<DB::UsersConfigAccessStorage::load(std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, std::__1::function<std::__1::shared_ptr<zkutil::ZooKeeper> ()> const&)::$_0, void (Poco::AutoPtr<Poco::Util::AbstractConfiguration>, bool)> >(std::__1::__function::__policy_storage const*, Poco::AutoPtr<Poco::Util::AbstractConfiguration>&&, bool) @ 0x1042e7ff in /usr/lib/debug/.build-id/ba/25f6646c3be7aa95f452ec85461e96178aa365.debug
6. DB::ConfigReloader::reloadIfNewer(bool, bool, bool, bool) @ 0x11caf54e in /usr/lib/debug/.build-id/ba/25f6646c3be7aa95f452ec85461e96178aa365.debug
7. DB::ConfigReloader::run() @ 0x11cb0f8f in /usr/lib/debug/.build-id/ba/25f6646c3be7aa95f452ec85461e96178aa365.debug
8. ThreadFromGlobalPool::ThreadFromGlobalPool<void (DB::ConfigReloader::*)(), DB::ConfigReloader*>(void (DB::ConfigReloader::*&&)(), DB::ConfigReloader*&&)::'lambda'()::operator()() @ 0x11cb19f1 in /usr/lib/debug/.build-id/ba/25f6646c3be7aa95f452ec85461e96178aa365.debug
9. ThreadPoolImpl<std::__1::thread>::worker(std::__1::__list_iterator<std::__1::thread, void*>) @ 0x9481f5f in /usr/lib/debug/.build-id/ba/25f6646c3be7aa95f452ec85461e96178aa365.debug
10. void* std::__1::__thread_proxy<std::__1::tuple<std::__1::unique_ptr<std::__1::__thread_struct, std::__1::default_delete<std::__1::__thread_struct> >, void ThreadPoolImpl<std::__1::thread>::scheduleImpl<void>(std::__1::function<void ()>, int, std::__1::optional<unsigned long>)::'lambda0'()> >(void*) @ 0x9485843 in /usr/lib/debug/.build-id/ba/25f6646c3be7aa95f452ec85461e96178aa365.debug
11. start_thread @ 0x9609 in /usr/lib/x86_64-linux-gnu/libpthread-2.31.so
12. __clone @ 0x122293 in /usr/lib/x86_64-linux-gnu/libc-2.31.so
(version 21.10.1.8002 (official build))
2021.09.29 11:36:07.722213 [ 2090 ] {} <Error> Application: DB::Exception: Couldn't restore Field from dump: 1: while parsing value '1' for setting 'custom_data_version'
To make it work you need to change it an the following way:
cat /etc/clickhouse-server/users.d/default_profile.xml
<?xml version="1.0"?>
<yandex>
<profiles>
<default>
<custom_data_version>UInt64_1</custom_data_version>
</default>
</profiles>
</yandex>
or
cat /etc/clickhouse-server/users.d/default_profile.xml
<?xml version="1.0"?>
<yandex>
<profiles>
<default>
<custom_data_version>'1'</custom_data_version>
</default>
</profiles>
</yandex>
The list of recognized prefixes is in the sources: https://github.com/ClickHouse/ClickHouse/blob/ea13a8b562edbc422c07b5b4ecce353f79b6cb63/src/Core/Field.cpp#L253-L270
13 - Description of asynchronous_metrics
CompiledExpressionCacheCount -- number or compiled cached expression (if CompiledExpressionCache is enabled)
jemalloc -- parameters of jemalloc allocator, they are not very useful, and not interesting
MarkCacheBytes / MarkCacheFiles -- there are cache for .mrk files (default size is 5GB), you can see is it use all 5GB or not
MemoryCode -- how much memory allocated for ClickHouse® executable
MemoryDataAndStack -- virtual memory allocated for data and stack
MemoryResident -- real memory used by ClickHouse ( the same as top RES/RSS)
MemoryShared -- shared memory used by ClickHouse
MemoryVirtual -- virtual memory used by ClickHouse ( the same as top VIRT)
NumberOfDatabases
NumberOfTables
ReplicasMaxAbsoluteDelay -- important parameter - replica max absolute delay in seconds
ReplicasMaxRelativeDelay -- replica max relative delay (from other replicas) in seconds
ReplicasMaxInsertsInQueue -- max number of parts to fetch for a single Replicated table
ReplicasSumInsertsInQueue -- sum of parts to fetch for all Replicated tables
ReplicasMaxMergesInQueue -- max number of merges in queue for a single Replicated table
ReplicasSumMergesInQueue -- total number of merges in queue for all Replicated tables
ReplicasMaxQueueSize -- max number of tasks for a single Replicated table
ReplicasSumQueueSize -- total number of tasks in replication queue
UncompressedCacheBytes/UncompressedCacheCells -- allocated memory for uncompressed cache (disabled by default)
Uptime -- uptime seconds
14 - ClickHouse® data/disk encryption (at rest)
Create folder
mkdir /data/clickhouse_encrypted
chown clickhouse.clickhouse /data/clickhouse_encrypted
Configure encrypted disk and storage
- https://clickhouse.com/docs/en/operations/storing-data/#encrypted-virtual-file-system
- https://clickhouse.com/docs/en/operations/server-configuration-parameters/settings/#server-settings-encryption
cat /etc/clickhouse-server/config.d/encrypted_storage.xml
<clickhouse>
<storage_configuration>
<disks>
<disk1>
<type>local</type>
<path>/data/clickhouse_encrypted/</path>
</disk1>
<encrypted_disk>
<type>encrypted</type>
<disk>disk1</disk>
<path>encrypted/</path>
<algorithm>AES_128_CTR</algorithm>
<key_hex id="0">00112233445566778899aabbccddeeff</key_hex>
<current_key_id>0</current_key_id>
</encrypted_disk>
</disks>
<policies>
<encrypted>
<volumes>
<encrypted_volume>
<disk>encrypted_disk</disk>
</encrypted_volume>
</volumes>
</encrypted>
</policies>
</storage_configuration>
</clickhouse>
systemctl restart clickhouse-server
select name, path, type, is_encrypted from system.disks;
┌─name───────────┬─path──────────────────────────────────┬─type──┬─is_encrypted─┐
│ default │ /var/lib/clickhouse/ │ local │ 0 │
│ disk1 │ /data/clickhouse_encrypted/ │ local │ 0 │
│ encrypted_disk │ /data/clickhouse_encrypted/encrypted/ │ local │ 1 │
└────────────────┴───────────────────────────────────────┴───────┴──────────────┘
select * from system.storage_policies;
┌─policy_name─┬─volume_name──────┬─volume_priority─┬─disks──────────────┬─volume_type─┬─max_data_part_size─┬─move_factor─┬─prefer_not_to_merge─┐
│ default │ default │ 1 │ ['default'] │ JBOD │ 0 │ 0 │ 0 │
│ encrypted │ encrypted_volume │ 1 │ ['encrypted_disk'] │ JBOD │ 0 │ 0 │ 0 │
└─────────────┴──────────────────┴─────────────────┴────────────────────┴─────────────┴────────────────────┴─────────────┴─────────────────────┘
Create table
CREATE TABLE bench_encrypted(c_int Int64, c_str varchar(255), c_float Float64)
engine=MergeTree order by c_int
settings storage_policy = 'encrypted';
cat /data/clickhouse_encrypted/encrypted/store/906/9061167e-d5f7-45ea-8e54-eb6ba3b678dc/format_version.txt
ENC�AdruM�˪h"��^�
Compare performance of encrypted and not encrypted tables
CREATE TABLE bench_encrypted(c_int Int64, c_str varchar(255), c_float Float64)
engine=MergeTree order by c_int
settings storage_policy = 'encrypted';
insert into bench_encrypted
select toInt64(cityHash64(number)), lower(hex(MD5(toString(number)))), number/cityHash64(number)*10000000
from numbers_mt(100000000);
0 rows in set. Elapsed: 33.357 sec. Processed 100.66 million rows, 805.28 MB (3.02 million rows/s., 24.14 MB/s.)
CREATE TABLE bench_unencrypted(c_int Int64, c_str varchar(255), c_float Float64)
engine=MergeTree order by c_int;
insert into bench_unencrypted
select toInt64(cityHash64(number)), lower(hex(MD5(toString(number)))), number/cityHash64(number)*10000000
from numbers_mt(100000000);
0 rows in set. Elapsed: 31.175 sec. Processed 100.66 million rows, 805.28 MB (3.23 million rows/s., 25.83 MB/s.)
select avg(c_float) from bench_encrypted;
1 row in set. Elapsed: 0.195 sec. Processed 100.00 million rows, 800.00 MB (511.66 million rows/s., 4.09 GB/s.)
select avg(c_float) from bench_unencrypted;
1 row in set. Elapsed: 0.150 sec. Processed 100.00 million rows, 800.00 MB (668.71 million rows/s., 5.35 GB/s.)
select sum(c_int) from bench_encrypted;
1 row in set. Elapsed: 0.281 sec. Processed 100.00 million rows, 800.00 MB (355.74 million rows/s., 2.85 GB/s.)
select sum(c_int) from bench_unencrypted;
1 row in set. Elapsed: 0.193 sec. Processed 100.00 million rows, 800.00 MB (518.88 million rows/s., 4.15 GB/s.)
set max_threads=1;
select avg(c_float) from bench_encrypted;
1 row in set. Elapsed: 0.934 sec. Processed 100.00 million rows, 800.00 MB (107.03 million rows/s., 856.23 MB/s.)
select avg(c_float) from bench_unencrypted;
1 row in set. Elapsed: 0.874 sec. Processed 100.00 million rows, 800.00 MB (114.42 million rows/s., 915.39 MB/s.)
read key_hex from environment variable
- https://clickhouse.com/docs/en/operations/server-configuration-parameters/settings/#server-settings-encryption
- https://serverfault.com/questions/413397/how-to-set-environment-variable-in-systemd-service
cat /etc/clickhouse-server/config.d/encrypted_storage.xml
<clickhouse>
<storage_configuration>
<disks>
<disk1>
<type>local</type>
<path>/data/clickhouse_encrypted/</path>
</disk1>
<encrypted_disk>
<type>encrypted</type>
<disk>disk1</disk>
<path>encrypted/</path>
<algorithm>AES_128_CTR</algorithm>
<key_hex from_env="DiskKey"/>
</encrypted_disk>
</disks>
<policies>
<encrypted>
<volumes>
<encrypted_volume>
<disk>encrypted_disk</disk>
</encrypted_volume>
</volumes>
</encrypted>
</policies>
</storage_configuration>
</clickhouse>
cat /etc/default/clickhouse-server
DiskKey=00112233445566778899aabbccddeeff
systemctl restart clickhouse-server
15 - DR two DC
Clickhouse uses Keeper (or ZooKeeper) to inform other cluster nodes about changes. Clickhouse nodes then fetch new parts directly from other nodes in the cluster. The Keeper cluster is a key for building a DR schema. You can consider Keeper a “true” cluster while clickhouse-server nodes as storage access instruments.
To implement a disaster recovery (DR) setup for ClickHouse across two physically separated data centers (A and B), with only one side active at a time, you can create a single ClickHouse cluster spanning both data centers. This setup will address data synchronization, replication, and coordination needs.
Cluster Configuration
- Create a single ClickHouse cluster with nodes in both data centers.
- Configure the appropriate number of replicas and shards based on your performance and redundancy requirements.
- Use ClickHouse Keeper or ZooKeeper for cluster coordination (see Keeper flavors discussion below).
Data Synchronization and Replication
- ClickHouse replicas operate in a master-master configuration, eliminating the need for a separate slave approach.
- Configure replicas across both data centers to ensure data synchronization.
- While both DCs have active replicas, consider DC B replicas as “passive” from the application’s perspective.
Example Configuration:
<remote_servers>
<company_cluster>
<shard>
<replica>
<host>ch1.dc-a.company.com</host>
</replica>
<replica>
<host>ch2.dc-a.company.com</host>
</replica>
<replica>
<host>ch1.dc-b.company.com</host>
</replica>
<replica>
<host>ch2.dc-b.company.com</host>
</replica>
</shard>
<!-- Add more shards as needed -->
</company_cluster>
</remote_servers>
Keeper Setup
- In the active data center (DC A):
- Deploy 3 active Keeper nodes
- In the passive data center (DC B):
- Deploy 1 Keeper node in observer role
Failover Process:
In case of a failover:
- Shut down the ClickHouse cluster in DC A completely
- Manually switch Keeper in DC B from observer to active participant (restart needed).
- Create two additional Keeper nodes (they will replicate the state automatically).
- Add two additional Keeper nodes to clickhouse configs
ClickHouse Keeper vs. ZooKeeper
While ClickHouse Keeper is generally preferable for very high-load scenarios, ZooKeeper remains a viable option for many deployments.
Considerations:
- ClickHouse Keeper is optimized for ClickHouse operations and can handle higher loads.
- ZooKeeper is well-established and works well for many clients.
The choice between ClickHouse Keeper and ZooKeeper is more about the overall system architecture and load patterns.
Configuration Synchronization
To keep configurations in sync:
- Use ON CLUSTER clause for DDL statements
- Store RBAC objects in Keeper
- Implement a configuration management system (e.g., Ansible, Puppet) to simultaneously apply changes to clickhouse configuration files in config.d
16 - How ALTERs work in ClickHouse®
How ALTERs work in ClickHouse®:
ADD (COLUMN/INDEX/PROJECTION)
Lightweight, will only change table metadata. So new entity will be added in case of creation of new parts during INSERT’s OR during merges of old parts.
In case of COLUMN, ClickHouse will calculate column value on fly in query context.
CREATE TABLE test_materialization
(
`key` UInt32,
`value` UInt32
)
ENGINE = MergeTree
ORDER BY key;
INSERT INTO test_materialization(key, value) SELECT 1, 1;
INSERT INTO test_materialization(key, value) SELECT 2, 2;
ALTER TABLE test_materialization ADD COLUMN inserted_at DateTime DEFAULT now();
SELECT key, inserted_at FROM test_materialization;
┌─key─┬─────────inserted_at─┐
│ 1 │ 2022-09-01 03:28:58 │
└─────┴─────────────────────┘
┌─key─┬─────────inserted_at─┐
│ 2 │ 2022-09-01 03:28:58 │
└─────┴─────────────────────┘
SELECT key, inserted_at FROM test_materialization;
┌─key─┬─────────inserted_at─┐
│ 1 │ 2022-09-01 03:29:11 │
└─────┴─────────────────────┘
┌─key─┬─────────inserted_at─┐
│ 2 │ 2022-09-01 03:29:11 │
└─────┴─────────────────────┘
Each query will return different inserted_at value, because each time now() function being executed.
INSERT INTO test_materialization(key, value) SELECT 3, 3;
SELECT key, inserted_at FROM test_materialization;
┌─key─┬─────────inserted_at─┐
│ 3 │ 2022-09-01 03:29:36 │ -- < This value was materialized during ingestion, that's why it's smaller than value for keys 1 & 2
└─────┴─────────────────────┘
┌─key─┬─────────inserted_at─┐
│ 1 │ 2022-09-01 03:29:53 │
└─────┴─────────────────────┘
┌─key─┬─────────inserted_at─┐
│ 2 │ 2022-09-01 03:29:53 │
└─────┴─────────────────────┘
OPTIMIZE TABLE test_materialization FINAL;
SELECT key, inserted_at FROM test_materialization;
┌─key─┬─────────inserted_at─┐
│ 1 │ 2022-09-01 03:30:52 │
│ 2 │ 2022-09-01 03:30:52 │
│ 3 │ 2022-09-01 03:29:36 │
└─────┴─────────────────────┘
SELECT key, inserted_at FROM test_materialization;
┌─key─┬─────────inserted_at─┐
│ 1 │ 2022-09-01 03:30:52 │
│ 2 │ 2022-09-01 03:30:52 │
│ 3 │ 2022-09-01 03:29:36 │
└─────┴─────────────────────┘
So, data inserted after addition of column can have lower inserted_at value then old data without materialization.
If you want to backpopulate data for old parts, you have multiple options:
MATERIALIZE (COLUMN/INDEX/PROJECTION) (PART[ITION ID] ‘’)
Will materialize this entity.
OPTIMIZE TABLE xxxx (PART[ITION ID] ‘’) (FINAL)
Will trigger merge, which will lead to materialization of all entities in affected parts.
ALTER TABLE xxxx UPDATE column_name = column_name WHERE 1;
Will trigger mutation, which will materialize this column.
DROP (COLUMN/INDEX/PROJECTION)
Lightweight, it’s only about changing of table metadata and removing corresponding files from filesystem. For Compact parts it will trigger merge, which can be heavy. issue
DROP DETACHED command
The DROP DETACHED command in ClickHouse® is used to remove parts or partitions that have previously been detached (i.e., moved to the detached directory and forgotten by the server). The syntax is:
Warning
Be careful before dropping any detached part or partition. Validate that data is no longer needed and keep a backup before running destructive commands.ALTER TABLE table_name [ON CLUSTER cluster] DROP DETACHED PARTITION|PART ALL|partition_expr
MODIFY COLUMN (DATE TYPE)
- Change column type in table schema.
- Schedule mutation to change type for old parts.
Mutations
Affected parts - parts with rows matching condition.
ALTER TABLE xxxxx DELETE WHERE column_1 = 1;
- Will overwrite all column data in affected parts.
- For all part(ition)s will create new directories on disk and write new data to them or create hardlinks if they untouched.
- Register new parts names in ZooKeeper.
ALTER TABLE xxxxx DELETE IN PARTITION ID ’’ WHERE column_1 = 1;
Will do the same but only for specific partition.
ALTER TABLE xxxxx UPDATE SET column_2 = column_2, column_3 = column_3 WHERE column_1 = 1;
- Will overwrite column_2, column_3 data in affected parts.
- For all part(ition)s will create new directories on disk and write new data to them or create hardlinks if they untouched.
- Register new parts names in ZooKeeper.
DELETE FROM xxxxx WHERE column_1 = 1;
- Will create & populate hidden boolean column in affected parts. (_row_exists column)
- For all part(ition)s will create new directories on disk and write new data to them or create hardlinks if they untouched.
- Register new parts names in ZooKeeper.
Despite that LWD mutations will not rewrite all columns, steps 2 & 3 in case of big tables can take significant time.
17 - How to recreate a table in case of total corruption of the replication queue
How to fix a replication using hard-reset way
- Find the best replica (replica with the most fresh/consistent) data.
- Backup the table
alter table mydatabase.mybadtable freeze; - Stop all applications!!! Stop ingestion. Stop queries - table will be empty for some time.
- Check that detached folder is empty or clean it.
SELECT concat('alter table ', database, '.', table, ' drop detached part \'', name, '\' settings allow_drop_detached=1;')
FROM system.detached_parts
WHERE (database = 'mydatabase') AND (table = 'mybadtable')
FORMAT TSVRaw;
- Make sure that detached folder is empty
select count() from system.detached_parts where database='mydatabase' and table ='mybadtable'; - Detach all parts (table will became empty)
SELECT concat('alter table ', database, '.', table, ' detach partition id \'', partition_id, '\';') AS detach
FROM system.parts
WHERE (active = 1) AND (database = 'mydatabase') AND (table = 'mybadtable')
GROUP BY detach
ORDER BY detach ASC
FORMAT TSVRaw;
- Make sure that table is empty
select count() from mydatabase.mybadtable; - Attach all parts back
SELECT concat('alter table ', database, '.', table, ' attach part \'', a.name, '\';')
FROM system.detached_parts AS a
WHERE (database = 'mydatabase') AND (table = 'mybadtable')
FORMAT TSVRaw;
- Make sure that data is consistent at all replicas
SELECT
formatReadableSize(sum(bytes)) AS size,
sum(rows),
count() AS part_count,
uniqExact(partition) AS partition_count
FROM system.parts
WHERE (active = 1) AND (database = 'mydatabase') AND (table = 'mybadtable');
18 - http handler example
http handler example (how to disable /play)
# cat /etc/clickhouse-server/config.d/play_disable.xml
<?xml version="1.0" ?>
<yandex>
<http_handlers>
<rule>
<url>/play</url>
<methods>GET</methods>
<handler>
<type>static</type>
<status>403</status>
<content_type>text/plain; charset=UTF-8</content_type>
<response_content></response_content>
</handler>
</rule>
<defaults/> <!-- handler to save default handlers ?query / ping -->
</http_handlers>
</yandex>
19 - Jemalloc heap profiling
Config
<!-- cat config.d/jemalloc_dict.xml -->
<clickhouse>
<dictionaries_config>/etc/clickhouse-server/config.d/*_dict.xml</dictionaries_config>
<http_handlers>
<rule>
<url>/pprof/heap</url>
<methods>GET,POST</methods>
<handler>
<type>static</type>
<response_content>file://jemalloc_clickhouse.heap</response_content>
</handler>
</rule>
<rule>
<url>/pprof/cmdline</url>
<methods>GET</methods>
<handler>
<type>predefined_query_handler</type>
<query>SELECT '/var/lib/clickhouse' FORMAT TSVRaw</query>
</handler>
</rule>
<rule>
<url>/pprof/symbol</url>
<methods>GET</methods>
<handler>
<type>predefined_query_handler</type>
<query>SELECT 'num_symbols: ' || count() FROM system.symbols FORMAT TSVRaw SETTINGS allow_introspection_functions = 1</query>
</handler>
</rule>
<rule>
<url>/pprof/symbol</url>
<methods>POST</methods>
<handler>
<type>predefined_query_handler</type>
<query>WITH arrayJoin(splitByChar('+', {_request_body:String})) as addr SELECT addr || ' ' || demangle(addressToSymbol(reinterpretAsUInt64(reverse(substr(unhex(addr),2))))) SETTINGS allow_introspection_functions = 1 FORMAT TSVRaw</query>
</handler>
</rule>
<defaults/>
</http_handlers>
<dictionary>
<name>jemalloc_ls</name>
<structure>
<key>
<attribute>
<name>id</name>
<type>String</type>
</attribute>
</key>
<attribute>
<name>file</name>
<type>String</type>
<null_value />
</attribute>
<attribute>
<name>size</name>
<type>UInt32</type>
<null_value />
</attribute>
<attribute>
<name>time</name>
<type>DateTime</type>
<null_value />
</attribute>
</structure>
<source>
<executable>
<command>for f in /tmp/jemalloc_clickhouse.*; do [ -f "$f" ] || continue; echo -e "$(basename "$f" | cut -d. -f2-3)\t$f\t$(stat -c%s "$f")\t$(stat -c%Y "$f")"; done</command>
<execute_direct>false</execute_direct>
<format>TSV</format>
</executable>
</source>
<layout>
<complex_key_direct/>
</layout>
<lifetime>300</lifetime>
</dictionary>
<dictionary>
<name>jemalloc_cp</name>
<structure>
<id>
<name>id</name>
<type>UInt32</type>
</id>
<attribute>
<name>status</name>
<type>UInt32</type>
<null_value />
</attribute>
</structure>
<source>
<executable>
<command>ver=${1:-$(head -n1 | tr -d "[:space:]")}; file=$(ls -t -- /tmp/jemalloc_clickhouse.*."$ver".heap 2>/dev/null | head -n1); if [ -n "$file" ] && cp -- "$file" /var/lib/clickhouse/user_files/jemalloc_clickhouse.heap; then printf '1\t\n'; else printf '0\t\n'; fi</command>
<execute_direct>false</execute_direct>
<format>TSV</format>
</executable>
</source>
<layout>
<direct/>
</layout>
<lifetime>300</lifetime>
</dictionary>
</clickhouse>
$ curl https://user:password@cluster.env.altinity.cloud:8443/pprof/cmdline
/var/lib/clickhouse
$ curl https://user:password@cluster.env.altinity.cloud:8443/pprof/symbol
num_symbols: 702648
$ curl -d '0x0F99B044+0x008512D0' https://user:password@cluster.env.altinity.cloud:8443/pprof/symbol
0x0F99B044 DB::StorageSystemFilesystemCache::getColumnsDescription()
0x008512D0 icudt75_dat
cluster :) SYSTEM JEMALLOC ENABLE PROFILE;
SYSTEM JEMALLOC ENABLE PROFILE
Ok.
0 rows in set. Elapsed: 0.270 sec.
cluster :) SELECT uniqExact(number) FROM numbers_mt(1000000000);
SELECT uniqExact(number)
FROM numbers_mt(1000000000)
┌─uniqExact(number)─┐
│ 1000000000 │ -- 1.00 billion
└───────────────────┘
1 row in set. Elapsed: 6.585 sec. Processed 1.00 billion rows, 8.00 GB (151.86 million rows/s., 1.21 GB/s.)
Peak memory usage: 25.19 GiB.
cluster :) SYSTEM JEMALLOC FLUSH PROFILE;
SYSTEM JEMALLOC FLUSH PROFILE
Ok.
0 rows in set. Elapsed: 0.272 sec.
cluster :) SELECT * FROM dictionary('jemalloc_ls');
SELECT *
FROM dictionary('jemalloc_ls')
┌─id─────┬─file──────────────────────────────┬───size─┬────────────────time─┐
│ │ │ 0 │ 1970-01-01 00:00:00 │
│ -e 8.0 │ /tmp/jemalloc_clickhouse.8.0.heap │ 108004 │ 2025-09-01 00:44:13 │
│ -e 8.1 │ /tmp/jemalloc_clickhouse.8.1.heap │ 111115 │ 2025-09-01 00:46:46 │
│ -e 8.2 │ /tmp/jemalloc_clickhouse.8.2.heap │ 128098 │ 2025-09-01 00:47:07 │
│ -e 8.3 │ /tmp/jemalloc_clickhouse.8.3.heap │ 123980 │ 2025-09-01 00:48:14 │
│ -e 8.4 │ /tmp/jemalloc_clickhouse.8.4.heap │ 124230 │ 2025-09-01 00:48:15 │
│ -e 8.5 │ /tmp/jemalloc_clickhouse.8.5.heap │ 117733 │ 2025-09-01 12:18:53 │
└────────┴───────────────────────────────────┴────────┴─────────────────────┘
7 rows in set. Elapsed: 0.021 sec.
cluster :) SELECT dictGet('jemalloc_cp', 'status', 4);
SELECT dictGet('jemalloc_cp', 'status', 4)
┌─dictGet('jem⋯status', 4)─┐
│ 0 │
└──────────────────────────┘
1 row in set. Elapsed: 0.014 sec.
$ jeprof --svg https://user:password@cluster.env.altinity.cloud:8443/pprof/heap > ./mem.svg
Fetching /pprof/heap profile from https://user:password@cluster.env.altinity.cloud:8443/pprof/heap to
/home/user/jeprof/clickhouse.1756728952.user.pprof.heap
Wrote profile to /home/user/jeprof/clickhouse.1756728952.user.pprof.heap
Dropping nodes with <= 90.7 MB; edges with <= 18.1 abs(MB)
cluster :) SELECT dictGet('jemalloc_cp', 'status', 5);
SELECT dictGet('jemalloc_cp', 'status', 5)
┌─dictGet('jem⋯status', 5)─┐
│ 0 │
└──────────────────────────┘
1 row in set. Elapsed: 0.014 sec.
$ jeprof --svg https://user:password@cluster.env.altinity.cloud:8443/pprof/heap --base /home/user/jeprof/clickhouse.1756728952.user.pprof.heap > ./mem_diff.svg
Fetching /pprof/heap profile from https://user:password@cluster.env.altinity.cloud:8443/pprof/heap to
/home/user/jeprof/clickhouse.1756729237.user.pprof.heap
Wrote profile to /home/user/jeprof/clickhouse.1756729237.user.pprof.heap
cluster :) SYSTEM JEMALLOC DISABLE PROFILE;
SYSTEM JEMALLOC DISABLE PROFILE
Ok.
0 rows in set. Elapsed: 0.271 sec.
20 - Logging
Q. I get errors:
File not found: /var/log/clickhouse-server/clickhouse-server.log.0.
File not found: /var/log/clickhouse-server/clickhouse-server.log.8.gz.
...
File not found: /var/log/clickhouse-server/clickhouse-server.err.log.0, Stack trace (when copying this message, always include the lines below):
0. Poco::FileImpl::handleLastErrorImpl(std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&) @ 0x11c2b345 in /usr/bin/clickhouse
1. Poco::PurgeOneFileStrategy::purge(std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&) @ 0x11c84618 in /usr/bin/clickhouse
2. Poco::FileChannel::log(Poco::Message const&) @ 0x11c314cc in /usr/bin/clickhouse
3. DB::OwnFormattingChannel::logExtended(DB::ExtendedLogMessage const&) @ 0x8681402 in /usr/bin/clickhouse
4. DB::OwnSplitChannel::logSplit(Poco::Message const&) @ 0x8682fa8 in /usr/bin/clickhouse
5. DB::OwnSplitChannel::log(Poco::Message const&) @ 0x8682e41 in /usr/bin/clickhouse
A. Check if you have proper permission to a log files folder, and enough disk space (& inode numbers) on the block device used for logging.
ls -la /var/log/clickhouse-server/
df -Th
df -Thi
Q. How to configure logging in ClickHouse®?
21 - High Memory Usage During Merge in system.metric_log
Overview
In recent versions of ClickHouse®, the merge process (part compaction) in the system.metric_log table can consume a large amount of memory.
The issue arises due to an unfortunate combination of settings, where:
- the merge is already large enough to produce wide parts,
- but not yet large enough to enable vertical merges.
This problem has become more pronounced in newer ClickHouse® versions because the system.metric_log table has expanded significantly — many new metrics were added, increasing the total number of columns.
Wide vs Compact — storage formats for table parts:
- Wide — each column is stored in a separate file (more efficient for large datasets).
- Compact — all data is stored in a single file (more efficient for small inserts).
Horizontal vs Vertical merge — algorithms for combining data during merges:
- Horizontal merge reads and merges all columns at once — meaning all files are opened simultaneously, and buffers are allocated for each column and each part.
- Vertical merge processes columns in batches — first merging only columns from
ORDER BY, then the rest one by one. This approach significantly reduces memory usage.
The most memory-intensive scenario is a horizontal merge of wide parts in a table with a large number of columns.
Demonstrating the Problem
The issue can be reproduced easily by adjusting a few settings:
ALTER TABLE system.metric_log MODIFY SETTING min_bytes_for_wide_part = 100;
OPTIMIZE TABLE system.metric_log FINAL;
Example log output:
[c9d66aa9f9d1] 2025.11.10 10:04:59.091067 [97] <Debug> MemoryTracker: Background process (mutate/merge) peak memory usage: 6.00 GiB.
The merge consumed 6 GB of memory — far too much for this table.
Vertical Merges Are Not Affected
If you explicitly force vertical merges, memory consumption normalizes, although the process becomes slightly slower:
ALTER TABLE system.metric_log MODIFY SETTING
min_bytes_for_wide_part = 100,
vertical_merge_algorithm_min_rows_to_activate = 1;
OPTIMIZE TABLE system.metric_log FINAL;
Example log output:
[c9d66aa9f9d1] 2025.11.10 10:06:14.575832 [97] <Debug> MemoryTracker: Background process (mutate/merge) peak memory usage: 13.98 MiB.
Now memory usage drops from 6 GB to only 14 MB.
Root Cause
The problem stems from the fact that:
- the threshold for enabling wide parts is configured in bytes (
min_bytes_for_wide_part); - while the threshold for enabling vertical merges is configured in rows (
vertical_merge_algorithm_min_rows_to_activate).
When a table contains very wide rows (many lightweight columns), this mismatch causes wide parts to appear too early, while vertical merges are triggered much later.
Default Settings
| Parameter | Value |
|---|---|
vertical_merge_algorithm_min_rows_to_activate | 131072 |
vertical_merge_algorithm_min_bytes_to_activate | 0 |
min_bytes_for_wide_part | 10485760 (10 MB) |
min_rows_for_wide_part | 0 |
The average row size in metric_log is approximately 2.8 KB, meaning wide parts are created after roughly:
10485760 / 2800 ≈ 3744 rows
Meanwhile, the vertical merge algorithm activates only after 131 072 rows — much later.
Possible Solutions
Increase
min_bytes_for_wide_partFor example, set it to at least2800 * 131072 ≈ 350 MB. This delays the switch to the wide format until vertical merges can also be used.Switch to a row-based threshold Use
min_rows_for_wide_partinstead ofmin_bytes_for_wide_part.Lower the threshold for vertical merges Reduce
vertical_merge_algorithm_min_rows_to_activate, or add a value forvertical_merge_algorithm_min_bytes_to_activate.
Example Local Fix for metric_log
Apply the configuration below, then restart ClickHouse® and drop the metric_log table (so it will be recreated with the updated settings):
<metric_log replace="1">
<database>system</database>
<table>metric_log</table>
<engine>
ENGINE = MergeTree
PARTITION BY (event_date)
ORDER BY (event_time)
TTL event_date + INTERVAL 14 DAY DELETE
SETTINGS min_bytes_for_wide_part = 536870912;
</engine>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</metric_log>
This configuration increases the threshold for wide parts to 512 MB, preventing premature switching to the wide format and reducing memory usage during merges.
The PR #89811 introduces a similar improvement.
Global Fix (All Tables)
In addition to metric_log, other tables may also be affected — particularly those with average row sizes greater than ~80 bytes and hundreds of columns.
<clickhouse>
<merge_tree>
<min_bytes_for_wide_part>0</min_bytes_for_wide_part> <!-- disable size based threshold for wide part -->
<min_rows_for_wide_part>131072</min_rows_for_wide_part> <!-- use row based instread, same value as vertical_merge_algorithm_min_rows_to_activate -->
</merge_tree>
</clickhouse>
These settings tell ClickHouse® to keep using compact parts longer and to enable the vertical merge algorithm simultaneously with the switch to the wide format, preventing sudden spikes in memory usage.
Caution: the vertical merge directly from compact parts to wide part can be VERY slow.
⚠️ Potential Risks and Trade-offs
Raising min_bytes_for_wide_part globally keeps more data in compact parts, which can both help and hurt depending on workload. Compact parts store all columns in a single data.bin file — this makes inserts much faster, especially for tables with many columns, since fewer files are created per part. It’s also a big advantage when storing data on S3 or other object storage, where every extra file adds latency and increases API call counts.
The trade-off is that this layout makes reads less efficient for column-selective queries. Reading one or two columns from a large compact part means scanning and decompressing shared blocks instead of isolated files. It can also reduce cache locality, slightly worsen compression (different columns compressed together), and make mutations or ALTERs more expensive because each change rewrites the entire part.
Lowering thresholds for vertical merges further decreases merge memory but may make the first merges slower, as they process columns sequentially. This configuration works best for wide, append-only tables or S3-based storage, while analytical tables with frequent updates or narrow schemas may perform better with defaults. If merge memory or S3 request overhead is your main concern, applying it globally is reasonable — otherwise, start with specific wide tables like system.metric_log, verify performance improvements, and expand gradually.
Additionally the the vertical merge directly from compact parts to wide part can be VERY slow.
✅ Summary
The root issue is a mismatch between byte-based and row-based thresholds for wide parts and vertical merges.
Aligning these values — by adjusting one or both parameters — stabilizes memory usage and prevents excessive RAM consumption during merges in system.metric_log and similar tables.
22 - Precreate parts using clickhouse-local
Precreate parts using clickhouse-local
the code below were testes on 23.3
## 1. Imagine we want to process this file:
cat <<EOF > /tmp/data.csv
1,2020-01-01,"String"
2,2020-02-02,"Another string"
3,2020-03-03,"One more string"
4,2020-01-02,"String for first partition"
EOF
rm -rf /tmp/precreate_parts
mkdir -p /tmp/precreate_parts
cd /tmp/precreate_parts
## 2. that is the metadata for the table we want to fill
## schema should match the schema of the table from server
## (the easiest way is just to copy it from the server)
## I've added sleepEachRow(0.5) here just to mimic slow insert
clickhouse-local --path=. --query="CREATE DATABASE local"
clickhouse-local --path=. --query="CREATE TABLE local.test (id UInt64, d Date, s String, x MATERIALIZED sleepEachRow(0.5)) Engine=MergeTree ORDER BY id PARTITION BY toYYYYMM(d);"
## 3. we can insert the input file into that table in different manners:
## a) just plain insert
cat /tmp/data.csv | clickhouse-local --path=. --query="INSERT INTO local.test FORMAT CSV"
## b) use File on the top of stdin (allows to tune the types)
clickhouse-local --path=. --query="CREATE TABLE local.stdin (id UInt64, d Date, s String) Engine=File(CSV, stdin)"
cat /tmp/data.csv | clickhouse-local --path=. --query="INSERT INTO local.test SELECT * FROM local.stdin"
## c) Instead of stdin you can use file engine
clickhouse-local --path=. --query "CREATE TABLE local.data_csv (id UInt64, d Date, s String) Engine=File(CSV, '/tmp/data.csv')"
clickhouse-local --path=. --query "INSERT INTO local.test SELECT * FROM local.data_csv"
# 4. now we have already parts created
clickhouse-local --path=. --query "SELECT _part,* FROM local.test ORDER BY id"
ls -la data/local/test/
# if needed we can even preprocess them more agressively - by doing OPTIMIZE ON that
clickhouse-local --path=. --query "OPTIMIZE TABLE local.test FINAL"
# that works, but clickhouse will keep inactive parts (those 'unmerged') in place.
ls -la data/local/test/
# we can use a bit hacky way to force it to remove inactive parts them
clickhouse-local --path=. --query "ALTER TABLE local.test MODIFY SETTING old_parts_lifetime=0, cleanup_delay_period=0, cleanup_delay_period_random_add=0"
## needed to give background threads time to clean inactive parts (max_block_size allows to stop that quickly if needed)
clickhouse-local --path=. --query "SELECT count() FROM numbers(100) WHERE sleepEachRow(0.1) SETTINGS max_block_size=1"
ls -la data/local/test/
clickhouse-local --path=. --query "SELECT _part,* FROM local.test ORDER BY id"
23 - Recovery after complete data loss
Atomic & Ordinary databases.
srv1 – good replica
srv2 – lost replica / we will restore it from srv1
test data (3 tables (atomic & ordinary databases))
srv1
create database testatomic on cluster '{cluster}' engine=Atomic;
create table testatomic.test on cluster '{cluster}' (A Int64, D Date, s String)
Engine = ReplicatedMergeTree('/clickhouse/{cluster}/tables/{database}/{table}','{replica}')
partition by toYYYYMM(D)
order by A;
insert into testatomic.test select number, today(), '' from numbers(1000000);
create database testordinary on cluster '{cluster}' engine=Ordinary;
create table testordinary.test on cluster '{cluster}' (A Int64, D Date, s String)
Engine = ReplicatedMergeTree('/clickhouse/{cluster}/tables/{database}/{table}','{replica}')
partition by toYYYYMM(D)
order by A;
insert into testordinary.test select number, today(), '' from numbers(1000000);
create table default.test on cluster '{cluster}' (A Int64, D Date, s String)
Engine = ReplicatedMergeTree('/clickhouse/{cluster}/tables/{database}/{table}','{replica}')
partition by toYYYYMM(D)
order by A;
insert into default.test select number, today(), '' from numbers(1000000);
destroy srv2
srv2
/etc/init.d/clickhouse-server stop
rm -rf /var/lib/clickhouse/*
generate script to re-create databases (create_database.sql).
srv1
$ cat /home/ubuntu/generate_schema.sql
SELECT concat('CREATE DATABASE "', name, '" ENGINE = ', engine, ' COMMENT \'', comment, '\';')
FROM system.databases
WHERE name NOT IN ('INFORMATION_SCHEMA', 'information_schema', 'system', 'default');
clickhouse-client < /home/ubuntu/generate_schema.sql > create_database.sql
check the result
$ cat create_database.sql
CREATE DATABASE "testatomic" ENGINE = Atomic COMMENT '';
CREATE DATABASE "testordinary" ENGINE = Ordinary COMMENT '';
transfer this create_database.sql to srv2 (scp / rsync)
make a copy of schema sql files (metadata_schema.tar)
srv1
cd /var/lib/clickhouse/
tar -cvhf /home/ubuntu/metadata_schema.tar metadata
-h - is important! (-h, –dereference Follow symlinks; archive and dump the files they point to.)
transfer this metadata_schema.tar to srv2 (scp / rsync)
create databases at srv2
srv2
/etc/init.d/clickhouse-server start
clickhouse-client < create_database.sql
/etc/init.d/clickhouse-server stop
create tables at srv2
srv2
cd /var/lib/clickhouse/
tar xkfv /home/ubuntu/metadata_schema.tar
sudo -u clickhouse touch /var/lib/clickhouse/flags/force_restore_data
/etc/init.d/clickhouse-server start
tar xkfv -k is important! To save folders/symlinks created with create database ( -k, –keep-old-files Don’t replace existing files when extracting )
check a recovery
srv2
SELECT count() FROM testatomic.test;
┌─count()─┐
│ 1000000 │
└─────────┘
SELECT count() FROM testordinary.test;
┌─count()─┐
│ 1000000 │
└─────────┘
SELECT count() FROM default.test;
┌─count()─┐
│ 1000000 │
└─────────┘
24 - How to Replicate ClickHouse RBAC Users and Grants with ZooKeeper/Keeper
How can I replicate CREATE USER and other RBAC commands automatically between servers?
This KB explains how to make SQL RBAC changes (CREATE USER, CREATE ROLE, GRANT, row policies, quotas, settings profiles, masking policies) automatically appear on all servers by storing access entities in ZooKeeper/ClickHouse Keeper.
Keeper below means either ClickHouse Keeper or ZooKeeper.
TL;DR:
- By default, SQL RBAC changes (
CREATE USER,GRANT, etc.) are local to each server. - Replicated access storage keeps RBAC entities in ZooKeeper/ClickHouse Keeper so changes automatically appear on all nodes.
- This guide shows how to configure replicated RBAC, validate it, and migrate existing users safely.
Before diving into the details, the core concept is:
- ClickHouse stores access entities in access storages configured by
user_directories. - By default, following the shared-nothing concept, SQL RBAC objects are local (
local_directory), so changes done on one node do not automatically appear on another node unless you run... ON CLUSTER .... - With
user_directories.replicated, ClickHouse stores the RBAC model in Keeper under a configured path (for example/clickhouse/access) and every node watches that path. - Each node maintains a local in-memory cache of replicated access entities and updates it via Keeper watch callbacks. As a result, access checks are fast and performed locally in memory, while RBAC modifications depend on Keeper availability and propagation.
The flow of this article:
- Why this model helps.
- How to configure it on a new cluster.
- How to validate and operate it.
- How to migrate existing RBAC safely.
- Advanced troubleshooting and internals.
1. ON CLUSTER vs Keeper-backed RBAC: when to use which
ON CLUSTER executes DDL on hosts that exist at execution time.
In practice, it fans out the query through the distributed DDL queue (also Keeper/ZooKeeper-dependent) to currently known cluster nodes.
It does not automatically replay old RBAC DDL for replicas/shards added later.
Keeper-backed RBAC differences:
- one shared RBAC state for the cluster;
- new servers read the same RBAC state when they join;
- no need to remember
ON CLUSTERfor every RBAC statement.
Mental model: Keeper-backed RBAC replicates access state, while ON CLUSTER fans out DDL to currently known nodes.
1.1 Pros and Cons of Keeper-backed RBAC
Pros:
- Single source of truth for RBAC across nodes.
- No manual file sync of
users.xml/ local access files. - Fast propagation through Keeper watch-driven refresh.
- Natural SQL RBAC workflow (
CREATE USER,GRANT,REVOKE, etc.). - Integrates with access-entity backup/restore.
Cons:
- Writes depend on Keeper availability.
CREATE/ALTER/DROP USER/ROLEandGRANT/REVOKEfail if Keeper is unavailable, while existing authentication/authorization may continue from already loaded cache until restart. - Operational complexity increases (Keeper health directly affects RBAC operations).
- Keeper data loss or accidental Keeper path damage can remove replicated RBAC state, and users may lose access; keep regular RBAC backups and test restore procedures.
- Can conflict with
ON CLUSTERif both mechanisms are used without guard settings. - Invalid/corrupted payload in Keeper can be skipped or be startup-fatal, depending on
throw_on_invalid_replicated_access_entities. - Very large RBAC sets (thousands of users/roles or very complex grants) can increase Keeper/watch pressure.
- If Keeper is unavailable during server startup and replicated RBAC storage is configured, the server may fail to start.
2. Configure Keeper-backed RBAC on a new cluster
user_directories is the ClickHouse server configuration section that defines:
- where access entities are read from (
users.xml, local SQL access files, Keeper, LDAP, etc.), - and in which order those sources are checked (precedence).
In short: it is the access-storage routing configuration for users/roles/policies/profiles/quotas.
Apply on every ClickHouse node:
<clickhouse>
<user_directories replace="replace">
<users_xml>
<path>/etc/clickhouse-server/users.xml</path>
</users_xml>
<replicated>
<zookeeper_path>/clickhouse/access/</zookeeper_path>
</replicated>
</user_directories>
</clickhouse>
Why replace="replace" matters:
- without
replace="replace", your fragment can be merged with defaults; - defaults include
local_directory, so SQL RBAC may still be written locally; - this can cause mixed behavior (some entities in Keeper, some in local files).
Recommended configuration for clusters using replicated RBAC:
users_xml: bootstrap/break-glass admin users and static defaults.replicated: all SQL RBAC objects (CREATE USER,CREATE ROLE,GRANT, policies, profiles, quotas).- avoid
local_directoryas an active writable SQL RBAC storage to prevent mixed write behavior.
2.1 Understand user_directories: defaults, precedence, coexistence
What can be configured in user_directories:
users_xml(read-only config users),local_directory(SQL users/roles in local files),replicated(SQL users/roles in Keeper),memory,ldap(read-only remote auth source).
Defaults if user_directories is not specified:
- ClickHouse uses legacy settings (
users_configandaccess_control_path). - In typical default deployments this means
users_xml+local_directory.
If user_directories is specified:
- ClickHouse uses storages from this section and ignores
users_config/access_control_pathpaths for access storages. - Order in
user_directoriesdefines precedence for lookup/auth.
When several storages coexist:
- reads/auth checks storages by precedence order;
CREATE USER/ROLE/...without explicitIN ...goes to the first writable target by that order (and may conflict with entities found in higher-precedence storages).
There is special syntax to target a storage explicitly:
CREATE USER my_user IDENTIFIED BY '***' IN replicated;
This is supported, but for access control we usually do not recommend mixing storages intentionally.
For sensitive access rights, a single source of truth (typically replicated) is safer and easier to operate.
3. Altinity Operator (CHI) configuration example
apiVersion: clickhouse.altinity.com/v1
kind: ClickHouseInstallation
metadata:
name: rbac-replicated
spec:
configuration:
files:
config.d/user_directories.xml: |
<clickhouse>
<user_directories replace="replace">
<users_xml>
<path>/etc/clickhouse-server/users.xml</path>
</users_xml>
<replicated>
<zookeeper_path>/clickhouse/access/</zookeeper_path>
</replicated>
</user_directories>
</clickhouse>
4. Validate the setup quickly
Check active storages and precedence:
SELECT name, type, params, precedence
FROM system.user_directories
ORDER BY precedence;
Expected result (values can vary by version/config; precedence values are relative and order matters):
name type precedence
users_xml users_xml 0
replicated replicated 1
Check where users are stored:
SELECT name, storage
FROM system.users
ORDER BY name;
Expected result for a SQL-created user:
name storage
kb_test replicated
Smoke test:
- On node A:
CREATE USER kb_test IDENTIFIED WITH no_password; - On node B:
SHOW CREATE USER kb_test; - On either node:
DROP USER kb_test;
RBAC changes usually propagate within milliseconds to seconds, depending on Keeper latency and cluster load.
Check Keeper data exists:
SELECT *
FROM system.zookeeper
WHERE path = '/clickhouse/access';
5. Handle existing ON CLUSTER RBAC scripts safely
There are two independent propagation mechanisms:
- Replicated access storage: Keeper-based replication of RBAC entities.
ON CLUSTER: query fan-out through the distributed DDL queue (also Keeper/ZooKeeper-dependent).
When replicated access storage is enabled, combining both can be redundant or problematic.
Recommended practice:
- Prefer RBAC SQL without
ON CLUSTER, or enable ignore mode:
SET ignore_on_cluster_for_replicated_access_entities_queries = 1;
With this setting, existing RBAC scripts containing ON CLUSTER can still be used safely: the clause is rewritten away for replicated-access queries.
For production, prefer configuring this in a profile (for example default in users.xml) rather than relying on session-level SET:
<clickhouse>
<profiles>
<default>
<ignore_on_cluster_for_replicated_access_entities_queries>1</ignore_on_cluster_for_replicated_access_entities_queries>
</default>
</profiles>
</clickhouse>
6. Migrate existing clusters/users
Switching to Keeper-backed RBAC should be treated as a storage migration..
Important: replay/restore RBAC on one node only. Objects are written to Keeper and then reflected on all nodes.
Key facts before migration:
- Changing
user_directoriesstorage or changingzookeeper_pathdoes not move existing SQL RBAC objects automatically. - If the path changes, old users and roles are not deleted but become effectively hidden from the new storage path.
zookeeper_pathcannot be changed at runtime via SQL.
Recommended high-level steps:
- Export/backup RBAC.
- Apply the new
user_directoriesconfig on all nodes. - Restart/reload as needed.
- Restore/replay RBAC.
- Validate from multiple nodes.
6.1 SQL-only migration (export/import RBAC DDL)
This path is useful when:
- RBAC DDL is already versioned in your repo, or
- you want to dump/replay access entities using SQL only.
- Replaying
SHOW ACCESSoutput is idempotent only if you handleIF NOT EXISTS/cleanup; otherwise prefer restoring into an empty RBAC namespace.
Recommended SQL-only flow:
- On the source, check where the entities are stored (local vs. replicated):
SELECT name, storage FROM system.users ORDER BY name;
SELECT name, storage FROM system.roles ORDER BY name;
SELECT name, storage FROM system.settings_profiles ORDER BY name;
SELECT name, storage FROM system.quotas ORDER BY name;
SELECT name, storage FROM system.row_policies ORDER BY name;
SELECT name, storage FROM system.masking_policies ORDER BY name;
- Export RBAC DDL from the source:
- simplest full dump:
SHOW ACCESS;
Save the output as SQL (for example rbac_dump.sql) in your repo/artifacts.
You can also export individual objects with SHOW CREATE USER/ROLE/... when needed.
- Switch the configuration to replicated
user_directorieson the target cluster and restart/reload. - Replay the exported SQL on one node (without
ON CLUSTERin replicated mode). - Validate from another node (
SHOW CREATE USER ...,SHOW GRANTS FOR ...).
6.2 Migration with clickhouse-backup (--rbac-only)
# backup local RBAC users/roles/etc.
clickhouse-backup create --rbac --rbac-only users_bkp_20260304
# restore (on node configured with replicated user directory)
clickhouse-backup restore --rbac-only users_bkp_20260304
Important:
- this applies to SQL/RBAC users (created with
CREATE USER ...,CREATE ROLE ..., etc.); - if your users are in
users.xml, those are config-based (--configs) and this is not an automatic local->replicated RBAC conversion. - run restore on one node only; entities will be replicated through Keeper.
- If
clickhouse-backupis configured withuse_embedded_backup_restore: true, it delegates to SQLBACKUP/RESTOREand follows embedded rules. (see below).
6.3 Migration with embedded SQL BACKUP/RESTORE
BACKUP
TABLE system.users,
TABLE system.roles,
TABLE system.row_policies,
TABLE system.quotas,
TABLE system.settings_profiles,
TABLE system.masking_policies
TO <backup_destination>;
-- after switching config
RESTORE
TABLE system.users,
TABLE system.roles,
TABLE system.row_policies,
TABLE system.quotas,
TABLE system.settings_profiles,
TABLE system.masking_policies
FROM <backup_destination>;
allow_backup behavior for embedded SQL backup/restore:
- Storage-level flag in
user_directories(<replicated>,<local_directory>,<users_xml>) controls whether that storage participates in backup/restore. - Entity-level setting
allow_backup(for users/roles/settings profiles) can exclude specific RBAC objects from backup.
Defaults in ClickHouse code:
users_xml:allow_backup = falseby default.local_directory:allow_backup = trueby default.replicated:allow_backup = trueby default.
Operational implication:
- If you disable
allow_backupfor replicated storage, embeddedBACKUP TABLE system.users ...may skip those entities (or fail if no backup-allowed access storage remains).
7. Troubleshooting: common support issues
| Symptom | Typical root cause | What to do |
|---|---|---|
| User created on node A is missing on node B | RBAC still stored in local_directory | Verify system.user_directories; ensure replicated is configured on all nodes and active |
| RBAC objects “disappeared” after config change/restart | zookeeper_path or storage source changed | Restore from backup or recreate RBAC in the new storage; keep path stable |
| New replica has no historical users/roles | Team used only ... ON CLUSTER ... before scaling | Enable Keeper-backed RBAC so new nodes load shared state |
CREATE USER ... ON CLUSTER throws “already exists in replicated” | Query fan-out + replicated storage both applied | Remove ON CLUSTER for RBAC or enable ignore_on_cluster_for_replicated_access_entities_queries |
CREATE USER/GRANT fails with Keeper/ZooKeeper error | Keeper unavailable or connection lost | Check system.zookeeper_connection, system.zookeeper_connection_log, and server logs |
RBAC writes still go to local_directory even though replicated is configured | local_directory remains the first writable storage | Use user_directories replace="replace" and avoid writable local SQL storage in front of replicated |
| Server does not start when Keeper is down; no one can log in | Replicated access storage needs Keeper during initialization | Restore Keeper first, then restart; if needed use a temporary fallback config and keep a break-glass users.xml admin |
| Startup fails (or users are skipped) because of invalid RBAC payload in Keeper | Corrupted/invalid replicated entity and strict validation mode | Use throw_on_invalid_replicated_access_entities deliberately: true fail-fast, false skip+log; fix bad Keeper payload before re-enabling strict mode |
| Two independent clusters unexpectedly share the same users/roles | Both clusters point to the same Keeper ensemble and the same zookeeper_path | Use unique RBAC paths per cluster (recommended), or isolate with Keeper chroot (requires Keeper metadata repopulation/migration) |
| Cannot change RBAC keeper path with SQL at runtime | Not supported by design | Change config + controlled migration/restore |
| Trying to “sync” RBAC between independent clusters by pointing to another path | Wrong migration model | Use backup/restore or SQL export/import, not ad hoc path switching |
| Authentication errors from app/job, but local tests work | Network/IP/user mismatch, not replication itself | Check system.query_log and source IP; verify user host restrictions |
| Short window where user seems present/absent via load balancer | Propagation + node routing timing | Validate directly on each node; avoid assuming LB view is instantly consistent |
Server fails after aggressive user_directories replacement | Required base users/profiles missing in config | Keep users_xml (or equivalent base definitions) intact |
8. Operational guardrails for production
- Keep the same
user_directoriesconfig on all nodes. - Keep
zookeeper_pathunique per cluster/tenant. - Use a dedicated admin user for provisioning; avoid using
defaultfor automation. - Track configuration rollouts (who/when/what) to avoid hidden behavior changes.
- Treat Keeper health as part of access-management SLO.
- Plan RBAC backup/restore before changing storage path or cluster topology.
9. Observability and debugging signals
9.1 Check Keeper connectivity
SELECT * FROM system.zookeeper_connection;
SELECT * FROM system.zookeeper_connection_log ORDER BY event_time DESC LIMIT 100;
SELECT * FROM system.zookeeper WHERE path = '/clickhouse/access';
9.2 Relevant server log patterns
You can find feature-related lines in the log, by those patterns:
Access(replicated)
ZooKeeperReplicator
Can't have Replicated access without ZooKeeper
ON CLUSTER clause was ignored for query
9.3 Force RBAC reload
Force access reload:
SYSTEM RELOAD USERS;
10. Keeper path structure and semantics (advanced)
The following details are useful for advanced debugging or when inspecting Keeper paths manually.
If zookeeper_path=/clickhouse/access:
/clickhouse/access
/uuid/<entity_uuid> -> serialized ATTACH statements for one entity
/U/<escaped_name> -> user name -> UUID
/R/<escaped_name> -> role name -> UUID
/S/<escaped_name> -> settings profile name -> UUID
/P/<escaped_name> -> row policy name -> UUID
/Q/<escaped_name> -> quota name -> UUID
/M/<escaped_name> -> masking policy name -> UUID
When these paths are accessed:
- startup/reconnect: ClickHouse syncs Keeper, creates roots if missing, loads all entities;
CREATE/ALTER/DROPRBAC SQL: updatesuuidand type/name index nodes in Keeper transactions;- runtime: watch callbacks refresh changed entities into local in-memory mirror.
11. Low-level internals
Advanced note:
each ClickHouse node keeps a local in-memory cache of all replicated access entities;
cache is updated from Keeper watch notifications (list/entity watches), so auth/lookup paths use local memory and not direct Keeper reads on each request.
watch patterns used:
- list watch on
/uuidchildren for create/delete detection; - per-entity watch on
/uuid/<id>for payload changes.
- list watch on
thread model:
- dedicated watcher thread (
runWatchingThread); - on errors: reset cached Keeper client, sleep, retry;
- after refresh: send
AccessChangesNotifiernotifications.
- dedicated watcher thread (
cache layers:
- primary cache:
MemoryAccessStorageinside replicated access storage; - higher-level caches in
AccessControl(RoleCache,RowPolicyCache,QuotaCache,SettingsProfilesCache) are updated/invalidated via access change notifications.
- primary cache:
Read path is memory-backed (
MemoryAccessStoragemirror), not direct Keeper reads per query.Write path requires Keeper availability; if Keeper is down, RBAC writes fail while some reads can continue from loaded state.
Insert target is selected by storage order and writeability in
MultipleAccessStorage; this is why leftoverlocal_directorycan hijack SQL user creation.ignore_on_cluster_for_replicated_access_entities_queriesis implemented as AST rewrite that removesON CLUSTERfor access queries when replicated access storage is enabled.
12. Version and history highlights
| Date | Change | Why it matters |
|---|---|---|
| 2021-07-21 | ReplicatedAccessStorage introduced (e33a2bf7bc9, PR #27426) | First Keeper-backed RBAC replication |
| 2023-08-18 | Ignore ON CLUSTER for replicated access entities (14590305ad0, PR #52975) | Reduced duplicate/overlap behavior |
| 2023-12-12 | Extended ignore behavior to GRANT/REVOKE (b33f1245559, PR #57538) | Fixed common operational conflict with grants |
| 2025-06-03 | Keeper replication logic extracted to ZooKeeperReplicator (39eb90b73ef, PR #81245) | Cleaner architecture, shared replication core |
| 2026-01-24 | Optional strict mode on invalid replicated entities (3d654b79853) | Lets operators fail fast on corrupted Keeper payloads |
13. Code references for deep dives
src/Access/AccessControl.cppsrc/Access/MultipleAccessStorage.cppsrc/Access/ReplicatedAccessStorage.cppsrc/Access/ZooKeeperReplicator.cppsrc/Interpreters/removeOnClusterClauseIfNeeded.cppsrc/Access/IAccessStorage.cppsrc/Backups/BackupCoordinationOnCluster.cppsrc/Backups/RestoreCoordinationOnCluster.cpptests/integration/test_replicated_users/test.pytests/integration/test_replicated_access/test_invalid_entity.py
25 - Replication: Can not resolve host of another ClickHouse® server
Symptom
When configuring Replication the ClickHouse® cluster nodes are experiencing communication issues, and an error message appears in the log that states that the ClickHouse host cannot be resolved.
<Error> DNSResolver: Cannot resolve host (xxxxx), error 0: DNS error.
auto DB::StorageReplicatedMergeTree::processQueueEntry(ReplicatedMergeTreeQueue::SelectedEntryPtr)::(anonymous class)::operator()(DB::StorageReplicatedMergeTree::LogEntryPtr &) const: Code: 198. DB::Exception: Not found address of host: xxxx. (DNS_ERROR),
Cause:
The error message indicates that the host name of the one of the nodes of the cluster cannot be resolved by other cluster members, causing communication issues between the nodes.
Each node in the replication setup pushes its Fully Qualified Domain Name (FQDN) to Zookeeper, and if other nodes cannot access it using its FQDN, this can cause issues.
Action:
There are two possible solutions to this problem:
- Change the FQDN to allow other nodes to access it. This solution can also help to keep the environment more organized. To do this, use the following command to edit the hostname file:
sudo vim /etc/hostname
Or use the following command to change the hostname:
sudo hostnamectl set-hostname ...
- Use the configuration parameter
<interserver_http_host>to specify the IP address or hostname that the nodes can use to communicate with each other. This solution can have some issues, such as the one described in this link: https://github.com/ClickHouse/ClickHouse/issues/2154 . To configure this parameter, refer to the documentation for more information: https://clickhouse.com/docs/en/operations/server-configuration-parameters/settings/#interserver-http-host .
26 - source parts size is greater than the current maximum
Symptom
I see messages like: source parts size (...) is greater than the current maximum (...) in the logs and/or inside system.replication_queue
Cause
Usually that means that there are already few big merges running. You can see the running merges using the query:
SELECT * FROM system.merges
That logic is needed to prevent picking a log of huge merges simultaneously (otherwise they will take all available slots and ClickHouse® will not be able to do smaller merges, which usually are important for keeping the number of parts stable).
Action
It is normal to see those messages on some stale replicas. And it should be resolved automatically after some time. So just wait & monitor system.merges & system.replication_queue tables, it should be resolved by it’s own.
If it happens often or don’t resolves by it’s own during some longer period of time, it could be caused by:
- increased insert pressure
- disk issues / high load (it works slow, not enough space etc.)
- high CPU load (not enough CPU power to catch up with merges)
- issue with table schemas leading to high merges pressure (high / increased number of tables / partitions / etc.)
Start from checking dmesg / system journals / ClickHouse monitoring to find the anomalies.
27 - Successful ClickHouse® deployment plan
Successful ClickHouse® deployment plan
Stage 0. Build POC
- Install single node ClickHouse
- Start with creating a single table (the biggest one), use MergeTree engine. Create ‘some’ schema (most probably it will be far from optimal). Prefer denormalized approach for all immutable dimensions, for mutable dimensions - consider dictionaries.
- Load some amount of data (at least 5 Gb, and 10 mln rows) - preferable the real one, or as close to real as possible. Usually the simplest options are either through CSV / TSV files (or
insert into clickhouse_table select * FROM mysql(...) where ...) - Create several representative queries.
- Check the columns cardinality, and appropriate types, use minimal needed type
- Review the partition by and order by. https://kb.altinity.com/engines/mergetree-table-engine-family/pick-keys/
- Create the schema(s) with better/promising order by / partitioning, load data in. Pick the best schema.
- consider different improvements of particular columns (codecs / better data types etc.) https://kb.altinity.com/altinity-kb-schema-design/codecs/altinity-kb-how-to-test-different-compression-codecs/
- If the performance of certain queries is not enough - consider using PREWHERE / skipping indexes
- Repeat 2-9 for next big table(s). Avoid scenarios when you need to join big tables.
- Pick the clients library for you programming language (the most mature are python / golang / java / c++), build some pipeline - for inserts (low QPS, lot of rows in singe insert, check acknowledgements & retry the same block on failures), ETLs if needed, some reporting layer (https://kb.altinity.com/altinity-kb-integrations/bi-tools/ )
Stage 1. Planning the production setup
- Collect more data / estimate insert speed, estimate the column sizes per day / month.
- Measure the speed of queries
- Consider improvement using materialized views / projections / dictionaries.
- Collect requirements (ha / number of simultaneous queries / insert pressure / ’exactly once’ etc)
- Do a cluster sizing estimation, plan the hardware
- plan the network, if needed - consider using LoadBalancers etc.
- If you need sharding - consider different sharding approaches.
Stage 2. Preprod setup & development
- Install ClickHouse in cluster - several nodes / VMs + zookeeper
- https://kb.altinity.com/altinity-kb-setup-and-maintenance/cluster-production-configuration-guide/cluster-configuration-process/
- https://kb.altinity.com/altinity-kb-setup-and-maintenance/altinity-kb-zookeeper/altinity-kb-proper-setup/
- https://kb.altinity.com/altinity-kb-setup-and-maintenance/altinity-kb-zookeeper/install_ubuntu/
- Create good config & automate config / os / restarts (ansible / puppet etc)
- https://kb.altinity.com/altinity-kb-setup-and-maintenance/altinity-kb-settings-to-adjust/
- for docker: https://kb.altinity.com/altinity-kb-setup-and-maintenance/altinity-kb-clickhouse-in-docker/
- for k8s, use the Altinity Kubernetes Operator for ClickHouse OR https://kb.altinity.com/altinity-kb-kubernetes/altinity-kb-possible-issues-with-running-clickhouse-in-k8s/
- Set up monitoring / log processing / alerts etc.
- Set up users.
- Think of schema management. Deploy the schema.
- Design backup / failover strategies:
- Develop pipelines / queries, create test suite, CI/CD
- Do benchmark / stress tests
- Test configuration changes / server restarts / failovers / version upgrades
- Review the security topics (tls, limits / restrictions, network, passwords)
- Document the solution for operations
Stage 3. Production setup
- Deploy the production setup (consider also canary / blue-greed deployments etc)
- Schedule ClickHouse upgrades every 6 to 12 months (if possible)
28 - sysall database (system tables on a cluster level)
Requirements
The idea is that you have a macros cluster with cluster name.
For example you have a cluster named production and this cluster includes all ClickHouse® nodes.
$ cat /etc/clickhouse-server/config.d/clusters.xml
<?xml version="1.0" ?>
<yandex>
<remote_servers>
<production>
<shard>
...
And you need to have a macro cluster set to production:
cat /etc/clickhouse-server/config.d/macros.xml
<?xml version="1.0" ?>
<yandex>
<macros>
<cluster>production</cluster>
<replica>....</replica>
....
</macros>
</yandex>
Now you should be able to query all nodes using clusterAllReplicas:
SELECT
hostName(),
FQDN(),
materialize(uptime()) AS uptime
FROM clusterAllReplicas('{cluster}', system.one)
SETTINGS skip_unavailable_shards = 1
┌─hostName()─┬─FQDN()──────────────┬──uptime─┐
│ chhost1 │ chhost1.localdomain │ 1071574 │
│ chhost2 │ chhost2.localdomain │ 1071517 │
└────────────┴─────────────────────┴─────────┘
skip_unavailable_shards is necessary to query a system with some nodes are down.
Script to create DB objects
clickhouse-client -q 'show tables from system'> list
for i in `cat list`; do echo "CREATE OR REPLACE VIEW sysall."$i" as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system."$i") SETTINGS skip_unavailable_shards = 1;"; done;
CREATE DATABASE sysall;
CREATE OR REPLACE VIEW sysall.cluster_state AS
SELECT
shard_num,
replica_num,
host_name,
host_address,
port,
errors_count,
uptime,
if(uptime > 0, 'UP', 'DOWN') AS node_state
FROM system.clusters
LEFT JOIN
(
SELECT
replaceRegexpOne(hostName(),'-(\d+)-0$','-\1') AS host_name, -- remove trailing 0
FQDN() AS fqdn,
materialize(uptime()) AS uptime
FROM clusterAllReplicas('{cluster}', system.one)
) as hosts_info USING (host_name)
WHERE cluster = getMacro('cluster')
SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.asynchronous_inserts as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.asynchronous_inserts) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.asynchronous_metrics as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.asynchronous_metrics) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.backups as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.backups) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.clusters as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.clusters) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.columns as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.columns) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.current_roles as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.current_roles) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.data_skipping_indices as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.data_skipping_indices) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.databases as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.databases) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.detached_parts as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.detached_parts) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.dictionaries as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.dictionaries) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.disks as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.disks) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.distributed_ddl_queue as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.distributed_ddl_queue) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.distribution_queue as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.distribution_queue) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.dropped_tables as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.dropped_tables) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.enabled_roles as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.enabled_roles) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.errors as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.errors) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.events as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.events) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.filesystem_cache as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.filesystem_cache) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.grants as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.grants) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.jemalloc_bins as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.jemalloc_bins) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.macros as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.macros) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.merge_tree_settings as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.merge_tree_settings) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.merges as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.merges) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.metrics as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.metrics) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.moves as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.moves) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.mutations as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.mutations) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.named_collections as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.named_collections) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.parts as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.parts) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.parts_columns as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.parts_columns) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.privileges as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.privileges) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.processes as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.processes) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.projection_parts as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.projection_parts) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.projection_parts_columns as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.projection_parts_columns) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.query_cache as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.query_cache) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.query_log as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.query_log) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.quota_limits as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.quota_limits) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.quota_usage as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.quota_usage) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.quotas as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.quotas) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.quotas_usage as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.quotas_usage) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.replicas as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.replicas) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.replicated_fetches as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.replicated_fetches) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.replicated_merge_tree_settings as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.replicated_merge_tree_settings) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.replication_queue as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.replication_queue) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.role_grants as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.role_grants) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.roles as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.roles) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.row_policies as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.row_policies) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.server_settings as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.server_settings) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.settings as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.settings) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.settings_profile_elements as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.settings_profile_elements) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.settings_profiles as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.settings_profiles) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.storage_policies as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.storage_policies) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.tables as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.tables) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.user_directories as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.user_directories) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.user_processes as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.user_processes) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.users as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.users) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.warnings as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.warnings) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.zookeeper as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.zookeeper) SETTINGS skip_unavailable_shards = 1;
CREATE OR REPLACE VIEW sysall.zookeeper_connection as select hostName() nodeHost, FQDN() nodeFQDN, * from clusterAllReplicas('{cluster}', system.zookeeper_connection) SETTINGS skip_unavailable_shards = 1;
Some examples
select * from sysall.cluster_state;
┌─shard_num─┬─replica_num─┬─host_name───────────┬─host_address─┬─port─┬─errors_count─┬──uptime─┬─node_state─┐
│ 1 │ 1 │ chhost1.localdomain │ 10.253.86.2 │ 9000 │ 0 │ 1071788 │ UP │
│ 2 │ 1 │ chhost2.localdomain │ 10.253.215.2 │ 9000 │ 0 │ 1071731 │ UP │
│ 3 │ 1 │ chhost3.localdomain │ 10.252.83.8 │ 9999 │ 0 │ 0 │ DOWN │
└───────────┴─────────────┴─────────────────────┴──────────────┴──────┴──────────────┴─────────┴────────────┘
SELECT
nodeFQDN,
path,
formatReadableSize(free_space) AS free,
formatReadableSize(total_space) AS total
FROM sysall.disks
┌─nodeFQDN────────────┬─path─────────────────┬─free───────┬─total──────┐
│ chhost1.localdomain │ /var/lib/clickhouse/ │ 511.04 GiB │ 937.54 GiB │
│ chhost2.localdomain │ /var/lib/clickhouse/ │ 495.77 GiB │ 937.54 GiB │
└─────────────────────┴──────────────────────┴────────────┴────────────┘
29 - Timeouts during OPTIMIZE FINAL
Timeout exceeded ... or executing longer than distributed_ddl_task_timeout during OPTIMIZE FINAL.Timeout exceeded ... or executing longer than distributed_ddl_task_timeout during OPTIMIZE FINAL
Timeout may occur
due to the fact that the client reach timeout interval.
- in case of TCP / native clients - you can change send_timeout / receive_timeout + tcp_keep_alive_timeout + driver timeout settings
- in case of HTTP clients - you can change http_send_timeout / http_receive_timeout + tcp_keep_alive_timeout + driver timeout settings
(in the case of ON CLUSTER queries) due to the fact that the timeout for query execution by shards ends
- see setting
distributed_ddl_task_timeout
- see setting
In the first case you additionally may get the misleading messages: Cancelling query. ... Query was cancelled.
In both cases, this does NOT stop the execution of the OPTIMIZE command. It continues to work even after
the client is disconnected. You can see the progress of that in system.processes / show processlist / system.merges / system.query_log.
The same applies to queries like:
INSERT ... SELECTCREATE TABLE ... AS SELECTCREATE MATERIALIZED VIEW ... POPULATE ...
It is possible to run a query with some special query_id and then poll the status from the processlist (in the case of a cluster, it can be a bit more complicated).
See also
30 - Use an executable dictionary as cron task
Rationale
Imagine that we need to restart clickhouse-server every saturday at 10:00 AM. We can use an executable dictionary to do this. Here is the approach and code necessary to do this. It can be used for other operations like INSERT into tables or execute some other imaginative tasks that need an scheduled execution.
Let’s create a simple table to register all the restarts scheduled by this dictionary:
CREATE TABLE restart_table
(
restart_datetime DateTime
)
ENGINE = TinyLog
Configuration
This is the ClickHouse configuration file we will be using for executable dictionaries. The dictionary is a dummy one (ignore the format and other stuff, we need format in the dict definition because if not it will fail loading), we don’t need it to do anything, just execute a script that has all the logic. The scheduled time is defined in the LIFETIME property of the dictionary (every 5 minutes dictionary will be refreshed and subsequently the script executed). Also for this case we need to load it on startup time setting lazy loading of dicts to false.
<!-- cat restart_dict.xml -->
<clickhouse>
<dictionaries_config>/etc/clickhouse-server/config.d/*_dict.xml</dictionaries_config>
<dictionaries_lazy_load>false</dictionaries_lazy_load>
<dictionary>
<name>restart_dict</name>
<structure>
<id>
<name>restart_id</name>
<type>UInt64</type>
</id>
</structure>
<source>
<executable>
<command>restart_dict.sh</command>
<execute_direct>true</execute_direct>
<format>CSV</format>
</executable>
</source>
<layout>
<flat/>
</layout>
<lifetime>300</lifetime>
</dictionary>
</clickhouse>
Action
Now the restart logic (which can be different for other needs). In this case it will do nothing until the restart windows comes. During the restart window, we check if there has been a restart in the same window timeframe (if window is an hour the condition should be 1h). The script will issue a SYSTEM SHUTDOWN command to restart the server. The script will also insert a record in the restart_table to register the restart time.
#!/bin/bash
CLICKHOUSE_USER="admin"
CLICKHOUSE_PASSWORD="xxxxxxxxx"
# Check if today is Saturday and the time is 10:00 AM CET or later
# Get current day of week (1-7, where 7 is Sunday)
# reload time for dict is 300 secs / 10 mins
current_day=$(date +%u)
# Get current time in hours and minutes
current_time=$(date +%H%M)
# Check if today is Saturday (6) and the time is between 10:00 AM and 11:00 AM
if [[ $current_day -eq 6 && $current_time -ge 1000 && $current_time -lt 1100 ]]; then
# Get current date and time as timestamp
current_timestamp=$(date +%s)
last_restart_timestamp=$(clickhouse-client --user $CLICKHOUSE_USER --password $CLICKHOUSE_PASSWORD --query "SELECT max(toUnixTimestamp(restart_datetime)) FROM restart_table")
# Check if the last restart timestamp is within last hour, if not then restart
if [[ $(( current_timestamp - last_restart_timestamp )) -ge 3600 ]]; then
# Push data to log table and restart
echo $current_timestamp | clickhouse-client --user $CLICKHOUSE_USER --password $CLICKHOUSE_PASSWORD --query "INSERT INTO restart_table FORMAT TSVRaw"
clickhouse-client --user $CLICKHOUSE_USER --password $CLICKHOUSE_PASSWORD --query "SYSTEM SHUTDOWN"
fi
fi
Improvements
If the dictionary has a high frecuency refresh time, then clickhouse could end up executing that script multiple times using a lot of resources and creating processes that can look like ‘stuck’ ones. To overcome this we can use the executable pool setting: https://clickhouse.com/docs/sql-reference/dictionaries#executable-pool
Executable pool will spawn a pool of processes (similar as a pool of connections) with the specified command and keep them running until they exit, which is useful for heavy scripts/python and reduces the initialization impact of those on clickhouse.
31 - Useful settings to turn on/Defaults that should be reconsidered
Useful settings to turn on/Defaults that should be reconsidered
Some setting that are not enabled by default.
Enables or disables complete dropping of data parts where all rows are expired in MergeTree tables.
When ttl_only_drop_parts is disabled (by default), the ClickHouse® server only deletes expired rows according to their TTL.
When ttl_only_drop_parts is enabled, the ClickHouse server drops a whole part when all rows in it are expired.
Dropping whole parts instead of partial cleaning TTL-d rows allows having shorter merge_with_ttl_timeout times and lower impact on system performance.
Might be you not expect that join will be filled with default values for missing columns (instead of classic NULLs) during JOIN.
Sets the type of JOIN behaviour. When merging tables, empty cells may appear. ClickHouse fills them differently based on this setting.
Possible values:
0 — The empty cells are filled with the default value of the corresponding field type. 1 — JOIN behaves the same way as in standard SQL. The type of the corresponding field is converted to Nullable, and empty cells are filled with NULL.
Default behaviour is not compatible with ANSI SQL (ClickHouse avoids Nullable types by performance reasons)
select sum(x), avg(x) from (select 1 x where 0);
┌─sum(x)─┬─avg(x)─┐
│ 0 │ nan │
└────────┴────────┘
set aggregate_functions_null_for_empty=1;
select sum(x), avg(x) from (select 1 x where 0);
┌─sumOrNull(x)─┬─avgOrNull(x)─┐
│ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │
└──────────────┴──────────────┘
32 - Who ate my CPU
Merges
SELECT
table,
round((elapsed * (1 / progress)) - elapsed, 2) AS estimate,
elapsed,
progress,
is_mutation,
formatReadableSize(total_size_bytes_compressed) AS size,
formatReadableSize(memory_usage) AS mem
FROM system.merges
ORDER BY elapsed DESC
Mutations
SELECT
database,
table,
substr(command, 1, 30) AS command,
sum(parts_to_do) AS parts_to_do,
anyIf(latest_fail_reason, latest_fail_reason != '')
FROM system.mutations
WHERE NOT is_done
GROUP BY
database,
table,
command
Current Processes
select elapsed, query from system.processes where is_initial_query and elapsed > 2
Processes retrospectively
SELECT
normalizedQueryHash(query) hash,
current_database,
sum(ProfileEvents['UserTimeMicroseconds'] as userCPUq)/1000 AS userCPUms,
count(),
sum(query_duration_ms) query_duration_ms,
userCPUms/query_duration_ms cpu_per_sec,
argMax(query, userCPUq) heaviest_query
FROM system.query_log
WHERE (type = 2) AND (event_date >= today())
GROUP BY
current_database,
hash
ORDER BY userCPUms DESC
LIMIT 10
FORMAT Vertical;
33 - Zookeeper session has expired
Q. I get “Zookeeper session has expired” once. What should i do? Should I worry?
Getting exceptions or lack of acknowledgement in distributed system from time to time is a normal situation. Your client should do the retry. If that happened once and your client do retries correctly - nothing to worry about.
It it happens often, or with every retry - it may be a sign of some misconfiguration / issue in cluster (see below).
Q. we see a lot of these: Zookeeper session has expired. Switching to a new session
A. There is a single Zookeeper session per server. But there are many threads that can use Zookeeper simultaneously. So the same event (we lose the single Zookeeper session we had), will be reported by all the threads/queries which were using that Zookeeper session.
Usually after loosing the Zookeeper session that exception is printed by all the thread which watch Zookeeper replication queues, and all the threads which had some in-flight Zookeeper operations (for example inserts, ON CLUSTER commands etc).
If you see a lot of those simultaneously - that just means you have a lot of threads talking to Zookeeper simultaneously (or may be you have many replicated tables?).
BTW: every Replicated table comes with its own cost, so you can’t scale the number of replicated tables indefinitely .
Typically after several hundreds (sometimes thousands) of replicated tables, the ClickHouse® server becomes unusable: it can’t do any other work, but only keeping replication housekeeping tasks. ‘ClickHouse-way’ is to have a few (maybe dozens) of very huge tables instead of having thousands of tiny tables. (Side note: the number of not-replicated tables can be scaled much better).
So again if during short period of time you see lot of those exceptions and that don’t happen anymore for a while - nothing to worry about. Just ensure your client is doing retries properly.
Q. We are wondering what is causing that session to “timeout” as the default looks like 30 seconds, and there’s certainly stuff happening much more frequently than every 30 seconds.
Typically that has nothing with an expiration/timeout - even if you do nothing there are heartbeat events in the Zookeeper protocol.
So internally inside ClickHouse:
- we have a ‘zookeeper client’ which in practice is a single Zookeeper connection (TCP socket), with 2 threads - one serving reads, the seconds serving writes, and some API around.
- while everything is ok Zookeeper client keeps a single logical ‘zookeeper session’ (also by sending heartbeats etc).
- we may have hundreds of ‘users’ of that Zookeeper client - those are threads that do some housekeeping, serve queries etc.
- Zookeeper client normally have dozen ‘in-flight’ requests (asked by different threads). And if something bad happens with that (disconnect, some issue with Zookeeper server, some other failure), Zookeeper client needs to re-establish the connection and switch to the new session so all those ‘in-flight’ requests will be terminated with a ‘session expired’ exception.
Q. That problem happens very often (all the time, every X minutes / hours / days).
Sometimes the real issue can be visible somewhere close to the first ‘session expired’ exception in the log. (i.e. Zookeeper client thread can know & print to logs the real reason, while all ‘user’ threads just get ‘session expired’).
Also Zookeeper logs may ofter have a clue to that was the real problem.
Known issues which can lead to session termination by Zookeeper:
- connectivity / network issues.
jute.maxbufferoverrun. If you need to pass too much data in a single Zookeeper transaction. (often happens if you need to do ALTER table UPDATE or other mutation on the table with big number of parts). The fix is adjusting JVM setting: -Djute.maxbuffer=8388608. See https://kb.altinity.com/altinity-kb-setup-and-maintenance/altinity-kb-zookeeper/jvm-sizes-and-garbage-collector-settings/- XID overflow. XID is a transaction counter in Zookeeper, if you do too many transactions the counter reaches maxint32, and to restart the counter Zookeeper closes all the connections. Usually, that happens rarely, and is not avoidable in Zookeeper (well in clickhouse-keeper that problem solved). There are some corner cases / some schemas which may end up with that XID overflow happening quite often. (a worst case we saw was once per 3 weeks).
Q. “Zookeeper session has expired” happens every time I try to start the mutation / do other ALTER on Replicated table.
During ALTERing replicated table ClickHouse need to create a record in Zookeeper listing all the parts which should be mutated (that usually means = list names of all parts of the table). If the size of list of parts exceeds maximum buffer size - Zookeeper drops the connection.
Parts name length can be different for different tables. In average with default jute.maxbuffer (1Mb) mutations start to fail for tables which have more than 5000 parts.
Solutions:
- rethink partitioning, high number of parts in table is usually not recommended
- increase
jute.maxbufferon Zookeeper side to values about 8M - use IN PARTITION clause for mutations (where applicable) - since 20.12
- switch to clickhouse-keeper
Q. “Zookeeper session has expired and also Operation timeout” happens when reading blocks from Zookeeper:
2024.02.22 07:20:39.222171 [ 1047 ] {} <Error> ZooKeeperClient: Code: 999. Coordination::Exception: Operation timeout (no response) for request List for path:
/clickhouse/tables/github_events/block_numbers/20240205105000 (Operation timeout). (KEEPER_EXCEPTION),
2024.02.22 07:20:39.223293 [ 246 ] {} <Error> default.github_events : void DB::StorageReplicatedMergeTree::mergeSelectingTask():
Code: 999. Coordination::Exception: /clickhouse/tables/github_events/block_numbers/20240205105000 (Connection loss).
Sometimes these Session expired and operation timeout are common, because of merges that read all the blocks in Zookeeper for a table and if there are many blocks (and partitions) read time can be longer than the 10 secs default operation timeout
.
When dropping a partition, ClickHouse never drops old block numbers from Zookeeper, so the list grows indefinitely. It is done as a precaution against race between DROP PARTITION and INSERT. It is safe to clean those old blocks manually
This is being addressed in #59507 Add <code>FORGET PARTITION</code> query to remove old partition nodes from
Solutions: Manually remove old/forgotten blocks https://kb.altinity.com/altinity-kb-useful-queries/remove_unneeded_block_numbers/
Related issues:
34 - Server configuration files
Сonfig management (recommended structure)
ClickHouse® server config consists of two parts server settings (config.xml) and users settings (users.xml).
By default they are stored in the folder /etc/clickhouse-server/ in two files config.xml & users.xml.
We suggest never change vendor config files and place your changes into separate .xml files in sub-folders. This way is easier to maintain and ease ClickHouse upgrades.
/etc/clickhouse-server/users.d – sub-folder for user settings
(derived from users.xml filename).
/etc/clickhouse-server/config.d – sub-folder for server settings (derived from config.xml filename).
/etc/clickhouse-server/conf.d – sub-folder for any (both) settings.
If the root config (xml or yaml) has a different name, such as keeper_config.xml or config_instance_66.xml, then the keeper_config.d and config_instance_66.d folders will be used. But conf.d is always used and processed last.
File names of your xml files can be arbitrary but they are applied in alphabetical order.
Examples:
$ cat /etc/clickhouse-server/config.d/listen_host.xml
<?xml version="1.0" ?>
<clickhouse>
<listen_host>::</listen_host>
</clickhouse>
$ cat /etc/clickhouse-server/config.d/macros.xml
<?xml version="1.0" ?>
<clickhouse>
<macros>
<cluster>test</cluster>
<replica>host22</replica>
<shard>0</shard>
<server_id>41295</server_id>
<server_name>host22.server.com</server_name>
</macros>
</clickhouse>
cat /etc/clickhouse-server/config.d/zoo.xml
<?xml version="1.0" ?>
<clickhouse>
<zookeeper>
<node>
<host>localhost</host>
<port>2181</port>
</node>
</zookeeper>
<distributed_ddl>
<path>/clickhouse/test/task_queue/ddl</path>
</distributed_ddl>
</clickhouse>
cat /etc/clickhouse-server/users.d/enable_access_management_for_user_default.xml
<?xml version="1.0" ?>
<clickhouse>
<users>
<default>
<access_management>1</access_management>
</default>
</users>
</clickhouse>
cat /etc/clickhouse-server/users.d/memory_usage.xml
<?xml version="1.0" ?>
<clickhouse>
<profiles>
<default>
<max_bytes_before_external_group_by>25290221568</max_bytes_before_external_group_by>
<max_memory_usage>50580443136</max_memory_usage>
</default>
</profiles>
</clickhouse>
BTW, you can define any macro in your configuration and use them in Zookeeper paths
ReplicatedMergeTree('/clickhouse/{cluster}/tables/my_table','{replica}')
or in your code using function getMacro:
CREATE OR REPLACE VIEW srv_server_info
SELECT (SELECT getMacro('shard')) AS shard_num,
(SELECT getMacro('server_name')) AS server_name,
(SELECT getMacro('server_id')) AS server_key
Settings can be appended to an XML tree (default behaviour) or replaced or removed.
Example how to delete tcp_port & http_port defined on higher level in the main config.xml (it disables open tcp & http ports if you configured secure ssl):
cat /etc/clickhouse-server/config.d/disable_open_network.xml
<?xml version="1.0"?>
<clickhouse>
<http_port remove="1"/>
<tcp_port remove="1"/>
</clickhouse>
Example how to replace remote_servers section defined on higher level in the main config.xml (it allows to remove default test clusters.
<?xml version="1.0" ?>
<clickhouse>
<remote_servers replace="1">
<mycluster>
....
</mycluster>
</remote_servers>
</clickhouse>
Settings & restart
General ‘rule of thumb’:
- server settings (
config.xmlandconfig.d) changes require restart; - user settings (
users.xmlandusers.d) changes don’t require restart.
But there are exceptions from those rules (see below).
Server config (config.xml) sections which don’t require restart
<max_server_memory_usage><max_server_memory_usage_to_ram_ratio><max_table_size_to_drop>(since 19.12)<max_partition_size_to_drop>(since 19.12)<max_concurrent_queries>(since 21.11, also for versions older than v24 system tables are not updated with the new config values)<macros><remote_servers><dictionaries_config><user_defined_executable_functions_config><models_config><keeper_server><zookeeper>(but reconnect don’t happen automatically)<storage_configuration>– only if you add a new entity (disk/volume/policy), to modify these enitities restart is mandatory.<user_directories><access_control_path><encryption_codecs><logger>(since 21.11)
Those sections (live in separate files):
<dictionaries><functions><models>
User settings which require restart.
Most of user setting changes don’t require restart, but they get applied at the connect time, so existing connection may still use old user-level settings. That means that that new setting will be applied to new sessions / after reconnect.
The list of user setting which require server restart:
<background_buffer_flush_schedule_pool_size><background_pool_size><background_merges_mutations_concurrency_ratio><background_move_pool_size><background_fetches_pool_size><background_common_pool_size><background_schedule_pool_size><background_message_broker_schedule_pool_size><background_distributed_schedule_pool_size><max_replicated_fetches_network_bandwidth_for_server><max_replicated_sends_network_bandwidth_for_server>
See also select * from system.settings where description ilike '%start%'
Also there are several ’long-running’ user sessions which are almost never restarted and can keep the setting from the server start (it’s DDLWorker, Kafka , and some other service things).
Dictionaries
We suggest to store each dictionary description in a separate (own) file in a /etc/clickhouse-server/dict sub-folder.
$ cat /etc/clickhouse-server/dict/country.xml
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>country</name>
<source>
<http>
...
</dictionary>
</dictionaries>
and add to the configuration
$ cat /etc/clickhouse-server/config.d/dictionaries.xml
<?xml version="1.0"?>
<clickhouse>
<dictionaries_config>dict/*.xml</dictionaries_config>
<dictionaries_lazy_load>true</dictionaries_lazy_load>
</clickhouse>
dict/*.xml – relative path, servers seeks files in the folder /etc/clickhouse-server/dict. More info in Multiple ClickHouse instances .
incl attribute & metrica.xml
incl attribute allows to include some XML section from a special include file multiple times.
By default include file is /etc/metrika.xml. You can use many include files for each XML section.
For example to avoid repetition of user/password for each dictionary you can create an XML file:
$ cat /etc/clickhouse-server/dict_sources.xml
<?xml version="1.0"?>
<clickhouse>
<mysql_config>
<port>3306</port>
<user>user</user>
<password>123</password>
<replica>
<host>mysql_host</host>
<priority>1</priority>
</replica>
<db>my_database</db>
</mysql_config>
</clickhouse>
Include this file:
$ cat /etc/clickhouse-server/config.d/dictionaries.xml
<?xml version="1.0"?>
<clickhouse>
...
<include_from>/etc/clickhouse-server/dict_sources.xml</include_from>
</clickhouse>
And use in dictionary descriptions (incl=“mysql_config”):
$ cat /etc/clickhouse-server/dict/country.xml
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>country</name>
<source>
<mysql incl="mysql_config">
<table>my_table</table>
<invalidate_query>select max(id) from my_table</invalidate_query>
</mysql>
</source>
...
</dictionary>
</dictionaries>
Multiple ClickHouse instances at one host
By default ClickHouse server configs are in /etc/clickhouse-server/ because clickhouse-server runs with a parameter –config-file /etc/clickhouse-server/config.xml
config-file is defined in startup scripts:
- /etc/init.d/clickhouse-server – init-V
- /etc/systemd/system/clickhouse-server.service – systemd
ClickHouse uses the path from config-file parameter as base folder and seeks for other configs by relative path. All sub-folders users.d / config.d are relative.
You can start multiple clickhouse-server each with own –config-file.
For example:
/usr/bin/clickhouse-server --config-file /etc/clickhouse-server-node1/config.xml
/etc/clickhouse-server-node1/ config.xml ... users.xml
/etc/clickhouse-server-node1/config.d/disable_open_network.xml
/etc/clickhouse-server-node1/users.d/....
/usr/bin/clickhouse-server --config-file /etc/clickhouse-server-node2/config.xml
/etc/clickhouse-server-node2/ config.xml ... users.xml
/etc/clickhouse-server-node2/config.d/disable_open_network.xml
/etc/clickhouse-server-node2/users.d/....
If you need to run multiple servers for CI purposes you can combine all settings in a single fat XML file and start ClickHouse without config folders/sub-folders.
/usr/bin/clickhouse-server --config-file /tmp/ch1.xml
/usr/bin/clickhouse-server --config-file /tmp/ch2.xml
/usr/bin/clickhouse-server --config-file /tmp/ch3.xml
Each ClickHouse instance must work with own data-folder and tmp-folder.
By default ClickHouse uses /var/lib/clickhouse/. It can be overridden in path settings
<path>/data/clickhouse-ch1/</path>
<tmp_path>/data/clickhouse-ch1/tmp/</tmp_path>
<user_files_path>/data/clickhouse-ch1/user_files/</user_files_path>
<local_directory>
<path>/data/clickhouse-ch1/access/</path>
</local_directory>
<format_schema_path>/data/clickhouse-ch1/format_schemas/</format_schema_path>
preprocessed_configs
ClickHouse server watches config files and folders. When you change, add or remove XML files ClickHouse immediately assembles XML files into a combined file. These combined files are stored in /var/lib/clickhouse/preprocessed_configs/ folders.
You can verify that your changes are valid by checking /var/lib/clickhouse/preprocessed_configs/config.xml, /var/lib/clickhouse/preprocessed_configs/users.xml.
If something wrong with with your settings e.g. unclosed XML element or typo you can see alerts about this mistakes in /var/log/clickhouse-server/clickhouse-server.log
If you see your changes in preprocessed_configs it does not mean that changes are applied on running server, check Settings and restart.
35 - Aggressive merges
Q: Is there any way I can dedicate more resources to the merging process when running ClickHouse® on pretty beefy machines (like 36 cores, 1TB of RAM, and large NVMe disks)?
A: Such things are done by increasing the level of parallelism:
1. background_pool_size - how many threads will actually be doing merges and mutations. If you can push most server resources toward merges, for example, in a controlled backlog-clearing window with little foreground traffic, you can raise it aggressively. If you use replicated tables, review max_replicated_merges_in_queue together with it.
2. background_merges_mutations_concurrency_ratio - how many merges and mutations may be assigned relative to background_pool_size. Sometimes the default (2) may work against you by favoring more smaller tasks, which is useful for continuous real-time inserts but less useful when you want a backlog-clearing merge window. In that case, trying 1 is reasonable.
number_of_free_entries_in_pool_to_lower_max_size_of_merge(merge_tree setting) should be changed together with background_pool_size (50-90% of that). “When there is less than a specified number of free entries in the pool (or replicated queue), start to lower the maximum size of the merge to process (or to put in the queue). This is to allow small merges to process - not filling the pool with long-running merges.” To make it really aggressive, try 90-95% of background_pool_size, for ex. 34 (so you will have 34 huge merges and 2 small ones).
Runtime vs restart semantics
background_pool_size and background_merges_mutations_concurrency_ratio can be increased at runtime, but lowering them requires a restart.
Merge scheduling tradeoffs
background_merges_mutations_scheduling_policy is an adjacent knob worth considering:
shortest_task_firsthelps clear small parts quickly, but can starve large merges if inserts keep producing small parts.round_robinis safer when starvation of large merges is a concern.
Other settings to consider
- control how large target parts may become via
max_bytes_to_merge_at_max_space_in_poolif the backlog is dominated by many medium parts instead of tiny fragments. - review
min_merge_bytes_to_use_direct_ioif you suspect page-cache churn during very large merges. Direct I/O is workload-dependent, so benchmark it instead of assuming it is always better or worse. - on replicated tables with slow merges and a fast network, consider
execute_merges_on_single_replica_time_thresholdso one replica performs the merge and others can fetch the merged part instead of repeating the same work. - analyze whether Vertical or Horizontal merge is better for your schema. Vertical merges typically use less RAM and keep fewer files open, while Horizontal merges may be simpler and faster for some layouts.
- if you have a lot of tables, review scheduler capacity as well:
background_schedule_pool_sizeandbackground_common_pool_size. - review the schema, especially codecs/compression, because they reduce size but can materially change merge speed.
- try to form bigger parts during inserts with
min_insert_block_size_bytes,min_insert_block_size_rows, andmax_insert_block_size. - check whether Wide or Compact parts are being created (
system.parts). Part format is controlled bymin_bytes_for_wide_partandmin_rows_for_wide_part, so inspect those settings for your version instead of assuming a fixed default cutoff. - consider using recent ClickHouse releases, because mark compression improvements can reduce I/O overhead in merge-heavy workloads.
How to validate changes
All adjustments should be validated with a reproducible benchmark or controlled backlog-clearing test. Compare the before/after trend for merge backlog or part counts, then watch whether the system clears the backlog faster without harming foreground workload. Also monitor how system resources are used or saturated during the test, especially CPU, disk I/O, and for replicated tables network plus ClickHouse Keeper / ZooKeeper load.
Monitor or plot pool usage:
select * from system.metrics where metric like '%PoolTask'
If the relevant pool task counters stay near saturation while backlog does not improve, you are likely limited by another bottleneck such as disk bandwidth, network fetches, or insert shape rather than by merge thread count alone.
Do not use this template when…
- the same nodes must sustain low-latency reads and writes continuously, with little room for merge-heavy maintenance windows;
- the cluster is already constrained by disk bandwidth rather than merge thread count;
- the workload is dominated by mutations, where
number_of_free_entries_in_pool_to_execute_mutationmay need separate treatment.
Server config example
cat /etc/clickhouse-server/config.d/aggresive_merges.xml
<clickhouse>
<background_pool_size>36</background_pool_size>
<background_schedule_pool_size>128</background_schedule_pool_size>
<background_common_pool_size>8</background_common_pool_size>
<background_merges_mutations_concurrency_ratio>1</background_merges_mutations_concurrency_ratio>
<merge_tree>
<number_of_free_entries_in_pool_to_lower_max_size_of_merge>32</number_of_free_entries_in_pool_to_lower_max_size_of_merge>
<max_replicated_merges_in_queue>36</max_replicated_merges_in_queue>
<max_bytes_to_merge_at_max_space_in_pool>161061273600</max_bytes_to_merge_at_max_space_in_pool>
<min_merge_bytes_to_use_direct_io>10737418240</min_merge_bytes_to_use_direct_io> <!-- 0 to disable -->
</merge_tree>
</clickhouse>
Legacy profile-style example
Only use the default profile layout if you are intentionally keeping an older configuration style or a compatibility path. See the version notes at the end of this article before copying it.
cat /etc/clickhouse-server/users.d/aggresive_merges.xml
<clickhouse>
<profiles>
<default>
<background_pool_size>36</background_pool_size>
<background_merges_mutations_concurrency_ratio>1</background_merges_mutations_concurrency_ratio>
</default>
</profiles>
</clickhouse>
Version notes
- Through
23.2.x, ClickHouse read these pool settings from the main config and also fell back toprofiles.default.*inContext.cpp. That older path covered not onlybackground_pool_sizeandbackground_merges_mutations_concurrency_ratio, but also settings such asbackground_schedule_pool_sizeandbackground_common_pool_size. - Starting with
23.3.1.2823-lts, ClickHouse changed this area in PR#48055(“Refactor reading the pool setting & from server config”). From that release forward, these settings were documented as server settings and the source markedbackground_pool_sizeandbackground_merges_mutations_concurrency_ratioas moved to server config. - For
23.3.1.2823-ltsand later, prefer server config (config.xml/config.d) forbackground_*settings. This is the layout shown in the main example above. background_pool_sizeandbackground_merges_mutations_concurrency_ratiostill keep a backward-compatibility path from thedefaultprofile at server startup in current upstream source and docs. That is why the legacy profile-style example above is limited to those two settings.- This article intentionally does not show
background_schedule_pool_sizeorbackground_common_pool_sizeinusers.d. Older versions accepted that pattern, but current upstream docs do not document those settings as profile-based compatibility knobs. For current versions, keep them in server config.
36 - Altinity Backup for ClickHouse®
Installation and configuration
Download the latest clickhouse-backup.tar.gz from assets from https://github.com/Altinity/clickhouse-backup/releases
This tar.gz contains a single binary of clickhouse-backup and an example of config file.
Backblaze has s3 compatible API but requires empty acl parameter acl: "".
https://www.backblaze.com/ has 15 days and free 10Gb S3 trial.
$ mkdir clickhouse-backup
$ cd clickhouse-backup
$ wget https://github.com/Altinity/clickhouse-backup/releases/download/v2.5.20/clickhouse-backup.tar.gz
$ tar zxf clickhouse-backup.tar.gz
$ rm clickhouse-backup.tar.gz
$ cat config.yml
general:
remote_storage: s3
disable_progress_bar: false
backups_to_keep_local: 0
backups_to_keep_remote: 0
log_level: info
allow_empty_backups: false
clickhouse:
username: default
password: ""
host: localhost
port: 9000
disk_mapping: {}
skip_tables:
- system.*
timeout: 5m
freeze_by_part: false
secure: false
skip_verify: false
sync_replicated_tables: true
log_sql_queries: false
s3:
access_key: 0****1
secret_key: K****1
bucket: "mybucket"
endpoint: https://s3.us-west-000.backblazeb2.com
region: us-west-000
acl: ""
force_path_style: false
path: clickhouse-backup
disable_ssl: false
part_size: 536870912
compression_level: 1
compression_format: tar
sse: ""
disable_cert_verification: false
storage_class: STANDARD
I have a database test with table test
select count() from test.test;
┌─count()─┐
│ 400000 │
└─────────┘
clickhouse-backup list should work without errors (it scans local and remote (s3) folders):
$ sudo ./clickhouse-backup list -c config.yml
$
Backup
- create a local backup of database test
- upload this backup to remote
- remove the local backup
- drop the source database
$ sudo ./clickhouse-backup create --tables='test.*' bkp01 -c config.yml
2021/05/31 23:11:13 info done backup=bkp01 operation=create table=test.test
2021/05/31 23:11:13 info done backup=bkp01 operation=create
$ sudo ./clickhouse-backup upload bkp01 -c config.yml
1.44 MiB / 1.44 MiB [=====================] 100.00% 2s
2021/05/31 23:12:13 info done backup=bkp01 operation=upload table=test.test
2021/05/31 23:12:17 info done backup=bkp01 operation=upload
$ sudo ./clickhouse-backup list -c config.yml
bkp01 1.44MiB 31/05/2021 23:11:13 local
bkp01 1.44MiB 31/05/2021 23:11:13 remote tar
$ sudo ./clickhouse-backup delete local bkp01 -c config.yml
2021/05/31 23:13:29 info delete 'bkp01'
DROP DATABASE test;
Restore
- download the remote backup
- restore database
$ sudo ./clickhouse-backup list -c config.yml
bkp01 1.44MiB 31/05/2021 23:11:13 remote tar
$ sudo ./clickhouse-backup download bkp01 -c config.yml
2021/05/31 23:14:41 info done backup=bkp01 operation=download table=test.test
1.47 MiB / 1.47 MiB [=====================] 100.00% 0s
2021/05/31 23:14:43 info done backup=bkp01 operation=download table=test.test
2021/05/31 23:14:43 info done backup=bkp01 operation=download
$ sudo ./clickhouse-backup restore bkp01 -c config.yml
2021/05/31 23:16:04 info done backup=bkp01 operation=restore table=test.test
2021/05/31 23:16:04 info done backup=bkp01 operation=restore
SELECT count() FROM test.test;
┌─count()─┐
│ 400000 │
└─────────┘
Delete backups
$ sudo ./clickhouse-backup delete local bkp01 -c config.yml
2021/05/31 23:17:05 info delete 'bkp01'
$ sudo ./clickhouse-backup delete remote bkp01 -c config.yml
37 - Altinity packaging compatibility >21.x and earlier
Working with Altinity & Yandex packaging together
Since ClickHouse® version 21.1 Altinity switches to the same packaging as used by Yandex. That is needed for syncing things and introduces several improvements (like adding systemd service file).
Unfortunately, that change leads to compatibility issues - automatic dependencies resolution gets confused by the conflicting package names: both when you update ClickHouse to the new version (the one which uses older packaging) and when you want to install older altinity packages (20.8 and older).
Installing old ClickHouse version (with old packaging schema)
When you try to install versions 20.8 or older from Altinity repo -
version=20.8.12.2-1.el7
yum install clickhouse-client-${version} clickhouse-server-${version}
yum outputs something like
yum install clickhouse-client-${version} clickhouse-server-${version}
Loaded plugins: fastestmirror, ovl
Loading mirror speeds from cached hostfile
* base: centos.hitme.net.pl
* extras: centos1.hti.pl
* updates: centos1.hti.pl
Altinity_clickhouse-altinity-stable/x86_64/signature | 833 B 00:00:00
Altinity_clickhouse-altinity-stable/x86_64/signature | 1.0 kB 00:00:01 !!!
Altinity_clickhouse-altinity-stable-source/signature | 833 B 00:00:00
Altinity_clickhouse-altinity-stable-source/signature | 951 B 00:00:00 !!!
Resolving Dependencies
--> Running transaction check
---> Package clickhouse-client.x86_64 0:20.8.12.2-1.el7 will be installed
---> Package clickhouse-server.x86_64 0:20.8.12.2-1.el7 will be installed
--> Processing Dependency: clickhouse-server-common = 20.8.12.2-1.el7 for package: clickhouse-server-20.8.12.2-1.el7.x86_64
Package clickhouse-server-common is obsoleted by clickhouse-server, but obsoleting package does not provide for requirements
--> Processing Dependency: clickhouse-common-static = 20.8.12.2-1.el7 for package: clickhouse-server-20.8.12.2-1.el7.x86_64
--> Running transaction check
---> Package clickhouse-common-static.x86_64 0:20.8.12.2-1.el7 will be installed
---> Package clickhouse-server.x86_64 0:20.8.12.2-1.el7 will be installed
--> Processing Dependency: clickhouse-server-common = 20.8.12.2-1.el7 for package: clickhouse-server-20.8.12.2-1.el7.x86_64
Package clickhouse-server-common is obsoleted by clickhouse-server, but obsoleting package does not provide for requirements
--> Finished Dependency Resolution
Error: Package: clickhouse-server-20.8.12.2-1.el7.x86_64 (Altinity_clickhouse-altinity-stable)
Requires: clickhouse-server-common = 20.8.12.2-1.el7
Available: clickhouse-server-common-1.1.54370-2.x86_64 (clickhouse-stable)
clickhouse-server-common = 1.1.54370-2
Available: clickhouse-server-common-1.1.54378-2.x86_64 (clickhouse-stable)
clickhouse-server-common = 1.1.54378-2
...
Available: clickhouse-server-common-20.8.11.17-1.el7.x86_64 (Altinity_clickhouse-altinity-stable)
clickhouse-server-common = 20.8.11.17-1.el7
Available: clickhouse-server-common-20.8.12.2-1.el7.x86_64 (Altinity_clickhouse-altinity-stable)
clickhouse-server-common = 20.8.12.2-1.el7
You could try using --skip-broken to work around the problem
You could try running: rpm -Va --nofiles --nodigest
As you can see yum has an issue with resolving clickhouse-server-common dependency, which marked as obsoleted by newer packages.
Solution with Old Packaging Scheme
add --setopt=obsoletes=0 flag to the yum call.
version=20.8.12.2-1.el7
yum install --setopt=obsoletes=0 clickhouse-client-${version} clickhouse-server-${version}
---
title: "installation succeeded"
linkTitle: "installation succeeded"
description: >
installation succeeded
---
Alternatively, you can add obsoletes=0 into /etc/yum.conf.
To update to new ClickHouse version (from old packaging schema to new packaging schema)
version=21.1.7.1-2
yum install clickhouse-client-${version} clickhouse-server-${version}
Loaded plugins: fastestmirror, ovl
Loading mirror speeds from cached hostfile
* base: centos.hitme.net.pl
* extras: centos1.hti.pl
* updates: centos1.hti.pl
Altinity_clickhouse-altinity-stable/x86_64/signature | 833 B 00:00:00
Altinity_clickhouse-altinity-stable/x86_64/signature | 1.0 kB 00:00:01 !!!
Altinity_clickhouse-altinity-stable-source/signature | 833 B 00:00:00
Altinity_clickhouse-altinity-stable-source/signature | 951 B 00:00:00 !!!
Nothing to do
It is caused by wrong dependencies resolution.
Solution with New Package Scheme
To update to the latest available version - just add clickhouse-server-common:
yum install clickhouse-client clickhouse-server clickhouse-server-common
This way the latest available version will be installed (even if you will request some other version explicitly).
To install some specific version remove old packages first, then install new ones.
yum erase clickhouse-client clickhouse-server clickhouse-server-common clickhouse-common-static
version=21.1.7.1
yum install clickhouse-client-${version} clickhouse-server-${version}
Downgrade from new version to old one
version=20.8.12.2-1.el7
yum downgrade clickhouse-client-${version} clickhouse-server-${version}
will not work:
Loaded plugins: fastestmirror, ovl
Loading mirror speeds from cached hostfile
* base: ftp.agh.edu.pl
* extras: ftp.agh.edu.pl
* updates: centos.wielun.net
Resolving Dependencies
--> Running transaction check
---> Package clickhouse-client.x86_64 0:20.8.12.2-1.el7 will be a downgrade
---> Package clickhouse-client.noarch 0:21.1.7.1-2 will be erased
---> Package clickhouse-server.x86_64 0:20.8.12.2-1.el7 will be a downgrade
--> Processing Dependency: clickhouse-server-common = 20.8.12.2-1.el7 for package: clickhouse-server-20.8.12.2-1.el7.x86_64
Package clickhouse-server-common-20.8.12.2-1.el7.x86_64 is obsoleted by clickhouse-server-21.1.7.1-2.noarch which is already installed
--> Processing Dependency: clickhouse-common-static = 20.8.12.2-1.el7 for package: clickhouse-server-20.8.12.2-1.el7.x86_64
---> Package clickhouse-server.noarch 0:21.1.7.1-2 will be erased
--> Finished Dependency Resolution
Error: Package: clickhouse-server-20.8.12.2-1.el7.x86_64 (Altinity_clickhouse-altinity-stable)
Requires: clickhouse-common-static = 20.8.12.2-1.el7
Installed: clickhouse-common-static-21.1.7.1-2.x86_64 (@clickhouse-stable)
clickhouse-common-static = 21.1.7.1-2
Available: clickhouse-common-static-1.1.54378-2.x86_64 (clickhouse-stable)
clickhouse-common-static = 1.1.54378-2
Error: Package: clickhouse-server-20.8.12.2-1.el7.x86_64 (Altinity_clickhouse-altinity-stable)
...
Available: clickhouse-server-common-20.8.12.2-1.el7.x86_64 (Altinity_clickhouse-altinity-stable)
clickhouse-server-common = 20.8.12.2-1.el7
You could try using --skip-broken to work around the problem
You could try running: rpm -Va --nofiles --nodigest
Solution With Downgrading
Remove packages first, then install older versions:
yum erase clickhouse-client clickhouse-server clickhouse-server-common clickhouse-common-static
version=20.8.12.2-1.el7
yum install --setopt=obsoletes=0 clickhouse-client-${version} clickhouse-server-${version}
38 - AWS EC2 Storage
EBS
Most native choose for ClickHouse® as fast storage, because it usually guarantees best throughput, IOPS, latency for reasonable price.
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-optimized.html
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-volume-types.html
General Purpose SSD volumes
In usual conditions ClickHouse being limited by throughput of volumes and amount of provided IOPS doesn’t make any big difference for performance starting from a certain number. So the most native choice for ClickHouse is gp3 and gp2 volumes.
EC2 instances also have an EBS throughput limit, it depends on the size of the EC2 instance. That means if you would attach multiple volumes which would have high potential throughput, you would be limited by your EC2 instance, so usually there is no reason to have more than 1-3 GP3 volume or 4-5 GP2 volume per node.
It’s pretty straightforward to set up a ClickHouse for using multiple EBS volumes with jbod storage_policies.
| Volume type | gp3 | gp2 |
|---|---|---|
| Max throughput per volume | 1000 MiB/s | 250 MiB/s |
| Price | $0.08/GB-month 3,000 IOPS free and $0.005/provisioned IOPS-month over 3,000; 125 MB/s free and $0.04/provisioned MB/s-month over 125 | $0.10/GB-month |
GP3
It’s recommended option, as it allow you to have only one volume, for instances which have less than 10 Gbps EBS Bandwidth (nodes =<32 VCPU usually) and still have maximum performance. For bigger instances, it make sense to look into option of having several GP3 volumes.
It’s a new type of volume, which is 20% cheaper than gp2 per GB-month and has lower free throughput: only 125 MiB/s vs 250 MiB/s. But you can buy additional throughput and IOPS for volume. It also works better if most of your queries read only one or several parts, because in that case you are not being limited by performance of a single EBS disk, as parts can be located only on one disk at once.
Because, you need to have less GP3 volumes compared to GP2 option, it’s suggested approach for now.
For best performance, it’s suggested to buy:
- 7000 IOPS
- Throughput up to the limit of your EC2 instance (1000 MiB/s is safe option)
GP2
GP2 volumes have a hard limit of 250 MiB/s per volume (for volumes bigger than 334 GB), it usually makes sense to split one big volume in multiple smaller volumes larger than 334GB in order to have maximum possible throughput.
Throughput Optimized HDD volumes
ST1
Looks like a good candidate for cheap cold storage for old data with decent maximum throughput 500 MiB/s. But it achieved only for big volumes >5 TiB.
Throughput credits and burst performance
Provisioned IOPS SSD volumes
IO2 Block Express, IO2, IO1
In 99.99% cases doesn’t give any benefit for ClickHouse compared to GP3 option and perform worse because maximum throughput is limited to 500 MiB/s per volume if you buy less than 32 000 IOPS, which is really expensive (compared to other options) and unneeded for ClickHouse. And if you have spare money, it’s better to spend them on better EC2 instance.
S3
Best option for cold data, it can give considerably good throughput and really good price, but latencies and IOPS much worse than EBS option. Another interesting point is, for EC2 instance throughput limit for EBS and S3 calculated separately, so if you access your data both from EBS and S3, you can get double throughput.
It’s stated in AWS documentation, that S3 can fully utilize network capacity of EC2 instance. (up to 100 Gb/s) Latencies or (first-byte-out) estimated to be 100-200 milliseconds withing single region.
It also recommended to enable gateway endpoint for s3 , it can push throughput even further (up to 800 Gb/s)
EFS
Works over NFSv4.1 version. We have clients, which run their ClickHouse installations over NFS. It works considerably well as cold storage, so it’s recommended to have EBS disks for hot data. A fast network is required.
ClickHouse doesn’t have any native option to reuse the same data on durable network disk via several replicas. You either need to store the same data twice or build custom tooling around ClickHouse and use it without Replicated*MergeTree tables.
FSx
Lustre
We have several clients, who use Lustre (some of them use AWS FSx Lustre, another is self managed Lustre) without any big issue. Fast network is required. There were known problems with data damage on older versions caused by issues with O_DIRECT or async IO support on Lustre.
ClickHouse doesn’t have any native option to reuse the same data on durable network disk via several replicas. You either need to store the same data twice or build custom tooling around ClickHouse and use it without Replicated*MergeTree tables.
https://altinity.com/blog/2019/11/27/amplifying-clickhouse-capacity-with-multi-volume-storage-part-1
https://altinity.com/blog/2019/11/29/amplifying-clickhouse-capacity-with-multi-volume-storage-part-2
https://calculator.aws/#/createCalculator/EBS?nc2=h_ql_pr_calc
39 - ClickHouse® in Docker
Do you have documentation on Docker deployments?
Check
- https://hub.docker.com/r/clickhouse/clickhouse-server
- https://docs.altinity.com/clickhouseonkubernetes/
- sources of entry point - https://github.com/ClickHouse/ClickHouse/blob/master/docker/server/entrypoint.sh
Important things:
- use concrete version tag (avoid using latest)
- if possible use
--network=host(due to performance reasons) - you need to mount the folder
/var/lib/clickhouseto have persistency. - you MAY also mount the folder
/var/log/clickhouse-serverto have logs accessible outside of the container. - Also, you may mount in some files or folders in the configuration folder:
/etc/clickhouse-server/config.d/listen_ports.xml
--ulimit nofile=262144:262144- You can also set on some linux capabilities to enable some of extra features of ClickHouse® (not obligatory):
SYS_PTRACE NET_ADMIN IPC_LOCK SYS_NICE - you may also mount in the folder
/docker-entrypoint-initdb.d/- all SQL or bash scripts there will be executed during container startup. - if you use cgroup limits - it may misbehave https://github.com/ClickHouse/ClickHouse/issues/2261
(set up
<max_server_memory_usage>manually) - there are several ENV switches, see: https://github.com/ClickHouse/ClickHouse/blob/master/docker/server/entrypoint.sh
TLDR version: use it as a starting point:
docker run -d \
--name some-clickhouse-server \
--ulimit nofile=262144:262144 \
--volume=$(pwd)/data:/var/lib/clickhouse \
--volume=$(pwd)/logs:/var/log/clickhouse-server \
--volume=$(pwd)/configs/memory_adjustment.xml:/etc/clickhouse-server/config.d/memory_adjustment.xml \
--cap-add=SYS_NICE \
--cap-add=NET_ADMIN \
--cap-add=IPC_LOCK \
--cap-add=SYS_PTRACE \
--network=host \
clickhouse/clickhouse-server:latest
docker exec -it some-clickhouse-server clickhouse-client
docker exec -it some-clickhouse-server bash
40 - ClickHouse® Monitoring
What to read / watch on the subject:
- Altinity webinar “ClickHouse Monitoring 101: What to monitor and how”. Watch the video or download the slides .
- The ClickHouse docs
What should be monitored
The following metrics should be collected / monitored
For Host Machine:
- CPU
- Memory
- Network (bytes/packets)
- Storage (iops)
- Disk Space (free / used)
For ClickHouse:
- Connections (Number of queries running)
- DDL queue length
- RWLocks
- Read / Write / Return (bytes/rows)
- Merges (queue length, memory used)
- Mutations
- Query duration (optional)
- Replication queue length and lag
- Read only tables
- ZooKeeper latencies
- Zookeeper operations (count)
- S3 errors (if used)
For Zookeeper:
ClickHouse monitoring tools
Prometheus (embedded exporter) + Grafana
- Enable embedded exporter
- Grafana dashboards https://grafana.com/grafana/dashboards/14192 or https://grafana.com/grafana/dashboards/13500
Prometheus (embedded http handler with Altinity Kubernetes Operator for ClickHouse style metrics) + Grafana
- Enable http handler
- Useful, if you want to use the dashboard from the Altinity Kubernetes Operator for ClickHouse, but do not run ClickHouse in k8s.
Prometheus (embedded exporter in the Altinity Kubernetes Operator for ClickHouse) + Grafana
- exporter is included in the Altinity Kubernetes Operator for ClickHouse, and enabled automatically
- see instructions of Prometheus and Grafana installation (if you don’t have one)
- Grafana dashboard https://github.com/Altinity/clickhouse-operator/tree/master/grafana-dashboard
- Prometheus alerts https://github.com/Altinity/clickhouse-operator/blob/master/deploy/prometheus/prometheus-alert-rules-clickhouse.yaml
Prometheus (ClickHouse external exporter) + Grafana
(unmaintained)
Dashboards querying ClickHouse directly via vertamedia / Altinity plugin
- Overview: https://grafana.com/grafana/dashboards/13606
- Queries dashboard (analyzing system.query_log) https://grafana.com/grafana/dashboards/2515
Dashboard querying ClickHouse directly via Grafana plugin
- https://grafana.com/blog/2022/05/05/introducing-the-official-clickhouse-plugin-for-grafana/
- https://gist.github.com/filimonov/271e5b27c085356c67db3c1bf2204506
Zabbix
- https://www.zabbix.com/integrations/clickhouse
- https://github.com/Altinity/clickhouse-zabbix-template
Graphite
- Use the embedded exporter. See docs and config.xml
InfluxDB
- You can use embedded exporter, plus Telegraf. For more information, see Graphite protocol support in InfluxDB .
Nagios/Icinga
Commercial solution
- Datadog https://docs.datadoghq.com/integrations/clickhouse/?tab=host
- Sematext https://sematext.com/docs/integration/clickhouse/
- Instana https://www.instana.com/supported-technologies/clickhouse-monitoring/
- site24x7 https://www.site24x7.com/plugins/clickhouse-monitoring.html
- Acceldata Pulse https://www.acceldata.io/blog/acceldata-pulse-for-clickhouse-monitoring
“Build your own” ClickHouse monitoring
ClickHouse allows to access lots of internals using system tables. The main tables to access monitoring data are:
- system.metrics
- system.asynchronous_metrics
- system.events
Minimum necessary set of checks
| Check Name | Shell or SQL command | Severity |
| ClickHouse status | $ curl 'http://localhost:8123/'
| Critical |
| Too many simultaneous queries. Maximum: 100 (by default) | select value from system.metrics
| Critical |
| Replication status | $ curl 'http://localhost:8123/replicas_status'
| High |
Read only replicas (reflected by replicas_status as well) | select value from system.metrics
| High |
| Some replication tasks are stuck | select count()
| High |
| ZooKeeper is available | select count() from system.zookeeper
| Critical for writes |
| ZooKeeper exceptions | select value from system.events
| Medium |
| Other CH nodes are available | $ for node in `echo "select distinct host_address from system.clusters where host_name !='localhost'" | curl 'http://localhost:8123/' --silent --data-binary @-`; do curl "http://$node:8123/" --silent ; done | sort -u
| High |
| All CH clusters are available (i.e. every configured cluster has enough replicas to serve queries) | for cluster in `echo "select distinct cluster from system.clusters where host_name !='localhost'" | curl 'http://localhost:8123/' --silent --data-binary @-` ; do clickhouse-client --query="select '$cluster', 'OK' from cluster('$cluster', system, one)" ; done | Critical |
| There are files in 'detached' folders | $ find /var/lib/clickhouse/data/*/*/detached/* -type d | wc -l; \
19.8+
| Medium |
| Too many parts: \ Number of parts is growing; \ Inserts are being delayed; \ Inserts are being rejected | select value from system.asynchronous_metrics
| Critical |
| Dictionaries: exception | select concat(name,': ',last_exception)
| Medium |
| ClickHouse has been restarted | select uptime();
| |
| DistributedFilesToInsert should not be always increasing | select value from system.metrics
| Medium |
| A data part was lost | select value from system.events
| High |
| Data parts are not the same on different replicas | select value from system.events where event='DataAfterMergeDiffersFromReplica'; \
select value from system.events where event='DataAfterMutationDiffersFromReplica' | Medium |
The following queries are recommended to be included in monitoring:
SELECT * FROM system.replicas- For more information, see the ClickHouse guide on System Tables
SELECT * FROM system.merges- Checks on the speed and progress of currently executed merges.
SELECT * FROM system.mutations- This is the source of information on the speed and progress of currently executed merges.
Monitoring ClickHouse logs
ClickHouse logs can be another important source of information. There are 2 logs enabled by default
- /var/log/clickhouse-server/clickhouse-server.err.log (error & warning, you may want to keep an eye on that or send it to some monitoring system)
- /var/log/clickhouse-server/clickhouse-server.log (trace logs, very detailed, useful for debugging, usually too verbose to monitor).
You can additionally enable system.text_log table to have an access to the logs from clickhouse sql queries (ensure that you will not expose some information to the users who should not see it).
$ cat /etc/clickhouse-server/config.d/text_log.xml
<yandex>
<text_log>
<database>system</database>
<table>text_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
<level>warning</level>
</text_log>
</yandex>
OpenTelemetry support
See https://clickhouse.com/docs/en/operations/opentelemetry/
Other sources
41 - ClickHouse® versions
ClickHouse® versioning schema
Example:
21.3.10.1-lts
- 21 is the year of release.
- 3 indicates a Feature Release. This is an increment where features are delivered.
- 10 is the bugfix / maintenance version. When that version is incremented it means that some bugs was fixed comparing to 21.3.9.
- 1 - build number, means nothing for end users.
- lts - type of release. (long time support).
What is Altinity Stable version?
It is one of general / public version of ClickHouse which has passed some extra testings, the upgrade path and changelog was analyzed, known issues are documented, and at least few big companies use it on production. All those things take some time, so usually that means that Altinity Stable is always a ‘behind’ the main releases.
Altinity version - is an option for conservative users, who prefer bit older but better known things.
Usually there is no reason to use version older than Altinity Stable. If you see that new Altinity Version arrived and you still use some older version - you should for sure consider an upgrade.
Additionally for Altinity client we provide extra support for those version for a longer time (and we also support newer versions).
Which version should I use?
We recommend the following approach:
- When you start using ClickHouse and before you go on production - pick the latest stable version.
- If you already have ClickHouse running on production:
- Check all the new queries / schemas on the staging first, especially if some new ClickHouse features are used.
- Do minor (bugfix) upgrades regularly: monitor new maintenance releases of the feature release you use.
- When considering upgrade - check Altinity Stable release docs , if you want to use newer release - analyze changelog and known issues.
- Check latest stable or test versions of ClickHouse on your staging environment regularly and pass the feedback to us or on the official ClickHouse github .
- Consider blue/green or canary upgrades.
See also: https://clickhouse.tech/docs/en/faq/operations/production/
How do I upgrade?
Follow this KB article for ClickHouse version upgrade
Bugs?
ClickHouse development process goes in a very high pace and has already thousands of features. CI system doing tens of thousands of tests (including tests with different sanitizers) against every commit.
All core features are well-tested, and very stable, and code is high-quality. But as with any other software bad things may happen. Usually the most of bugs happens in the new, freshly added functionality, and in some complex combination of several features (of course all possible combinations of features just physically can’t be tested). Usually new features are adopted by the community and stabilize quickly.
What should I do if I found a bug in ClickHouse?
- First of all: try to upgrade to the latest bugfix release Example: if you use v21.3.5.42-lts but you know that v21.3.10.1-lts already exists - start with upgrade to that. Upgrades to latest maintenance releases are smooth and safe.
- Look for similar issues in github. Maybe the fix is on the way.
- If you can reproduce the bug: try to isolate it - remove some pieces of query one-by-one / simplify the scenario until the issue still reproduces. This way you can figure out which part is responsible for that bug, and you can try to create minimal reproducible example
- Once you have minimal reproducible example:
- report it to github (or to Altinity Support)
- check if it reproduces on newer ClickHouse versions
42 - Configure ClickHouse® for low memory environments
While Clickhouse® it’s typically deployed on powerful servers with ample memory and CPU, it can be deployed in resource-constrained environments like a Raspberry Pi. Whether you’re working on edge computing, IoT data collection, or simply experimenting with ClickHouse in a small-scale setup, running it efficiently on low-memory hardware can be a rewarding challenge.
TLDR;
<!-- config.xml -->
<!-- These settinsg should allow to run clickhouse in nodes with 4GB/8GB RAM -->
<clickhouse>
<!-- disable some optional components/tables -->
<mysql_port remove="1" />
<postgresql_port remove="1" />
<query_thread_log remove="1" />
<opentelemetry_span_log remove="1" />
<processors_profile_log remove="1" />
<!-- disable mlock, allowing binary pages to be unloaded from RAM, relying on Linux defaults -->
<mlock_executable>false</mlock_executable>
<!-- decrease the cache sizes -->
<mark_cache_size>268435456</mark_cache_size> <!-- 256 MB -->
<index_mark_cache_size>67108864</index_mark_cache_size> <!-- 64 MB -->
<uncompressed_cache_size>16777216</uncompressed_cache_size> <!-- 16 MB -->
<!-- control the concurrency -->
<max_thread_pool_size>2000</max_thread_pool_size>
<max_connections>64</max_connections>
<max_concurrent_queries>8</max_concurrent_queries>
<max_server_memory_usage_to_ram_ratio>0.75</max_server_memory_usage_to_ram_ratio> <!-- 75% of the RAM, leave more for the system -->
<max_server_memory_usage>0</max_server_memory_usage> <!-- We leave the overcommiter to manage available ram for queries-->
<!-- reconfigure the main pool to limit the merges (those can create problems if the insert pressure is high) -->
<background_pool_size>2</background_pool_size>
<background_merges_mutations_concurrency_ratio>2</background_merges_mutations_concurrency_ratio>
<merge_tree>
<merge_max_block_size>1024</merge_max_block_size>
<max_bytes_to_merge_at_max_space_in_pool>1073741824</max_bytes_to_merge_at_max_space_in_pool> <!-- 1 GB max part-->
<number_of_free_entries_in_pool_to_lower_max_size_of_merge>2</number_of_free_entries_in_pool_to_lower_max_size_of_merge>
<number_of_free_entries_in_pool_to_execute_mutation>2</number_of_free_entries_in_pool_to_execute_mutation>
<number_of_free_entries_in_pool_to_execute_optimize_entire_partition>2</number_of_free_entries_in_pool_to_execute_optimize_entire_partition>
<!-- Reduces memory usage during merges in system.metric_log table (enabled by default) by setting min_bytes_for_wide_part and vertical_merge_algorithm_min_bytes_to_activate to 128MB -->
<min_bytes_for_wide_part>134217728</min_bytes_for_wide_part>
<vertical_merge_algorithm_min_bytes_to_activate>134217728</vertical_merge_algorithm_min_bytes_to_activate>
</merge_tree>
<!-- shrink all pools to minimum-->
<background_buffer_flush_schedule_pool_size>1</background_buffer_flush_schedule_pool_size>
<background_merges_mutations_scheduling_policy>round_robin</background_merges_mutations_scheduling_policy>
<background_move_pool_size>1</background_move_pool_size>
<background_fetches_pool_size>1</background_fetches_pool_size>
<background_common_pool_size>2</background_common_pool_size>
<background_schedule_pool_size>8</background_schedule_pool_size>
<background_message_broker_schedule_pool_size>1</background_message_broker_schedule_pool_size>
<background_distributed_schedule_pool_size>1</background_distributed_schedule_pool_size>
<tables_loader_foreground_pool_size>0</tables_loader_foreground_pool_size>
<tables_loader_background_pool_size>0</tables_loader_background_pool_size>
</clickhouse>
<!-- users.xml -->
<clickhouse>
<profiles>
<default>
<max_threads>2</max_threads>
<max_block_size>8192</max_block_size>
<queue_max_wait_ms>1000</queue_max_wait_ms>
<max_execution_time>600</max_execution_time>
<input_format_parallel_parsing>0</input_format_parallel_parsing>
<output_format_parallel_formatting>0</output_format_parallel_formatting>
<max_bytes_before_external_group_by>3221225472</max_bytes_before_external_group_by> <!-- 3 GB -->
<max_bytes_before_external_sort>3221225472</max_bytes_before_external_sort> <!-- 3 GB -->
</default>
</profiles>
</clickhouse>
Some interesting settings to explain:
- Disabling both postgres/mysql interfaces will release some CPU/memory resources.
- Disabling some system tables like
processor_profile_log,opentelemetry_span_log, orquery_thread_logwill help reducing write amplification. Those tables write a lot of data very frequently. In a Raspi4 with 4 GB of RAM and a simple USB3.1 storage they can spend some needed resources. - Decrease mark caches. Defaults are 5GB and they are loaded into RAM (in newer versions this behavior of loading them completely in RAM can be tuned with a prewarm setting https://github.com/ClickHouse/ClickHouse/pull/71053 ) so better to reserve a reasonable amount of space in line with the total amount of RAM. For example for 4/8GB 256MB is a good value.
- Tune server memory and leave 25% for OS ops (
max_server_memory_usage_to_ram_ratio) - Tune the thread pools and queues for merges and mutations:
merge_max_block_sizewill reduce the number of rows per block when merging. Default is 8192 and this will reduce the memory usage of merges.- The
number_of_free_entries_in_poolsettings are very nice to tune how much concurrent merges are allowed in the queue. When there is less than specified number of free entries in pool , start to lower maximum size of merge to process (or to put in queue) or do not execute part mutations to leave free threads for regular merges . This is to allow small merges to process - not filling the pool with long running merges or multiple mutations. You can check clickhouse documentation to get more insights.
- Reduce the background pools and be conservative. In a Raspi4 with 4 cores and 4 GB or ram, background pool should be not bigger than the number of cores and even less if possible.
- Tune some profile settings to enable disk spilling (
max_bytes_before_external_group_byandmax_bytes_before_external_sort) and reduce the number of threads per query plus enable queuing of queries (queue_max_wait_ms) if themax_concurrent_querieslimit is exceeded. Alsomax_block_sizeis not usually touched but in this case we can lower it ro reduce RAM usage.
43 - Converting MergeTree to Replicated
To enable replication in a table that uses the MergeTree engine, you need to convert the engine to ReplicatedMergeTree. Options here are:
- Use
INSERT INTO foo_replicated SELECT * FROM foo. (suitable for small tables) - Create table aside and attach all partition from the existing table then drop original table (uses hard links don’t require extra disk space).
ALTER TABLE foo_replicated ATTACH PARTITION ID 'bar' FROM 'foo'You can easily auto generate those commands using a query like:SELECT DISTINCT 'ALTER TABLE foo_replicated ATTACH PARTITION ID \'' || partition_id || '\' FROM foo;' from system.parts WHERE table = 'foo';See the example below for details. - Do it ‘in place’ using some file manipulation. see the procedure described here: https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replication/#converting-from-mergetree-to-replicatedmergetree
- Do a backup of MergeTree and recover as ReplicatedMergeTree. https://github.com/Altinity/clickhouse-backup/blob/master/Examples.md#how-to-convert-mergetree-to-replicatedmegretree
- Embedded command for recent Clickhouse versions - https://clickhouse.com/docs/en/sql-reference/statements/attach#attach-mergetree-table-as-replicatedmergetree
Example for option 2 above
Note: ATTACH PARTITION ID 'bar' FROM 'foo' is practically free from a compute and disk space perspective. This feature utilizes filesystem hard-links and the fact that files are immutable in ClickHouse® (it’s the core of the ClickHouse design, filesystem hard-links and such file manipulations are widely used).
create table foo( A Int64, D Date, S String )
Engine MergeTree
partition by toYYYYMM(D) order by A;
insert into foo select number, today(), '' from numbers(1e8);
insert into foo select number, today()-60, '' from numbers(1e8);
select count() from foo;
┌───count()─┐
│ 200000000 │
└───────────┘
create table foo_replicated as foo
Engine ReplicatedMergeTree('/clickhouse/{cluster}/tables/{database}/{table}/{shard}','{replica}')
partition by toYYYYMM(D) order by A;
SYSTEM STOP MERGES;
SELECT DISTINCT 'ALTER TABLE foo_replicated ATTACH PARTITION ID \'' || partition_id || '\' FROM foo;' from system.parts WHERE table = 'foo' AND active;
┌─concat('ALTER TABLE foo_replicated ATTACH PARTITION ID \'', partition_id, '\' FROM foo;')─┐
│ ALTER TABLE foo_replicated ATTACH PARTITION ID '202111' FROM foo; │
│ ALTER TABLE foo_replicated ATTACH PARTITION ID '202201' FROM foo; │
└───────────────────────────────────────────────────────────────────────────────────────────┘
clickhouse-client -q "SELECT DISTINCT 'ALTER TABLE foo_replicated ATTACH PARTITION ID \'' || partition_id || '\' FROM foo;' from system.parts WHERE table = 'foo' format TabSeparatedRaw" |clickhouse-client -mn
SYSTEM START MERGES;
SELECT count() FROM foo_replicated;
┌───count()─┐
│ 200000000 │
└───────────┘
rename table foo to foo_old, foo_replicated to foo;
-- you can drop foo_old any time later, it's kinda a cheap backup,
-- it cost nothing until you insert a lot of additional data into foo_replicated
44 - Data Migration
Export & Import into common data formats
Pros:
- Data can be inserted into any DBMS.
Cons:
- Decoding & encoding of common data formats may be slower / require more CPU
- The data size is usually bigger than ClickHouse® formats.
- Some of the common data formats have limitations.
Info
The best approach to do that is using clickhouse-client, in that case, encoding/decoding of format happens client-side, while client and server speak clickhouse Native format (columnar & compressed).
In contrast: when you use HTTP protocol, the server do encoding/decoding and more data is passed between client and server.
remote/remoteSecure or cluster/Distributed table
Pros:
- Simple to run.
- It’s possible to change the schema and distribution of data between shards.
- It’s possible to copy only some subset of data.
- Needs only access to ClickHouse TCP port.
Cons:
- Uses CPU / RAM (mostly on the receiver side)
See details of both approaches in:
Manual parts moving: freeze / rsync / attach
Pros:
- Low CPU / RAM usage.
Cons:
- Table schema should be the same.
- A lot of manual operations/scripting.
Info
With some additional care and scripting, it’s possible to do cheap re-sharding on parts level.See details in:
clickhouse-backup
Pros:
- Low CPU / RAM usage.
- Suitable to recover both schema & data for all tables at once.
Cons:
- Table schema should be the same.
Just create the backup on server 1, upload it to server 2, and restore the backup.
See https://github.com/Altinity/clickhouse-backup
https://altinity.com/blog/introduction-to-clickhouse-backups-and-clickhouse-backup
Fetch from zookeeper path
Pros:
- Low CPU / RAM usage.
Cons:
- Table schema should be the same.
- Works only when the source and the destination ClickHouse servers share the same zookeeper (without chroot)
- Needs to access zookeeper and ClickHouse replication ports: (
interserver_http_portorinterserver_https_port)
ALTER TABLE table_name FETCH PARTITION partition_expr FROM 'path-in-zookeeper'
Using the replication protocol by adding a new replica
Just make one more replica in another place.
Pros:
- Simple to setup
- Data is consistent all the time automatically.
- Low CPU and network usage should be tuned.
Cons:
- Needs to reach both zookeeper client (2181) and ClickHouse replication ports: (
interserver_http_portorinterserver_https_port) - In case of cluster migration, zookeeper need’s to be migrated too.
- Replication works both ways so new replica should be outside the main cluster.
Check the details in:
See also
Github issues
https://github.com/ClickHouse/ClickHouse/issues/10943 https://github.com/ClickHouse/ClickHouse/issues/20219 https://github.com/ClickHouse/ClickHouse/pull/17871
Other links
44.1 - MSSQL bcp pipe to clickhouse-client
How to pipe data to ClickHouse® from bcp export tool for MSSQL database
Prepare tables
LAPTOP.localdomain :) CREATE TABLE tbl(key UInt32) ENGINE=MergeTree ORDER BY key;
root@LAPTOP:/home/user# sqlcmd -U sa -P Password78
1> WITH t0(i) AS (SELECT 0 UNION ALL SELECT 0), t1(i) AS (SELECT 0 FROM t0 a, t0 b), t2(i) AS (SELECT 0 FROM t1 a, t1 b), t3(i) AS (SELECT 0 FROM t2 a, t2 b), t4(i) AS (SELECT 0 FROM t3 a, t3 b), t5(i) AS (SELECT 0 FROM t4 a, t3 b),n(i) AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT 0)) FROM t5) SELECT i INTO tbl FROM n WHERE i BETWEEN 1 AND 16777216
2> GO
(16777216 rows affected)
root@LAPTOP:/home/user# sqlcmd -U sa -P Password78 -Q "SELECT count(*) FROM tbl"
-----------
16777216
(1 rows affected)
Piping
root@LAPTOP:/home/user# mkfifo import_pipe
root@LAPTOP:/home/user# bcp "SELECT * FROM tbl" queryout import_pipe -t, -c -b 200000 -U sa -P Password78 -S localhost &
[1] 6038
root@LAPTOP:/home/user#
Starting copy...
1000 rows successfully bulk-copied to host-file. Total received: 1000
1000 rows successfully bulk-copied to host-file. Total received: 2000
1000 rows successfully bulk-copied to host-file. Total received: 3000
1000 rows successfully bulk-copied to host-file. Total received: 4000
1000 rows successfully bulk-copied to host-file. Total received: 5000
1000 rows successfully bulk-copied to host-file. Total received: 6000
1000 rows successfully bulk-copied to host-file. Total received: 7000
1000 rows successfully bulk-copied to host-file. Total received: 8000
1000 rows successfully bulk-copied to host-file. Total received: 9000
1000 rows successfully bulk-copied to host-file. Total received: 10000
1000 rows successfully bulk-copied to host-file. Total received: 11000
1000 rows successfully bulk-copied to host-file. Total received: 12000
1000 rows successfully bulk-copied to host-file. Total received: 13000
1000 rows successfully bulk-copied to host-file. Total received: 14000
1000 rows successfully bulk-copied to host-file. Total received: 15000
1000 rows successfully bulk-copied to host-file. Total received: 16000
1000 rows successfully bulk-copied to host-file. Total received: 17000
1000 rows successfully bulk-copied to host-file. Total received: 18000
1000 rows successfully bulk-copied to host-file. Total received: 19000
1000 rows successfully bulk-copied to host-file. Total received: 20000
1000 rows successfully bulk-copied to host-file. Total received: 21000
1000 rows successfully bulk-copied to host-file. Total received: 22000
1000 rows successfully bulk-copied to host-file. Total received: 23000
-- Enter
root@LAPTOP:/home/user# cat import_pipe | clickhouse-client --query "INSERT INTO tbl FORMAT CSV" &
...
1000 rows successfully bulk-copied to host-file. Total received: 16769000
1000 rows successfully bulk-copied to host-file. Total received: 16770000
1000 rows successfully bulk-copied to host-file. Total received: 16771000
1000 rows successfully bulk-copied to host-file. Total received: 16772000
1000 rows successfully bulk-copied to host-file. Total received: 16773000
1000 rows successfully bulk-copied to host-file. Total received: 16774000
1000 rows successfully bulk-copied to host-file. Total received: 16775000
1000 rows successfully bulk-copied to host-file. Total received: 16776000
1000 rows successfully bulk-copied to host-file. Total received: 16777000
16777216 rows copied.
Network packet size (bytes): 4096
Clock Time (ms.) Total : 11540 Average : (1453831.5 rows per sec.)
[1]- Done bcp "SELECT * FROM tbl" queryout import_pipe -t, -c -b 200000 -U sa -P Password78 -S localhost
[2]+ Done cat import_pipe | clickhouse-client --query "INSERT INTO tbl FORMAT CSV"
Another shell
root@LAPTOP:/home/user# for i in `seq 1 600`; do clickhouse-client -q "select count() from tbl";sleep 1; done
0
0
0
0
0
0
1048545
4194180
6291270
9436905
11533995
13631085
16777216
16777216
16777216
16777216
44.2 - Add/Remove a new replica to a ClickHouse® cluster
clickhouse-backupADD nodes/replicas to a ClickHouse® cluster
To add some ClickHouse® replicas to an existing cluster if -30TB then better to use replication:
- don’t add the
remote_servers.xmluntil replication is done. - Add these files and restart to limit bandwidth and avoid saturation (70% total bandwidth):
Core Settings | ClickHouse Docs
💡 Do the Gbps to Bps math correctly. For 10G —> 1250MB/s —> 1250000000 B/s. Change the max_replicated_* settings accordingly and add them to a file in /etc/clickhouse-server/config.d/ (e.g., config.d/replication-limits.xml) and restart ClickHouse:
- Nodes replicating from:
<clickhouse>
<max_replicated_sends_network_bandwidth_for_server>50000</max_replicated_sends_network_bandwidth_for_server>
</clickhouse>
- Nodes replicating to:
<clickhouse>
<max_replicated_fetches_network_bandwidth_for_server>50000</max_replicated_fetches_network_bandwidth_for_server>
</clickhouse>
Manual method (DDL)
- Create tables
manuallyand be sure macros in all replicas are aligned with the ZK path. If zk path uses{cluster}then this method won’t work. ZK path should use{shard}and{replica}or{uuid}(if databases are Atomic) only.
-- DDL for Databases
SELECT concat('CREATE DATABASE "', name, '" ENGINE = ', engine_full, ';')
FROM system.databases WHERE name NOT IN ('system', 'information_schema', 'INFORMATION_SCHEMA')
INTO OUTFILE '/tmp/databases.sql'
FORMAT TSVRaw;
-- DDL for tables and views
SELECT
replaceRegexpOne(replaceOne(concat(create_table_query, ';'), '(', 'ON CLUSTER \'{cluster}\' ('), 'CREATE (TABLE|DICTIONARY|VIEW|LIVE VIEW|WINDOW VIEW)', 'CREATE \\1 IF NOT EXISTS')
FROM
system.tables
WHERE engine != 'MaterializedView' and
database NOT IN ('system', 'information_schema', 'INFORMATION_SCHEMA') AND
create_table_query != '' AND
name NOT LIKE '.inner.%%' AND
name NOT LIKE '.inner_id.%%'
INTO OUTFILE '/tmp/schema.sql' AND STDOUT
FORMAT TSVRaw
SETTINGS show_table_uuid_in_table_create_query_if_not_nil=1;
--- DDL only for materialized views
SELECT
replaceRegexpOne(replaceOne(concat(create_table_query, ';'), 'TO', 'ON CLUSTER \'{cluster}\' TO'), '(CREATE MATERIALIZED VIEW)', '\\1 IF NOT EXISTS')
FROM
system.tables
WHERE engine = 'MaterializedView' and
database NOT IN ('system', 'information_schema', 'INFORMATION_SCHEMA') AND
create_table_query != '' AND
name NOT LIKE '.inner.%%' AND
name NOT LIKE '.inner_id.%%' AND
as_select != ''
INTO OUTFILE '/tmp/schema.sql' APPEND AND STDOUT
FORMAT TSVRaw
SETTINGS show_table_uuid_in_table_create_query_if_not_nil=1;
This will generate the UUIDs in the CREATE TABLE definition, something like this:
CREATE TABLE IF NOT EXISTS default.insert_test UUID '51b41170-5192-4947-b13b-d4094c511f06' ON CLUSTER '{cluster}' (`id_order` UInt16, `id_plat` UInt32, `id_warehouse` UInt64, `id_product` UInt16, `order_type` UInt16, `order_status` String, `datetime_order` DateTime, `units` Int16, `total` Float32) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{uuid}/{shard}', '{replica}') PARTITION BY tuple() ORDER BY (id_order, id_plat, id_warehouse) SETTINGS index_granularity = 8192;
- Copy both SQL to destination replica and execute
clickhouse-client --host localhost --port 9000 -mn < databases.sql
clickhouse-client --host localhost --port 9000 -mn < schema.sql
Using clickhouse-backup
- Before proceeding: check if you have
restore_schema_on_clusterset; if it is, this procedure will drop tables withON CLUSTER, which is not its intention! To verify:
$ clickhouse-backup print-config|grep restore_schema_on_cluster
restore_schema_on_cluster: ""
- Using
clickhouse-backupto copy the schema of a replica to another is also convenient, and if using Atomic database with{uuid}macros in ReplicatedMergeTree engines .
$ sudo -u clickhouse clickhouse-backup create --schema --rbac --named-collections rbac_and_schema
# From the destination replica do this in 2 steps (for safety, keep --env=RESTORE_SCHEMA_ON_CLUSTER=):
$ sudo -u clickhouse clickhouse-backup restore --env=RESTORE_SCHEMA_ON_CLUSTER= --rbac-only rbac_and_schema
$ sudo -u clickhouse clickhouse-backup restore --env=RESTORE_SCHEMA_ON_CLUSTER= --schema --named-collections rbac_and_schema
Using altinity operator
If there is at least one alive replica in the shard, you can remove PVCs and STS for affected nodes and trigger reconciliation. The operator will try to copy the schema from other replicas.
Check that schema migration was successful and node is replicating
- To check that the schema migration has been successful query system.replicas:
SELECT DISTINCT database,table,replica_is_active FROM system.replicas FORMAT Vertical
Check how the replication process is performing using https://kb.altinity.com/altinity-kb-setup-and-maintenance/altinity-kb-replication-queue/
- If there are many postponed tasks with the message:
Not executing fetch of part 7_22719661_22719661_0 because 16 fetches already executing, max 16. │ 2023-09-25 17:03:06 │ │then it is ok, the maximum replication slots are being used. Exceptions are not OK and should be investigated
If migration was successful and replication is working, then wait until the replication is finished. It may take some days, depending on how much data is being replicated. After this edit, the cluster configuration xml file for all replicas (
remote_servers.xml), and add the new replica to the cluster.
Possible problems
Exception REPLICA_ALREADY_EXISTS
Code: 253. DB::Exception: Received from localhost:9000.
DB::Exception: There was an error on [dl-ny2-vm-09.internal.io:9000]:
Code: 253. DB::Exception: Replica /clickhouse/tables/3c3503c3-ed3c-443b-9cb3-ef41b3aed0a8/1/replicas/dl-ny2-vm-09.internal.io
already exists. (REPLICA_ALREADY_EXISTS) (version 23.5.3.24 (official build)). (REPLICA_ALREADY_EXISTS)
(query: CREATE TABLE IF NOT EXISTS xxxx.yyyy UUID '3c3503c3-ed3c-443b-9cb3-ef41b3aed0a8'
The DDLs have been executed and some tables have been created and after that dropped but some left overs are left in ZK:
- If databases can be dropped then use
DROP DATABASE xxxxx SYNC - If databases cannot be dropped use
SYSTEM DROP REPLICA ‘replica_name’ FROM db.table
Exception TABLE_ALREADY_EXISTS
Code: 57. DB::Exception: Received from localhost:9000.
DB::Exception: There was an error on [dl-ny2-vm-09.internal.io:9000]:
Code: 57. DB::Exception: Directory for table data store/3c3/3c3503c3-ed3c-443b-9cb3-ef41b3aed0a8/ already exists.
(TABLE_ALREADY_EXISTS) (version 23.5.3.24 (official build)). (TABLE_ALREADY_EXISTS)
(query: CREATE TABLE IF NOT EXISTS xxxx.yyyy UUID '3c3503c3-ed3c-443b-9cb3-ef41b3aed0a8' ON CLUSTER '{cluster}'
Tables have not been dropped correctly:
- If databases can be dropped then use
DROP DATABASE xxxxx SYNC - If databases cannot be dropped use:
SELECT concat('DROP TABLE ', database, '.', name, ' SYNC;')
FROM system.tables
WHERE database NOT IN ('system', 'information_schema', 'INFORMATION_SCHEMA')
INTO OUTFILE '/tmp/drop_tables.sql'
FORMAT TSVRaw;
Tuning
- Sometimes replication goes very fast and if you have a tiered storage hot/cold you could run out of space, so for that it is interesting to:
- reduce fetches from 8 to 4
- increase moves from 8 to 16
Add these settings to a file in /etc/clickhouse-server/config.d/ (e.g., config.d/replication-limits.xml) and restart ClickHouse:
<clickhouse>
<max_replicated_fetches_network_bandwidth_for_server>625000000</max_replicated_fetches_network_bandwidth_for_server>
<background_fetches_pool_size>4</background_fetches_pool_size>
<background_move_pool_size>16</background_move_pool_size>
</clickhouse>
- Also to monitor this with:
SELECT *
FROM system.metrics
WHERE metric LIKE '%Move%'
Query id: 5050155b-af4a-474f-a07a-f2f7e95fb395
┌─metric─────────────────┬─value─┬─description──────────────────────────────────────────────────┐
│ BackgroundMovePoolTask │ 0 │ Number of active tasks in BackgroundProcessingPool for moves │
└────────────────────────┴───────┴──────────────────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.164 sec.
dnieto-test :) SELECT * FROM system.metrics WHERE metric LIKE '%Fetch%';
SELECT *
FROM system.metrics
WHERE metric LIKE '%Fetch%'
Query id: 992cae2a-fb58-4150-a088-83273805d0c4
┌─metric────────────────────┬─value─┬─description───────────────────────────────────────────────┐
│ ReplicatedFetch │ 0 │ Number of data parts being fetched from replica │
│ BackgroundFetchesPoolTask │ 0 │ Number of active fetches in an associated background pool │
└───────────────────────────┴───────┴───────────────────────────────────────────────────────────┘
2 rows in set. Elapsed: 0.163 sec.
- There are new tables in v23
system.replicated_fetchesandsystem.movescheck it out for more info. - if needed just stop replication using
SYSTEM STOP FETCHESfrom the replicating nodes
REMOVE nodes/Replicas from a Cluster
- It is important to know which replica/node you want to remove to avoid problems. To check it you need to connect to a different replica/node that the one you want to remove. For instance we want to remove
arg_t04, so we connected to replicaarg_t01:
SELECT DISTINCT arrayJoin(mapKeys(replica_is_active)) AS replica_name
FROM system.replicas
┌─replica_name─┐
│ arg_t01 │
│ arg_t02 │
│ arg_t03 │
│ arg_t04 │
└──────────────┘
- After that (make sure you’re connected to a replica different from the one that you want to remove,
arg_tg01) and execute:
SYSTEM DROP REPLICA 'arg_t04'
- If by any chance you’re connected to the same replica you want to remove then
SYSTEM DROP REPLICAwill not work. - BTW
SYSTEM DROP REPLICAdoes not drop any tables and does not remove any data or metadata from disk, it will only remove metadata from Zookeeper/Keeper
-- What happens if executing system drop replica in the local replica to remove.
SYSTEM DROP REPLICA 'arg_t04'
Elapsed: 0.017 sec.
Received exception from server (version 23.8.6):
Code: 305. DB::Exception: Received from dnieto-zenbook.lan:9440. DB::Exception: We can't drop local replica, please use `DROP TABLE` if you want to clean the data and drop this replica. (TABLE_WAS_NOT_DROPPED)
- After DROP REPLICA, we need to check that the replica is gone from the list or replicas:
SELECT DISTINCT arrayJoin(mapKeys(replica_is_active)) AS replica_name
FROM system.replicas
┌─replica_name─┐
│ arg_t01 │
│ arg_t02 │
│ arg_t03 │
└──────────────┘
-- We should see there is no replica arg_t04
- Delete the replica in the cluster configuration:
remote_servers.xmland shutdown the node/replica removed.
44.3 - clickhouse-copier
The description of the utility and its parameters, as well as examples of the config files that you need to create for the copier are in the official repo for the ClickHouse® copier utility
The steps to run a task:
Create a config file for
clickhouse-copier(zookeeper.xml)Create a config file for the task (task1.xml)
Create the task in ZooKeeper and start an instance of
clickhouse-copierclickhouse-copier --daemon --base-dir=/opt/clickhouse-copier --config=/opt/clickhouse-copier/zookeeper.xml --task-path=/clickhouse/copier/task1 --task-file=/opt/clickhouse-copier/task1.xmlIf the node in ZooKeeper already exists and you want to change it, you need to add the
task-upload-forceparameter:clickhouse-copier --daemon --base-dir=/opt/clickhouse-copier --config=/opt/clickhouse-copier/zookeeper.xml --task-path=/clickhouse/copier/task1 --task-file=/opt/clickhouse-copier/task1.xml --task-upload-force=1If you want to run another instance of
clickhouse-copierfor the same task, you need to copy the config file (zookeeper.xml) to another server, and run this command:clickhouse-copier --daemon --base-dir=/opt/clickhouse-copier --config=/opt/clickhouse-copier/zookeeper.xml --task-path=/clickhouse/copier/task1
The number of simultaneously running instances is controlled be the max_workers parameter in your task configuration file. If you run more workers superfluous workers will sleep and log messages like this:
<Debug> ClusterCopier: Too many workers (1, maximum 1). Postpone processing
See also
- https://github.com/clickhouse/copier/
- Никита Михайлов. Кластер ClickHouse ctrl-с ctrl-v. HighLoad++ Весна 2021 slides
- 21.7 have a huge bulk of fixes / improvements. https://github.com/ClickHouse/ClickHouse/pull/23518
- https://altinity.com/blog/2018/8/22/clickhouse-copier-in-practice
- https://github.com/getsentry/snuba/blob/master/docs/clickhouse-copier.md
- https://hughsite.com/post/clickhouse-copier-usage.html
- https://www.jianshu.com/p/c058edd664a6
44.3.1 - clickhouse-copier 20.3 and earlier
clickhouse-copier was created to move data between clusters.
It runs simple INSERT…SELECT queries and can copy data between tables with different engine parameters and between clusters with different number of shards.
In the task configuration file you need to describe the layout of the source and the target cluster, and list the tables that you need to copy. You can copy whole tables or specific partitions.
clickhouse-copier uses temporary distributed tables to select from the source cluster and insert into the target cluster.
The process is as follows
- Process the configuration files.
- Discover the list of partitions if not provided in the config.
- Copy partitions one by one.
- Drop the partition from the target table if it’s not empty
- Copy data from source shards one by one.
- Check if there is data for the partition on a source shard.
- Check the status of the task in ZooKeeper.
- Create target tables on all shards of the target cluster.
- Insert the partition of data into the target table.
- Mark the partition as completed in ZooKeeper.
If there are several workers running simultaneously, they will assign themselves to different source shards. If a worker was interrupted, another worker can be started to continue the task. The next worker will drop incomplete partitions and resume the copying.
Configuring the engine of the target table
clickhouse-copier uses the engine from the task configuration file for these purposes:
- to create target tables if they don’t exist.
- PARTITION BY: to SELECT a partition of data from the source table, to DROP existing partitions from target tables.
clickhouse-copier does not support the old MergeTree format.
However, you can create the target tables manually and specify the engine in the task configuration file in the new format so that clickhouse-copier can parse it for its SELECT queries.
How to monitor the status of running tasks
clickhouse-copier uses ZooKeeper to keep track of the progress and to communicate between workers.
Here is a list of queries that you can use to see what’s happening.
--task-path /clickhouse/copier/task1
-- The task config
select * from system.zookeeper
where path='<task-path>'
name | ctime | mtime
----------------------------+---------------------+--------------------
description | 2019-10-18 15:40:00 | 2020-09-11 16:01:14
task_active_workers_version | 2019-10-18 16:00:09 | 2020-09-11 16:07:08
tables | 2019-10-18 16:00:25 | 2019-10-18 16:00:25
task_active_workers | 2019-10-18 16:00:09 | 2019-10-18 16:00:09
-- Running workers
select * from system.zookeeper
where path='<task-path>/task_active_workers'
-- The list of processed tables
select * from system.zookeeper
where path='<task-path>/tables'
-- The list of processed partitions
select * from system.zookeeper
where path='<task-path>/tables/<table>'
name | ctime
-------+--------------------
201909 | 2019-10-18 18:24:18
-- The status of a partition
select * from system.zookeeper
where path='<task-path>/tables/<table>/<partition>'
name | ctime
-------------------------+--------------------
shards | 2019-10-18 18:24:18
partition_active_workers | 2019-10-18 18:24:18
-- The status of source shards
select * from system.zookeeper
where path='<task-path>/tables/<table>/<partition>/shards'
name | ctime | mtime
-----+---------------------+--------------------
1 | 2019-10-18 22:37:48 | 2019-10-18 22:49:29
44.3.2 - clickhouse-copier 20.4 - 21.6
clickhouse-copier was created to move data between clusters.
It runs simple INSERT…SELECT queries and can copy data between tables with different engine parameters and between clusters with different number of shards.
In the task configuration file you need to describe the layout of the source and the target cluster, and list the tables that you need to copy. You can copy whole tables or specific partitions.
clickhouse-copier uses temporary distributed tables to select from the source cluster and insert into the target cluster.
The behavior of clickhouse-copier was changed in 20.4:
- Now
clickhouse-copierinserts data into intermediate tables, and after the insert finishes successfullyclickhouse-copierattaches the completed partition into the target table. This allows for incremental data copying, because the data in the target table is intact during the process. Important note: ATTACH PARTITION respects themax_partition_size_to_droplimit. Make sure themax_partition_size_to_droplimit is big enough (or set to zero) in the destination cluster. Ifclickhouse-copieris unable to attach a partition because of the limit, it will proceed to the next partition, and it will drop the intermediate table when the task is finished (if the intermediate table is less than themax_table_size_to_droplimit). Another important note: ATTACH PARTITION is replicated. The attached partition will need to be downloaded by the other replicas. This can create significant network traffic between ClickHouse nodes. If an attach takes a long time,clickhouse-copierwill log a timeout and will proceed to the next step. - Now
clickhouse-copiersplits the source data into chunks and copies them one by one. This is useful for big source tables, when inserting one partition of data can take hours. If there is an error during the insertclickhouse-copierhas to drop the whole partition and start again. Thenumber_of_splitsparameter lets you split your data into chunks so that in case of an exceptionclickhouse-copierhas to re-insert only one chunk of the data. - Now
clickhouse-copierrunsOPTIMIZE target_table PARTITION ... DEDUPLICATEfor non-Replicated MergeTree tables. Important note: This is a very strange feature that can do more harm than good. We recommend to disable it by configuring the engine of the target table as Replicated in the task configuration file, and create the target tables manually if they are not supposed to be replicated. Intermediate tables are always created as plain MergeTree.
The process is as follows
- Process the configuration files.
- Discover the list of partitions if not provided in the config.
- Copy partitions one by one ** The metadata in ZooKeeper suggests the order described here.**
- Copy chunks of data one by one.
- Copy data from source shards one by one.
- Create intermediate tables on all shards of the target cluster.
- Check the status of the chunk in ZooKeeper.
- Drop the partition from the intermediate table if the previous attempt was interrupted.
- Insert the chunk of data into the intermediate tables.
- Mark the shard as completed in ZooKeeper
- Copy data from source shards one by one.
- Attach the chunks of the completed partition into the target table one by one
- Attach a chunk into the target table.
- non-Replicated: Run OPTIMIZE target_table DEDUPLICATE for the partition on the target table.
- Copy chunks of data one by one.
- Drop intermediate tables (may not succeed if the tables are bigger than
max_table_size_to_drop).
If there are several workers running simultaneously, they will assign themselves to different source shards. If a worker was interrupted, another worker can be started to continue the task. The next worker will drop incomplete partitions and resume the copying.
Configuring the engine of the target table
clickhouse-copier uses the engine from the task configuration file for these purposes:
- to create target and intermediate tables if they don’t exist.
- PARTITION BY: to SELECT a partition of data from the source table, to ATTACH partitions into target tables, to DROP incomplete partitions from intermediate tables, to OPTIMIZE partitions after they are attached to the target.
- ORDER BY: to SELECT a chunk of data from the source table.
Here is an example of SELECT that clickhouse-copier runs to get the sixth of ten chunks of data:
WHERE (<the PARTITION BY clause> = (<a value of the PARTITION BY expression> AS partition_key))
AND (cityHash64(<the ORDER BY clause>) % 10 = 6 )
clickhouse-copier does not support the old MergeTree format.
However, you can create the intermediate tables manually with the same engine as the target tables (otherwise ATTACH will not work), and specify the engine in the task configuration file in the new format so that clickhouse-copier can parse it for SELECT, ATTACH PARTITION and DROP PARTITION queries.
Important note: always configure engine as Replicated to disable OPTIMIZE … DEDUPLICATE (unless you know why you need clickhouse-copier to run OPTIMIZE … DEDUPLICATE).
How to configure the number of chunks
The default value for number_of_splits is 10.
You can change this parameter in the table section of the task configuration file. We recommend setting it to 1 for smaller tables.
<cluster_push>target_cluster</cluster_push>
<database_push>target_database</database_push>
<table_push>target_table</table_push>
<number_of_splits>1</number_of_splits>
<engine>Engine=Replicated...<engine>
How to monitor the status of running tasks
clickhouse-copier uses ZooKeeper to keep track of the progress and to communicate between workers.
Here is a list of queries that you can use to see what’s happening.
--task-path=/clickhouse/copier/task1
-- The task config
select * from system.zookeeper
where path='<task-path>'
name | ctime | mtime
----------------------------+---------------------+--------------------
description | 2021-03-22 13:15:48 | 2021-03-22 13:25:28
status | 2021-03-22 13:15:48 | 2021-03-22 13:25:28
task_active_workers_version | 2021-03-22 13:15:48 | 2021-03-22 20:32:09
tables | 2021-03-22 13:16:47 | 2021-03-22 13:16:47
task_active_workers | 2021-03-22 13:15:48 | 2021-03-22 13:15:48
-- Status
select * from system.zookeeper
where path='<task-path>/status'
-- Running workers
select * from system.zookeeper
where path='<task-path>/task_active_workers'
-- The list of processed tables
select * from system.zookeeper
where path='<task-path>/tables'
-- The list of processed partitions
select * from system.zookeeper
where path='<task-path>/tables/<table>'
name | ctime
-------+--------------------
202103 | 2021-03-22 13:16:47
202102 | 2021-03-22 13:18:31
202101 | 2021-03-22 13:27:36
202012 | 2021-03-22 14:05:08
-- The status of a partition
select * from system.zookeeper
where path='<task-path>/tables/<table>/<partition>'
name | ctime
---------------+--------------------
piece_0 | 2021-03-22 13:18:31
attach_is_done | 2021-03-22 14:05:05
-- The status of a piece
select * from system.zookeeper
where path='<task-path>/tables/<table>/<partition>/piece_N'
name | ctime
-------------------------------+--------------------
shards | 2021-03-22 13:18:31
is_dirty | 2021-03-22 13:26:51
partition_piece_active_workers | 2021-03-22 13:26:54
clean_start | 2021-03-22 13:26:54
-- The status of source shards
select * from system.zookeeper
where path='<task-path>/tables/<table>/<partition>/piece_N/shards'
name | ctime | mtime
-----+---------------------+--------------------
1 | 2021-03-22 13:26:54 | 2021-03-22 14:05:05
44.3.3 - Kubernetes job for clickhouse-copier
clickhouse-copierclickhouse-copier deployment in kubernetes
clickhouse-copier can be deployed in a kubernetes environment to automate some simple backups or copy fresh data between clusters.
Some documentation to read:
- https://kb.altinity.com/altinity-kb-setup-and-maintenance/altinity-kb-data-migration/altinity-kb-clickhouse-copier/
- https://github.com/clickhouse/copier/
Deployment
Use a kubernetes job is recommended but a simple pod can be used if you only want to execute the copy one time.
Just edit/change all the yaml files to your needs.
1) Create the PVC:
First create a namespace in which all the pods and resources are going to be deployed
kubectl create namespace clickhouse-copier
Then create the PVC using a storageClass gp2-encrypted class or use any other storageClass from other providers:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: copier-logs
namespace: clickhouse-copier
spec:
storageClassName: gp2-encrypted
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
and deploy:
kubectl -n clickhouse-copier create -f ./kubernetes/copier-pvc.yaml
2) Create the configmap:
The configmap has both files zookeeper.xml and task01.xml with the zookeeper node listing and the parameters for the task respectively.
---
apiVersion: v1
kind: ConfigMap
metadata:
name: copier-config
namespace: clickhouse-copier
data:
task01.xml: |
<clickhouse>
<logger>
<console>true</console>
<log remove="remove"/>
<errorlog remove="remove"/>
<level>trace</level>
</logger>
<remote_servers>
<all-replicated>
<shard>
<replica>
<host>clickhouse01.svc.cluster.local</host>
<port>9000</port>
<user>chcopier</user>
<password>pass</password>
</replica>
<replica>
<host>clickhouse02.svc.cluster.local</host>
<port>9000</port>
<user>chcopier</user>
<password>pass</password>
</replica>
</shard>
</all-replicated>
<all-sharded>
<!-- <secret></secret> -->
<shard>
<replica>
<host>clickhouse03.svc.cluster.local</host>
<port>9000</port>
<user>chcopier</user>
<password>pass</password>
</replica>
</shard>
<shard>
<replica>
<host>clickhouse03.svc.cluster.local</host>
<port>9000</port>
<user>chcopier</user>
<password>pass</password>
</replica>
</shard>
</all-sharded>
</remote_servers>
<max_workers>1</max_workers>
<settings_pull>
<readonly>1</readonly>
</settings_pull>
<settings_push>
<readonly>0</readonly>
</settings_push>
<settings>
<connect_timeout>3</connect_timeout>
<insert_distributed_sync>1</insert_distributed_sync>
</settings>
<tables>
<table_sales>
<cluster_pull>all-replicated</cluster_pull>
<database_pull>default</database_pull>
<table_pull>fact_sales_event</table_pull>
<cluster_push>all-sharded</cluster_push>
<database_push>default</database_push>
<table_push>fact_sales_event</table_push>
<engine>
Engine=ReplicatedMergeTree('/clickhouse/{cluster}/tables/{shard}/fact_sales_event', '{replica}')
PARTITION BY toYYYYMM(timestamp)
ORDER BY (channel_id, product_id)
SETTINGS index_granularity = 8192
</engine>
<sharding_key>rand()</sharding_key>
</table_ventas>
</tables>
</clickhouse>
zookeeper.xml: |
<clickhouse>
<logger>
<level>trace</level>
<size>100M</size>
<count>3</count>
</logger>
<zookeeper>
<node>
<host>zookeeper1.svc.cluster.local</host>
<port>2181</port>
</node>
<node>
<host>zookeeper2.svc.cluster.local</host>
<port>2181</port>
</node>
<node>
<host>zookeeper3.svc.cluster.local</host>
<port>2181</port>
</node>
</zookeeper>
</clickhouse>
and deploy:
kubectl -n clickhouse-copier create -f ./kubernetes/copier-configmap.yaml
The task01.xml file has many parameters to take into account explained in the repo for clickhouse-copier
. Important to note that it is needed a FQDN for the Zookeeper nodes and ClickHouse® server that are valid for the cluster. As the deployment creates a new namespace, it is recommended to use a FQDN linked to a service. For example zookeeper01.svc.cluster.local. This file should be adapted to both clusters topologies and to the needs of the user.
The zookeeper.xml file is pretty straightforward with a simple 3 node ensemble configuration.
3) Create the job:
Basically the job will download the official ClickHouse image and will create a pod with 2 containers:
clickhouse-copier: This container will run the clickhouse-copier utility.
sidecar-logging: This container will be used to read the logs of the clickhouse-copier container for different runs (this part can be improved):
---
apiVersion: batch/v1
kind: Job
metadata:
name: clickhouse-copier-test
namespace: clickhouse-copier
spec:
# only for kubernetes 1.23
# ttlSecondsAfterFinished: 86400
template:
spec:
containers:
- name: clickhouse-copier
image: clickhouse/clickhouse-server:21.8
command:
- clickhouse-copier
- --task-upload-force=1
- --config-file=$(CH_COPIER_CONFIG)
- --task-path=$(CH_COPIER_TASKPATH)
- --task-file=$(CH_COPIER_TASKFILE)
- --base-dir=$(CH_COPIER_BASEDIR)
env:
- name: CH_COPIER_CONFIG
value: "/var/lib/clickhouse/tmp/zookeeper.xml"
- name: CH_COPIER_TASKPATH
value: "/clickhouse/copier/tasks/task01"
- name: CH_COPIER_TASKFILE
value: "/var/lib/clickhouse/tmp/task01.xml"
- name: CH_COPIER_BASEDIR
value: "/var/lib/clickhouse/tmp"
resources:
limits:
cpu: "1"
memory: 2048Mi
volumeMounts:
- name: copier-config
mountPath: /var/lib/clickhouse/tmp/zookeeper.xml
subPath: zookeeper.xml
- name: copier-config
mountPath: /var/lib/clickhouse/tmp/task01.xml
subPath: task01.xml
- name: copier-logs
mountPath: /var/lib/clickhouse/tmp
- name: sidecar-logger
image: busybox:1.35
command: ['/bin/sh', '-c', 'tail', '-n', '1000', '-f', '/tmp/copier-logs/clickhouse-copier*/*.log']
resources:
limits:
cpu: "1"
memory: 512Mi
volumeMounts:
- name: copier-logs
mountPath: /tmp/copier-logs
volumes:
- name: copier-config
configMap:
name: copier-config
items:
- key: zookeeper.xml
path: zookeeper.xml
- key: task01.xml
path: task01.xml
- name: copier-logs
persistentVolumeClaim:
claimName: copier-logs
restartPolicy: Never
backoffLimit: 3
Deploy and watch progress checking the logs:
kubectl -n clickhouse-copier logs <podname> sidecar-logging
44.4 - Distributed table to ClickHouse® Cluster
In order to shift INSERTS to a standby cluster (for example increase zone availability or disaster recovery ) some ClickHouse® features can be used.
Basically we need to create a distributed table, a MV, rewrite the remote_servers.xml config file and tune some parameters.
Distributed engine information and parameters: https://clickhouse.com/docs/en/engines/table-engines/special/distributed/
Steps
Create a Distributed table in the source cluster
For example, we should have a ReplicatedMergeTree table in which all inserts are falling. This table is the first step in our pipeline:
CREATE TABLE db.inserts_source ON CLUSTER 'source'
(
column1 String
column2 DateTime
.....
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/inserts_source', '{replica}')
PARTITION BY toYYYYMM(column2)
ORDER BY (column1, column2)
This table lives in the source cluster and all INSERTS go there. In order to shift all INSERTS in the source cluster to destination cluster we can create a Distributed table that points to another ReplicatedMergeTree in the destination cluster:
CREATE TABLE db.inserts_source_dist ON CLUSTER 'source'
(
column1 String
column2 DateTime
.....
)
ENGINE = Distributed('destination', db, inserts_destination)
Create a Materialized View to shift INSERTS to destination cluster:
CREATE MATERIALIZED VIEW shift_inserts ON CLUSTER 'source'
TO db.inserts_source_dist AS
SELECT * FROM db.inserts_source
Create a ReplicatedMergeTree table in the destination cluster:
This is the table in the destination cluster that is pointed by the distributed table in the source cluster
CREATE TABLE db.inserts_destination ON CLUSTER 'destination'
(
column1 String
column2 DateTime
.....
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/inserts_destination', '{replica}')
PARTITION BY toYYYYMM(column2)
ORDER BY (column1, column2)
Rewrite remote_servers.xml:
All the hostnames/FQDN from each replica/node must be accessible from both clusters. Also the remote_servers.xml from the source cluster should read like this:
<clickhouse>
<remote_servers>
<source>
<shard>
<replica>
<host>host03</host>
<port>9000</port>
</replica>
<replica>
<host>host04</host>
<port>9000</port>
</replica>
</shard>
</source>
<destination>
<shard>
<replica>
<host>host01</host>
<port>9000</port>
</replica>
<replica>
<host>host02</host>
<port>9000</port>
</replica>
</shard>
</destination>
<!-- If using a LB to shift inserts you need to use user and password and create MT destination table in an all-replicated cluster config -->
<destination_with_lb>
<shard>
<replica>
<host>load_balancer.xxxx.com</host>
<port>9440</port>
<secure>1</secure>
<username>user</username>
<password>pass</password>
</replica>
</shard>
</destination_with_lb>
</remote_servers>
</clickhouse>
Configuration settings
Depending on your use case you can set the the distributed INSERTs to sync or async mode . This example is for async mode: Put this config settings on the default profile. Check for more info about the possible modes:
https://clickhouse.com/docs/en/operations/settings/settings#insert_distributed_sync
<clickhouse>
....
<profiles>
<default>
<!-- StorageDistributed DirectoryMonitors try to batch individual inserts into bigger ones to increase performance -->
<distributed_directory_monitor_batch_inserts>1</distributed_directory_monitor_batch_inserts>
<!-- StorageDistributed DirectoryMonitors try to split batch into smaller in case of failures -->
<distributed_directory_monitor_split_batch_on_failure>1</distributed_directory_monitor_split_batch_on_failure>
</default>
.....
</profiles>
</clickhouse>
44.5 - Fetch Alter Table
FETCH Parts from Zookeeper
This is a detailed explanation on how to move data by fetching partitions or parts between replicas
Get partitions by database and table:
SELECT
hostName() AS host,
database,
table
partition_id,
name as part_id
FROM cluster('{cluster}', system.parts)
WHERE database IN ('db1','db2' ... 'dbn') AND active
This query will return all the partitions and parts stored in this node for the databases and their tables.
Fetch the partitions:
Prior starting with the fetching process it is recommended to check the system.detached_parts table of the destination node. There is a chance that detached folders already contain some old parts, and you will have to remove them all before starting moving data. Otherwise you will attach those old parts together with the fetched parts. Also you could run into issues if there are detached folders with the same names as the ones you are fetching (not very probable, put possible). Simply delete the detached parts and continue with the process.
To fetch a partition:
ALTER TABLE <tablename> FETCH PARTITION <partition_id> FROM '/clickhouse/{cluster}/tables/{shard}/{table}'
The FROM path is from the zookeeper node and you have to specify the shard from you’re fetching the partition
. Next executing the DDL query:
ALTER TABLE <tablename> ATTACH PARTITION <partition_id>
will attach the partitions to a table. Again and because the process is manual, it is recommended to check that the fetched partitions are attached correctly and that there are no detached parts left. Check both system.parts and system.detached_parts tables.
Detach tables and delete replicas:
If needed, after moving the data and checking that everything is sound, you can detach the tables and delete the replicas.
-- Required for DROP REPLICA
DETACH TABLE <table_name>;
-- This will remove everything from /table_path_in_z/replicas/replica_name
-- but not the data. You could reattach the table again and
-- restore the replica if needed. Get the zookeeper_path and replica_name from system.replicas
SYSTEM DROP REPLICA 'replica_name' FROM ZKPATH '/table_path_in_zk/';
Query to generate all the DDL:
With this query you can generate the DDL script that will do the fetch and attach operations for each table and partition.
SELECT
DISTINCT
'alter table '||database||'.'||table||' FETCH PARTITION '''||partition_id||''' FROM '''||zookeeper_path||'''; '
||'alter table '||database||'.'||table||' ATTACH PARTITION '''||partition_id||''';'
FROM system.parts INNER JOIN system.replicas USING (database, table)
WHERE database IN ('db1','db2' ... 'dbn') AND active
You could add an ORDER BY to manually make the list in the order you need, or use ORDER BY rand() to randomize it. You will then need to split the commands between the shards.
44.6 - Remote table function
remote(…) table function
Suitable for moving up to hundreds of gigabytes of data.
With bigger tables recommended approach is to slice the original data by some WHERE condition, ideally - apply the condition on partitioning key, to avoid writing data to many partitions at once.
INSERT INTO staging_table SELECT * FROM remote(...) WHERE date='2021-04-13';
INSERT INTO staging_table SELECT * FROM remote(...) WHERE date='2021-04-12';
INSERT INTO staging_table SELECT * FROM remote(...) WHERE date='2021-04-11';
....
OR
INSERT INTO FUNCTION remote(...) SELECT * FROM staging_table WHERE date='2021-04-11';
....
Q. Can it create a bigger load on the source system?
Yes, it may use disk read & network write bandwidth. But typically write speed is worse than the read speed, so most probably the receiver side will be a bottleneck, and the sender side will not be overloaded.
While of course it should be checked, every case is different.
Q. Can I tune INSERT speed to make it faster?
Yes, by the cost of extra memory usage (on the receiver side).
ClickHouse® tries to form blocks of data in memory and while one of limit: min_insert_block_size_rows or min_insert_block_size_bytes being hit, ClickHouse dump this block on disk. If ClickHouse tries to execute insert in parallel (max_insert_threads > 1), it would form multiple blocks at one time.
So maximum memory usage can be calculated like this: max_insert_threads * first(min_insert_block_size_rows OR min_insert_block_size_bytes)
Default values:
┌─name────────────────────────┬─value─────┐
│ min_insert_block_size_rows │ 1048545 │
│ min_insert_block_size_bytes │ 268427520 │
│ max_insert_threads │ 0 │ <- Values 0 or 1 means that INSERT SELECT is not run in parallel.
└─────────────────────────────┴───────────┘
Tune those settings depending on your table average row size and amount of memory which are safe to occupy by INSERT SELECT query.
Q. I’ve got the error “All connection tries failed”
SELECT count()
FROM remote('server.from.remote.dc:9440', 'default.table', 'admin', 'password')
Received exception from server (version 20.8.11):
Code: 519. DB::Exception: Received from localhost:9000. DB::Exception: All attempts to get table structure failed. Log:
Code: 279, e.displayText() = DB::NetException: All connection tries failed. Log:
Code: 209, e.displayText() = DB::NetException: Timeout: connect timed out: 192.0.2.1:9440 (server.from.remote.dc:9440) (version 20.8.11.17 (official build))
Code: 209, e.displayText() = DB::NetException: Timeout: connect timed out: 192.0.2.1:9440 (server.from.remote.dc:9440) (version 20.8.11.17 (official build))
Code: 209, e.displayText() = DB::NetException: Timeout: connect timed out: 192.0.2.1:9440 (server.from.remote.dc:9440) (version 20.8.11.17 (official build))
- Using remote(…) table function with secure TCP port (default values is 9440). There is remoteSecure() function for that.
- High (>50ms) ping between servers, values for
connect_timeout_with_failover_ms,connect_timeout_with_failover_secure_msneed’s to be adjusted accordingly.
Default values:
┌─name────────────────────────────────────┬─value─┐
│ connect_timeout_with_failover_ms │ 50 │
│ connect_timeout_with_failover_secure_ms │ 100 │
└─────────────────────────────────────────┴───────┘
Example
#!/bin/bash
table='...'
database='bvt'
local='...'
remote='...'
CH="clickhouse-client" # you may add auth here
settings=" max_insert_threads=20,
max_threads=20,
min_insert_block_size_bytes = 536870912,
min_insert_block_size_rows = 16777216,
max_insert_block_size = 16777216,
optimize_on_insert=0";
# need it to create temp table with same structure (suitable for attach)
params=$($CH -h $remote -q "select partition_key,sorting_key,primary_key from system.tables where table='$table' and database = '$database' " -f TSV)
IFS=$'\t' read -r partition_key sorting_key primary_key <<< $params
$CH -h $local \ # get list of source partitions
-q "select distinct partition from system.parts where table='$table' and database = '$database' "
while read -r partition; do
# check that the partition is already copied
if [ `$CH -h $remote -q " select count() from system.parts table='$table' and database = '$database' and partition='$partition'"` -eq 0 ] ; then
$CH -n -h $remote -q "
create temporary table temp as $database.$table engine=MergeTree -- 23.3 required for temporary table
partition by ($partition_key) primary key ($primary_key) order by ($sorting_key);
-- SYSTEM STOP MERGES temp; -- maybe....
set $settings;
insert into temp select * from remote($local,$database.$table) where _partition='$partition'
-- order by ($sorting_key) -- maybe....
;
alter table $database.$table attach partition $partition from temp
"
fi
done
44.7 - Moving ClickHouse to Another Server
When migrating a large, live ClickHouse cluster (multi-terabyte scale) to a new server or cluster, the goal is to minimize downtime while ensuring data consistency. A practical method is to use incremental rsync in multiple passes, combined with ClickHouse’s replication features.
- Prepare the new cluster
- Ensure the new cluster is set up with its own ZooKeeper (or Keeper).
- Configure ClickHouse but keep it stopped initially.
- For clickhouse-operator instances, you can stop all pods by CHI definition:
spec:
stop: "true"
and attach volumes (PVC) to a service pod.
Initial data sync
Run a full recursive sync of the data directory from the old server to the new one:
rsync -ravlW --delete /var/lib/clickhouse/ user@new_host:/var/lib/clickhouse/Explanation of flags:
r: recursive, includes all subdirectories.a: archive mode (preserves symlinks, permissions, timestamps, ownership, devices).v: verbose, shows progress.l: copy symlinks as symlinks.W: copy whole files instead of using rsync’s delta algorithm (faster for large DB files).- –delete: remove files from the destination that don’t exist on the source.
If you plan to run several replicas on a new cluster, rsync data to all of them. To save the performance of production servers, you can copy data to 1 new replica and then use it as a source for others. You can start with a single replica and add more after switching, but it will take more time afterward, as additional replicas need to pull all the data.
Add –bwlimit=100000 to preserve the performance of the production cluster while copying a lot of data.
Consider shards as independent clusters.
Incremental re-syncs
- Repeat the
rsyncstep multiple times while the old cluster is live. - Each subsequent run will copy only changes and reduce the final sync time.
- Repeat the
Restore replication metadata
- Start the new ClickHouse node(s).
- Run
SYSTEM RESTORE REPLICA table_nameto rebuild replication metadata in ZooKeeper.
Test the application
- Point your test environment to the new cluster.
- Validate queries, schema consistency, and application behavior.
Final sync and switchover
- Stop ClickHouse on the old cluster.
- Immediately run a final incremental
rsyncto catch last-minute changes. - Reinitialize ZooKeeper/Keeper database (stop/clear snapshots/start).
- Run
SYSTEM RESTORE REPLICA table_nameto rebuild replication metadata in ZooKeeper again. - Start ClickHouse on the new cluster and switch production traffic.
- add more replicas as needed
NOTES:
- To restore metadata on all cluster nodes by a single command, use
ON CLUSTERmodifier for the RESTORE REPLICA command. - You can build a script to run restore replica commands over all replicated tables by query:
select 'SYSTEM RESTORE REPLICA ' || database || '.' || table || ' ON CLUSTER {cluster} ;'
from system.tables
where engine ilike 'Replicated%'
- If you are using a mount point that differs from /var/lib/clickhouse/data, adjust the rsync command accordingly to point to the correct location. For example, suppose you reconfigure the storage path as follows in /etc/clickhouse-server/config.d/config.xml.
<clickhouse>
<!-- Path to data directory, with trailing slash. -->
<path>/data1/clickhouse/</path>
...
</clickhouse>
You’ll need to use /data1/clickhouse instead of /var/lib/clickhouse in the rsync paths.
ClickHouse Docker container image does not have rsync installed. Add it using apt-get or run sidecar in k8s or run a service pod with volumes attached.
If you running rsync to multiple replicas or planning to use same (Zoo)Keeper ensemble for source and destination ClickHouse servers, you need to remove server uuid file after syncing data with rsync.
rm /var/lib/clickhouse/uuid
Otherwise, it can lead to hard-to-debug replication issues. Replicas will break each other’s sessions with (Zoo)Keeper.
45 - DDLWorker and DDL queue problems
distributed_ddl_queueDDLWorker is a subprocess (thread) of clickhouse-server that executes ON CLUSTER tasks at the node.
When you execute a DDL query with ON CLUSTER mycluster section, the query executor at the current node reads the cluster mycluster definition (remote_servers / system.clusters) and places tasks into Zookeeper znode task_queue/ddl/... for members of the cluster mycluster.
DDLWorker at all ClickHouse® nodes constantly check this task_queue for their tasks, executes them locally, and reports about the results back into task_queue.
The common issue is the different hostnames/IPAddresses in the cluster definition and locally.
So if the initiator node puts tasks for a host named Host1. But the Host1 thinks about own name as localhost or xdgt634678d (internal docker hostname) and never sees tasks for the Host1 because is looking tasks for xdgt634678d. The same with internal VS external IP addresses.
DDLWorker thread crashed
That causes ClickHouse to stop executing ON CLUSTER tasks.
Check that DDLWorker is alive:
ps -eL|grep DDL
18829 18876 ? 00:00:00 DDLWorkerClnr
18829 18879 ? 00:00:00 DDLWorker
ps -ef|grep 18829|grep -v grep
clickho+ 18829 18828 1 Feb09 ? 00:55:00 /usr/bin/clickhouse-server --con...
As you can see there are two threads: DDLWorker and DDLWorkerClnr.
The second thread – DDLWorkerCleaner cleans old tasks from task_queue. You can configure how many recent tasks to store:
config.xml
<yandex>
<distributed_ddl>
<path>/clickhouse/task_queue/ddl</path>
<pool_size>1</pool_size>
<max_tasks_in_queue>1000</max_tasks_in_queue>
<task_max_lifetime>604800</task_max_lifetime>
<cleanup_delay_period>60</cleanup_delay_period>
</distributed_ddl>
</yandex>
Default values:
cleanup_delay_period = 60 seconds – Sets how often to start cleanup to remove outdated data.
task_max_lifetime = 7 * 24 * 60 * 60 (in seconds = week) – Delete task if its age is greater than that.
max_tasks_in_queue = 1000 – How many tasks could be in the queue.
pool_size = 1 - How many ON CLUSTER queries can be run simultaneously.
Too intensive stream of ON CLUSTER command
Generally, it’s a bad design, but you can increase pool_size setting
Stuck DDL tasks in the distributed_ddl_queue
Sometimes DDL tasks
(the ones that use ON CLUSTER) can get stuck in the distributed_ddl_queue because the replicas can overload if multiple DDLs (thousands of CREATE/DROP/ALTER) are executed at the same time. This is very normal in heavy ETL jobs.This can be detected by checking the distributed_ddl_queue table and see if there are tasks that are not moving or are stuck for a long time.
If these DDLs are completed in some replicas but failed in others, the simplest way to solve this is to execute the failed command in the missed replicas without ON CLUSTER. If most of the DDLs failed, then check the number of unfinished records in distributed_ddl_queue on the other nodes, because most probably it will be as high as thousands.
First, backup the distributed_ddl_queue into a table so you will have a snapshot of the table with the states of the tasks. You can do this with the following command:
CREATE TABLE default.system_distributed_ddl_queue AS SELECT * FROM system.distributed_ddl_queue;
After this, we need to check from the backup table which tasks are not finished and execute them manually in the missed replicas, and review the pipeline which do ON CLUSTER command and does not abuse them. There is a new CREATE TEMPORARY TABLE command that can be used to avoid the ON CLUSTER command in some cases, where you need an intermediate table to do some operations and after that you can INSERT INTO the final table or do ALTER TABLE final ATTACH PARTITION FROM TABLE temp and this temp table will be dropped automatically after the session is closed.
45.1 - There are N unfinished hosts (0 of them are currently active).
Sometimes your Distributed DDL queries are being stuck, and not executing on all or subset of nodes, there are a lot of possible reasons for that kind of behavior, so it would take some time and effort to investigate.
Possible reasons
ClickHouse® node can’t recognize itself
SELECT * FROM system.clusters; -- check is_local column, it should have 1 for itself
getent hosts clickhouse.local.net # or other name which should be local
hostname --fqdn
cat /etc/hosts
cat /etc/hostname
Debian / Ubuntu
There is an issue in Debian based images, when hostname being mapped to 127.0.1.1 address which doesn’t literally match network interface and ClickHouse fails to detect this address as local.
https://github.com/ClickHouse/ClickHouse/issues/23504
Previous task is being executed and taking some time
It’s usually some heavy operations like merges, mutations, alter columns, so it make sense to check those tables:
SHOW PROCESSLIST;
SELECT * FROM system.merges;
SELECT * FROM system.mutations;
In that case, you can just wait completion of previous task.
Previous task is stuck because of some error
In that case, the first step is to understand which exact task is stuck and why. There are some queries which can help with that.
-- list of all distributed ddl queries, path can be different in your installation
SELECT * FROM system.zookeeper WHERE path = '/clickhouse/task_queue/ddl/';
-- information about specific task.
SELECT * FROM system.zookeeper WHERE path = '/clickhouse/task_queue/ddl/query-0000001000/';
SELECT * FROM system.zookeeper WHERE path = '/clickhouse/task_queue/ddl/' AND name = 'query-0000001000';
-- 22.3
SELECT * FROM system.zookeeper WHERE path like '/clickhouse/task_queue/ddl/query-0000001000/%'
ORDER BY ctime, path SETTINGS allow_unrestricted_reads_from_keeper='true'
-- 22.6
SELECT path, name, value, ctime, mtime
FROM system.zookeeper WHERE path like '/clickhouse/task_queue/ddl/query-0000001000/%'
ORDER BY ctime, path SETTINGS allow_unrestricted_reads_from_keeper='true'
-- How many nodes executed this task
SELECT name, numChildren as finished_nodes FROM system.zookeeper
WHERE path = '/clickhouse/task_queue/ddl/query-0000001000/' AND name = 'finished';
┌─name─────┬─finished_nodes─┐
│ finished │ 0 │
└──────────┴────────────────┘
-- The nodes that are running the task
SELECT name, value, ctime, mtime FROM system.zookeeper
WHERE path = '/clickhouse/task_queue/ddl/query-0000001000/active/';
-- What was the result for the finished nodes
SELECT name, value, ctime, mtime FROM system.zookeeper
WHERE path = '/clickhouse/task_queue/ddl/query-0000001000/finished/';
-- Latest successfull executed tasks from query_log.
SELECT query FROM system.query_log WHERE query LIKE '%ddl_entry%' AND type = 2 ORDER BY event_time DESC LIMIT 5;
SELECT
FQDN(),
*
FROM clusterAllReplicas('cluster', system.metrics)
WHERE metric LIKE '%MaxDDLEntryID%'
┌─FQDN()───────────────────┬─metric────────┬─value─┬─description───────────────────────────┐
│ chi-ab.svc.cluster.local │ MaxDDLEntryID │ 1468 │ Max processed DDL entry of DDLWorker. │
└──────────────────────────┴───────────────┴───────┴───────────────────────────────────────┘
┌─FQDN()───────────────────┬─metric────────┬─value─┬─description───────────────────────────┐
│ chi-ab.svc.cluster.local │ MaxDDLEntryID │ 1468 │ Max processed DDL entry of DDLWorker. │
└──────────────────────────┴───────────────┴───────┴───────────────────────────────────────┘
┌─FQDN()───────────────────┬─metric────────┬─value─┬─description───────────────────────────┐
│ chi-ab.svc.cluster.local │ MaxDDLEntryID │ 1468 │ Max processed DDL entry of DDLWorker. │
└──────────────────────────┴───────────────┴───────┴───────────────────────────────────────┘
-- Information about task execution from logs.
grep -C 40 "ddl_entry" /var/log/clickhouse-server/clickhouse-server*.log
Issues that can prevent task execution
Obsolete Replicas
Obsolete replicas left in zookeeper.
SELECT database, table, zookeeper_path, replica_path zookeeper FROM system.replicas WHERE total_replicas != active_replicas;
SELECT * FROM system.zookeeper WHERE path = '/clickhouse/cluster/tables/01/database/table/replicas';
SYSTEM DROP REPLICA 'replica_name';
SYSTEM STOP REPLICATION QUEUES;
SYSTEM START REPLICATION QUEUES;
https://clickhouse.tech/docs/en/sql-reference/statements/system/#query_language-system-drop-replica
Tasks manually removed from DDL queue
Task were removed from DDL queue, but left in Replicated*MergeTree table queue.
grep -C 40 "ddl_entry" /var/log/clickhouse-server/clickhouse-server*.log
/var/log/clickhouse-server/clickhouse-server.log:2021.05.04 12:41:28.956888 [ 599 ] {} <Debug> DDLWorker: Processing task query-0000211211 (ALTER TABLE db.table_local ON CLUSTER `all-replicated` DELETE WHERE id = 1)
/var/log/clickhouse-server/clickhouse-server.log:2021.05.04 12:41:29.053555 [ 599 ] {} <Error> DDLWorker: ZooKeeper error: Code: 999, e.displayText() = Coordination::Exception: No node, Stack trace (when copying this message, always include the lines below):
/var/log/clickhouse-server/clickhouse-server.log-
/var/log/clickhouse-server/clickhouse-server.log-0. Coordination::Exception::Exception(std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, Coordination::Error, int) @ 0xfb2f6b3 in /usr/bin/clickhouse
/var/log/clickhouse-server/clickhouse-server.log-1. Coordination::Exception::Exception(Coordination::Error) @ 0xfb2fb56 in /usr/bin/clickhouse
/var/log/clickhouse-server/clickhouse-server.log:2. DB::DDLWorker::createStatusDirs(std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, std::__1::shared_ptr<zkutil::ZooKeeper> const&) @ 0xeb3127a in /usr/bin/clickhouse
/var/log/clickhouse-server/clickhouse-server.log:3. DB::DDLWorker::processTask(DB::DDLTask&) @ 0xeb36c96 in /usr/bin/clickhouse
/var/log/clickhouse-server/clickhouse-server.log:4. DB::DDLWorker::enqueueTask(std::__1::unique_ptr<DB::DDLTask, std::__1::default_delete<DB::DDLTask> >) @ 0xeb35f22 in /usr/bin/clickhouse
/var/log/clickhouse-server/clickhouse-server.log-5. ? @ 0xeb47aed in /usr/bin/clickhouse
/var/log/clickhouse-server/clickhouse-server.log-6. ThreadPoolImpl<ThreadFromGlobalPool>::worker(std::__1::__list_iterator<ThreadFromGlobalPool, void*>) @ 0x8633bcd in /usr/bin/clickhouse
/var/log/clickhouse-server/clickhouse-server.log-7. ThreadFromGlobalPool::ThreadFromGlobalPool<void ThreadPoolImpl<ThreadFromGlobalPool>::scheduleImpl<void>(std::__1::function<void ()>, int, std::__1::optional<unsigned long>)::'lambda1'()>(void&&, void ThreadPoolImpl<ThreadFromGlobalPool>::scheduleImpl<void>(std::__1::function<void ()>, int, std::__1::optional<unsigned long>)::'lambda1'()&&...)::'lambda'()::operator()() @ 0x863612f in /usr/bin/clickhouse
/var/log/clickhouse-server/clickhouse-server.log-8. ThreadPoolImpl<std::__1::thread>::worker(std::__1::__list_iterator<std::__1::thread, void*>) @ 0x8630ffd in /usr/bin/clickhouse
/var/log/clickhouse-server/clickhouse-server.log-9. ? @ 0x8634bb3 in /usr/bin/clickhouse
/var/log/clickhouse-server/clickhouse-server.log-10. start_thread @ 0x9609 in /usr/lib/x86_64-linux-gnu/libpthread-2.31.so
/var/log/clickhouse-server/clickhouse-server.log-11. __clone @ 0x122293 in /usr/lib/x86_64-linux-gnu/libc-2.31.so
/var/log/clickhouse-server/clickhouse-server.log- (version 21.1.8.30 (official build))
/var/log/clickhouse-server/clickhouse-server.log:2021.05.04 12:41:29.053951 [ 599 ] {} <Debug> DDLWorker: Processing task query-0000211211 (ALTER TABLE db.table_local ON CLUSTER `all-replicated` DELETE WHERE id = 1)
Context of this problem is:
- Constant pressure of cheap ON CLUSTER DELETE queries.
- One replica was down for a long amount of time (multiple days).
- Because of pressure on the DDL queue, it purged old records due to the
task_max_lifetimesetting. - When a lagging replica comes up, it’s fail’s execute old queries from DDL queue, because at this point they were purged from it.
Solution:
- Reload/Restore this replica from scratch.
DDL path was changed in Zookeeper without restarting ClickHouse
Changing the DDL queue path in Zookeeper without restarting ClickHouse will make ClickHouse confused. If you need to do this ensure that you restart ClickHouse before submitting additional distributed DDL commands. Here’s an example.
-- Path before change:
SELECT *
FROM system.zookeeper
WHERE path = '/clickhouse/clickhouse101/task_queue'
┌─name─┬─value─┬─path─────────────────────────────────┐
│ ddl │ │ /clickhouse/clickhouse101/task_queue │
└──────┴───────┴──────────────────────────────────────┘
-- Path after change
SELECT *
FROM system.zookeeper
WHERE path = '/clickhouse/clickhouse101/task_queue'
┌─name─┬─value─┬─path─────────────────────────────────┐
│ ddl2 │ │ /clickhouse/clickhouse101/task_queue │
└──────┴───────┴──────────────────────────────────────┘
The reason is that ClickHouse will not “see” this change and will continue to look for tasks in the old path. Altering paths in Zookeeper should be avoided if at all possible. If necessary it must be done very carefully.
46 - Merge Shards
(draft, not tested)
ClickHouse migration plan: merge 11 shards into 1 using clickhouse-backup
Your migration approach is workable with one important pattern:
- restore schema once
- restore local-table data shard by shard into
detached - run
ALTER TABLE ... ATTACH PARTto attach restored parts - recreate or adjust Distributed tables for the new 1-shard topology
This plan assumes:
- all 11 shards use schema-compatible local tables
- all backups are taken from a consistent point in time
- the target cluster is already built as a 1-shard environment
Distributedtables are treated as routing/query objects, not as the physical data source
Relevant references:
clickhouse-backupREADME: https://github.com/Altinity/clickhouse-backup/blob/master/ReadMe.mdclickhouse-backupchangelog: https://github.com/Altinity/clickhouse-backup/blob/master/ChangeLog.md- Replication docs: https://clickhouse.com/docs/engines/table-engines/mergetree-family/replication
- Distributed engine docs: https://clickhouse.com/docs/engines/table-engines/special/distributed
- Detached parts docs: https://clickhouse.com/docs/operations/system-tables/detached_parts
Diagnosis
The safest migration pattern is:
- take one backup per shard
- build the new 1-shard target cluster
- restore schema once from a single shard backup
- restore only local-table data from each shard backup using
--replicated-copy-to-detached - attach detached parts after each shard restore
- recreate or validate
Distributedtables for the new cluster layout - validate row counts, parts, and detached leftovers
I would not restore all 11 shard backups first and attach later. It is safer to process one shard backup at a time:
- restore to detached
- attach parts
- validate
- continue with the next shard
Migration sequence
1) Take backups on all 11 source shards
Use one backup per shard and keep shard identity in the backup name.
Examples:
shard01_20260319_full
shard02_20260319_full
...
shard11_20260319_full
Example commands:
clickhouse-backup create_remote shard01_20260319_full
clickhouse-backup create_remote shard02_20260319_full
clickhouse-backup create_remote shard03_20260319_full
Notes:
- run
clickhouse-backupon the same host or pod as ClickHouse, because it needs filesystem access - keep writes stopped or otherwise guarantee a consistent backup window across all shards
2) Prepare the new single-shard target
Before restoring anything:
- create the new cluster definition
- set correct macros for the new topology
- verify Keeper paths for replicated tables
- verify storage policies and disk layout
For Replicated*MergeTree, Keeper paths must be correct for the new 1-shard layout.
3) Restore schema once
Restore schema from one shard backup only.
Example:
clickhouse-backup restore_remote --schema shard01_20260319_full
You should restore schema only once because the table definitions are expected to be identical across shards.
Practical recommendation:
- restore databases and local tables once
- then recreate
Distributedtables later so they point to the new 1-shard cluster
4) Restore local-table data shard by shard into detached
Use --replicated-copy-to-detached so the restore copies data into detached instead of trying to attach parts automatically.
Example for all local tables in both databases:
clickhouse-backup restore_remote \
--data \
--tables="db1.*_local,db2.*_local" \
--replicated-copy-to-detached \
shard01_20260319_full
Example for a smaller test subset:
clickhouse-backup restore_remote \
--data \
--tables="db1.events_local,db1.sessions_local,db2.fact_local" \
--replicated-copy-to-detached \
shard01_20260319_full
Notes:
- restore local tables only
- do not rely on
Distributedtables for the data merge - process one shard backup at a time
5) Attach detached parts
After each shard restore, inspect system.detached_parts and attach the parts into the target local tables.
Attach a known part:
ALTER TABLE `db1`.`events_local` ATTACH PART '202603_12_12_0';
Generate attach statements for all detached parts in the two databases:
SELECT concat(
'ALTER TABLE `', database, '`.`', table,
'` ATTACH PART ', quoteString(name), ';'
) AS attach_sql
FROM system.detached_parts
WHERE database IN ('db1', 'db2')
AND ifNull(reason, '') = ''
ORDER BY database, table, partition_id, min_block_number, max_block_number, name;
Inventory detached parts before and after attach:
SELECT
database,
table,
reason,
count() AS parts,
formatReadableSize(sum(bytes_on_disk)) AS total_bytes
FROM system.detached_parts
WHERE database IN ('db1', 'db2')
GROUP BY database, table, reason
ORDER BY database, table, reason;
Validate active data after attach:
SELECT
database,
table,
sum(rows) AS rows,
formatReadableSize(sum(bytes_on_disk)) AS total_bytes
FROM system.parts
WHERE active
AND database IN ('db1', 'db2')
GROUP BY database, table
ORDER BY database, table;
6) Recreate Distributed tables for the new 1-shard cluster
After all local-table data is loaded, recreate or adjust Distributed tables so they point to the new cluster layout.
Example:
DROP TABLE IF EXISTS `db1`.`events`;
CREATE TABLE `db1`.`events` AS `db1`.`events_local`
ENGINE = Distributed('cluster_1shard', 'db1', 'events_local', cityHash64(user_id));
This step is important because Distributed tables are query-routing objects, not the physical source of merged shard data.
7) Validation checklist
Before opening writes on the new cluster:
- compare row counts by table
- compare bytes on disk by table
- inspect
system.detached_partsfor leftovers - inspect replication health if tables remain replicated
- validate that all
Distributedtables point to the new cluster definition - run smoke-test queries against both databases
Recommended operating pattern
For your case with two databases and around 50 tables total:
- separate local tables from Distributed tables
- restore schema once
- restore local data shard by shard
- attach parts after each shard
- recreate
Distributedtables last
That is the most predictable way to merge 11 shards into 1 with clickhouse-backup.
Important caveats
- do not restore all shard backups to
detachedfirst and postpone all attaches until the end - do not restore schema 11 times
- verify Keeper paths and macros carefully when moving from 11 shards to 1
- test the full flow on a few representative large tables before running the complete migration
- treat any remaining entries in
system.detached_partsas something to review explicitly
Minimal command examples
Create backup:
clickhouse-backup create_remote shard01_20260319_full
Restore schema once:
clickhouse-backup restore_remote --schema shard01_20260319_full
Restore local-table data to detached:
clickhouse-backup restore_remote \
--data \
--tables="db1.*_local,db2.*_local" \
--replicated-copy-to-detached \
shard01_20260319_full
Attach one detached part:
ALTER TABLE `db1`.`events_local` ATTACH PART '202603_12_12_0';
Generate all attach commands:
SELECT concat(
'ALTER TABLE `', database, '`.`', table,
'` ATTACH PART ', quoteString(name), ';'
) AS attach_sql
FROM system.detached_parts
WHERE database IN ('db1', 'db2')
AND ifNull(reason, '') = ''
ORDER BY database, table, partition_id, min_block_number, max_block_number, name;
Bash script template
This is a production-style skeleton you can adapt.
#!/usr/bin/env bash
set -euo pipefail
CH_CLIENT="${CH_CLIENT:-clickhouse-client --multiquery}"
CH_BACKUP="${CH_BACKUP:-clickhouse-backup}"
# Backups from 11 source shards
BACKUPS=(
shard01_20260319_full
shard02_20260319_full
shard03_20260319_full
shard04_20260319_full
shard05_20260319_full
shard06_20260319_full
shard07_20260319_full
shard08_20260319_full
shard09_20260319_full
shard10_20260319_full
shard11_20260319_full
)
# Databases to migrate
DATABASES=(
db1
db2
)
# Local tables only.
# Keep Distributed tables out of this list.
LOCAL_TABLE_PATTERNS=(
"db1.*_local"
"db2.*_local"
)
join_by_comma() {
local IFS=","
echo "$*"
}
LOCAL_TABLES_CSV="$(join_by_comma "${LOCAL_TABLE_PATTERNS[@]}")"
echo "== Step 1: restore schema once from first shard backup =="
${CH_BACKUP} restore_remote --schema "${BACKUPS[0]}"
echo "== Step 2: process shard backups one by one =="
for backup in "${BACKUPS[@]}"; do
echo "---- restoring data to detached from backup: ${backup}"
${CH_BACKUP} restore_remote \
--data \
--tables="${LOCAL_TABLES_CSV}" \
--replicated-copy-to-detached \
"${backup}"
echo "---- attaching detached parts created by ${backup}"
${CH_CLIENT} --query "
SELECT concat(
'ALTER TABLE `', database, '`.`', table,
'` ATTACH PART ', quoteString(name), ';'
)
FROM system.detached_parts
WHERE database IN ('db1', 'db2')
AND ifNull(reason, '') = ''
ORDER BY database, table, partition_id, min_block_number, max_block_number, name
FORMAT TSVRaw
" | while IFS= read -r stmt; do
echo "${stmt}"
${CH_CLIENT} --query "${stmt}"
done
echo "---- post-attach detached inventory"
${CH_CLIENT} --query "
SELECT
database,
table,
reason,
count() AS parts
FROM system.detached_parts
WHERE database IN ('db1', 'db2')
GROUP BY database, table, reason
ORDER BY database, table, reason
"
done
echo "== Step 3: final validation =="
${CH_CLIENT} --query "
SELECT database, table, sum(rows) AS rows, formatReadableSize(sum(bytes_on_disk)) AS bytes
FROM system.parts
WHERE active
AND database IN ('db1', 'db2')
GROUP BY database, table
ORDER BY database, table
"
echo "Migration load phase completed."
47 - differential backups using clickhouse-backup
differential backups using clickhouse-backup
- Download the latest version of Altinity Backup for ClickHouse®: https://github.com/Altinity/clickhouse-backup/releases
# ubuntu / debian
wget https://github.com/Altinity/clickhouse-backup/releases/download/v2.5.20/clickhouse-backup_2.5.20_amd64.deb
sudo dpkg -i clickhouse-backup_2.5.20_amd64.deb
# centos / redhat / fedora
sudo yum install https://github.com/Altinity/clickhouse-backup/releases/download/v2.5.20/clickhouse-backup-2.5.20-1.x86_64.rpm
# other platforms
wget https://github.com/Altinity/clickhouse-backup/releases/download/v2.5.20/clickhouse-backup.tar.gz
sudo mkdir /etc/clickhouse-backup/
sudo mv clickhouse-backup/config.yml /etc/clickhouse-backup/config.yml.example
sudo mv clickhouse-backup/clickhouse-backup /usr/bin/
rm -rf clickhouse-backup clickhouse-backup.tar.gz
- Create a runner script for the crontab
mkdir /opt/clickhouse-backup-diff/
cat << 'END' > /opt/clickhouse-backup-diff/clickhouse-backup-cron.sh
#!/bin/bash
set +x
command_line_argument=$1
backup_name=$(date +%Y-%M-%d-%H-%M-%S)
echo "Creating local backup '${backup_name}' (full, using hardlinks)..."
clickhouse-backup create "${backup_name}"
if [[ "run_diff" == "${command_line_argument}" && "2" -le "$(clickhouse-backup list local | wc -l)" ]]; then
prev_backup_name="$(clickhouse-backup list local | tail -n 2 | head -n 1 | cut -d " " -f 1)"
echo "Uploading the backup '${backup_name}' as diff from the previous backup ('${prev_backup_name}')"
clickhouse-backup upload --diff-from "${prev_backup_name}" "${backup_name}"
elif [[ "" == "${command_line_argument}" ]]; then
echo "Uploading the backup '${backup_name}, and removing old unneeded backups"
KEEP_BACKUPS_LOCAL=1 KEEP_BACKUPS_REMOTE=1 clickhouse-backup upload "${backup_name}"
fi
END
chmod +x /opt/clickhouse-backup-diff/clickhouse-backup-cron.sh
- Create configuration for clickhouse-backup
# Check the example: /etc/clickhouse-backup/config.yml.example
vim /etc/clickhouse-backup/config.yml
- Edit the crontab
crontab -e
# full backup at 0:00 Monday
0 0 * * 1 clickhouse /opt/clickhouse-backup-diff/clickhouse-backup-cron.sh
# differential backup every hour (except of 00:00) Monday
0 1-23 * * 1 clickhouse /opt/clickhouse-backup-diff/clickhouse-backup-cron.sh run_diff
# differential backup every hour Sunday, Tuesday-Saturday
0 */1 * * 0,2-6 clickhouse /opt/clickhouse-backup-diff/clickhouse-backup-cron.sh run_diff
- Recover the last backup:
last_remote_backup="$(clickhouse-backup list remote | tail -n 1 | cut -d " " -f 1)"
clickhouse-backup download "${last_remote_backup}"
clickhouse-backup restore --rm "${last_remote_backup}"
48 - High CPU usage in ClickHouse®
In general, it is a NORMAL situation for ClickHouse® that while processing a huge dataset it can use a lot of (or all of) the server resources. It is ‘by design’ - just to make the answers faster.
The main directions to reduce the CPU usage is to review the schema / queries to limit the amount of the data which need to be processed, and to plan the resources in a way when single running query will not impact the others.
Any attempts to reduce the CPU usage will end up with slower queries!
How to slow down queries to reduce the CPU usage
If it is acceptable for you - please check the following options for limiting the CPU usage:
setting
max_threads: reducing the number of threads that are allowed to use one request. Fewer threads = more free cores for other requests. By default, it’s allowed to take half of the available CPU cores, adjust only when needed. So if if you have 10 cores thenmax_threads = 10will work about twice faster thanmax_threads=5, but will take 100% or CPU. (max_threads=5 will use half of CPUs so 50%).setting
os_thread_priority: increasing niceness for selected requests. In this case, the operating system, when choosing which of the running processes to allocate processor time, will prefer processes with lower niceness. 0 is the default niceness. The higher the niceness, the lower the priority of the process. The maximum niceness value is 19.
These are custom settings that can be tweaked in several ways:
by specifying them when connecting a client, for example
clickhouse-client --os_thread_priority=19 -q 'SELECT max (number) from numbers (100000000)' echo 'SELECT max(number) from numbers(100000000)' | curl 'http://localhost:8123/?os_thread_priority=19' --data-binary @-via dedicated API / connection parameters in client libraries
using the SQL command SET (works only within the session)
SET os_thread_priority = 19; SELECT max(number) from numbers(100000000)using different profiles of settings for different users. Something like
<?xml version="1.0"?> <yandex> <profiles> <default> ... </default> <lowcpu> <os_thread_priority>19</os_thread_priority> <max_threads>4</max_threads> </lowcpu> </profiles> <!-- Users and ACL. --> <users> <!-- If user name was not specified, 'default' user is used. --> <limited_user> <password>123</password> <networks> <ip>::/0</ip> </networks> <profile>lowcpu</profile> <!-- Quota for user. --> <quota>default</quota> </limited_user> </users> </yandex>
There are also plans to introduce a system of more flexible control over the assignment of resources to different requests.
Also, if these are manually created queries, then you can try to discipline users by adding quotas to them (they can be formulated as “you can read no more than 100GB of data per hour” or “no more than 10 queries”, etc.)
If these are automatically generated queries, it may make sense to check if there is no way to write them in a more efficient way.
49 - Load balancers
In general - one of the simplest option to do load balancing is to implement it on the client side.
I.e. list several endpoints for ClickHouse® connections and add some logic to pick one of the nodes.
Many client libraries support that.
ClickHouse native protocol (port 9000)
Currently there are no protocol-aware proxies for ClickHouse protocol, so the proxy / load balancer can work only on TCP level.
One of the best option for TCP load balancer is haproxy, also nginx can work in that mode.
Haproxy will pick one upstream when connection is established, and after that it will keep it connected to the same server until the client or server will disconnect (or some timeout will happen).
It can’t send different queries coming via a single connection to different servers, as he knows nothing about ClickHouse protocol and doesn’t know when one query ends and another start, it just sees the binary stream.
So for native protocol, there are only 3 possibilities:
- close connection after each query client-side
- close connection after each query server-side (currently there is only one setting for that - idle_connection_timeout=0, which is not exact what you need, but similar).
- use a ClickHouse server with Distributed table as a proxy.
HTTP protocol (port 8123)
There are many more options and you can use haproxy / nginx / chproxy, etc. chproxy give some extra ClickHouse-specific features, you can find a list of them at https://chproxy.org
50 - memory configuration settings
max_memory_usage. Single query memory usage
max_memory_usage - the maximum amount of memory allowed for a single query to take. By default, it’s 10Gb. The default value is good, don’t adjust it in advance.
There are scenarios when you need to relax the limit for particular queries (if you hit ‘Memory limit (for query) exceeded’), or use a lower limit if you need to discipline the users or increase the number of simultaneous queries.
Server memory usage
Server memory usage = constant memory footprint (used by different caches, dictionaries, etc) + sum of memory temporary used by running queries (a theoretical limit is a number of simultaneous queries multiplied by max_memory_usage).
Since 20.4 you can set up a global limit using the max_server_memory_usage setting. If something will hit that limit you will see ‘Memory limit (total) exceeded’ in random places.
By default it 90% of the physical RAM of the server. https://clickhouse.tech/docs/en/operations/server-configuration-parameters/settings/#max_server_memory_usage https://github.com/ClickHouse/ClickHouse/blob/e5b96bd93b53d2c1130a249769be1049141ef386/programs/server/config.xml#L239-L250
You can decrease that in some scenarios (like you need to leave more free RAM for page cache or to some other software).
Limits?
select metric, formatReadableSize(value) from system.asynchronous_metrics where metric ilike '%MemoryTotal%'
union all
select name, formatReadableSize(toUInt64(value)) from system.server_settings where name='max_server_memory_usage'
FORMAT PrettyCompactMonoBlock
How to check what is using my RAM?
altinity-kb-who-ate-my-memory.md
Mark cache
https://github.com/ClickHouse/clickhouse-presentations/blob/master/meetup39/mark-cache.pdf
51 - Memory Overcommiter
max_memory_usage per queryMemory Overcommiter
From version 22.2+ ClickHouse® was updated with enhanced Memory overcommit capabilities
. In the past, queries were constrained by the max_memory_usage setting, imposing a rigid limitation. Users had the option to increase this limit, but it came at the potential expense of impacting other users during a single query. With the introduction of Memory overcommit, more memory-intensive queries can now execute, granted there are ample resources available. When the server reaches its maximum memory limit
, ClickHouse identifies the most overcommitted queries and attempts to terminate them. It’s important to note that the terminated query might not be the one causing the condition. If it’s not, the query will undergo a waiting period to allow the termination of the high-memory query before resuming its execution. This setup ensures that low-memory queries always have the opportunity to run, while more resource-intensive queries can execute during server idle times when resources are abundant. Users have the flexibility to fine-tune this behavior at both the server and user levels.
If the memory overcommitter is not being used you’ll get something like this:
Received exception from server (version 22.8.20):
Code: 241. DB::Exception: Received from altinity.cloud:9440. DB::Exception: Received from chi-replica1-2-0:9000. DB::Exception: Memory limit (for query) exceeded: would use 5.00 GiB (attempt to allocate chunk of 4196736 bytes), maximum: 5.00 GiB. OvercommitTracker decision: Memory overcommit isn't used. OvercommitTracker isn't set.: (avg_value_size_hint = 0, avg_chars_size = 1, limit = 8192): while receiving packet from chi-replica1-1-0:9000: While executing Remote. (MEMORY_LIMIT_EXCEEDED)
So to enable Memory Overcommit you need to get rid of the max_memory_usage and max_memory_usage_for_user (set them to 0) and configure overcommit specific settings (usually defaults are ok, so read carefully the documentation)
memory_overcommit_ratio_denominator: It represents soft memory limit on the user level. This value is used to compute query overcommit ratio.memory_overcommit_ratio_denominator_for_user: It represents soft memory limit on the global level. This value is used to compute query overcommit ratio.memory_usage_overcommit_max_wait_microseconds: Maximum time thread will wait for memory to be freed in the case of memory overcommit. If timeout is reached and memory is not freed, exception is thrown
Please check https://clickhouse.com/docs/en/operations/settings/memory-overcommit
Also you will check/need to configure global memory server setting. These are by default:
<clickhouse>
<!-- when max_server_memory_usage is set to non-zero, max_server_memory_usage_to_ram_ratio is ignored-->
<max_server_memory_usage>0</max_server_memory_usage>
<max_server_memory_usage_to_ram_ratio>0.8</max_server_memory_usage_to_ram_ratio>
</clickhouse>
With these set, now if you execute some queries with bigger memory needs than your max_server_memory_usage you’ll get something like this:
Received exception from server (version 22.8.20):
Code: 241. DB::Exception: Received from altinity.cloud:9440. DB::Exception: Received from chi-test1-2-0:9000. DB::Exception: Memory limit (total) exceeded: would use 12.60 GiB (attempt to allocate chunk of 4280448 bytes), maximum: 12.60 GiB. OvercommitTracker decision: Query was selected to stop by OvercommitTracker.: while receiving packet from chi-replica1-2-0:9000: While executing Remote. (MEMORY_LIMIT_EXCEEDED)
This will allow you to know that the Overcommit memory tracker is set and working.
Also to note that maybe you don’t need the Memory Overcommit system because with max_memory_usage per query you’re ok.
The good thing about memory overcommit is that you let ClickHouse handle the memory limitations instead of doing it manually, but there may be some scenarios where you don’t want to use it and using max_memory_usage or max_memory_usage_for_user is a better fit. For example, if your workload has a lot of small/medium queries that are not memory intensive and you need to run few memory intensive queries for some users with a fixed memory limit. This is a common scenario for dbt or other ETL tools that usually run big memory intensive queries.
52 - Moving a table to another device
Suppose we mount a new device at path /mnt/disk_1 and want to move table_4 to it.
- Create directory on new device for ClickHouse® data. /in shell
mkdir /mnt/disk_1/clickhouse - Change ownership of created directory to ClickHouse user. /in shell
chown -R clickhouse:clickhouse /mnt/disk_1/clickhouse - Create a special storage policy which should include both disks: old and new. /in shell
nano /etc/clickhouse-server/config.d/storage.xml
###################/etc/clickhouse-server/config.d/storage.xml###########################
<yandex>
<storage_configuration>
<disks>
<!--
default disk is special, it always
exists even if not explicitly
configured here, but you can't change
it's path here (you should use <path>
on top level config instead)
-->
<default>
<!--
You can reserve some amount of free space
on any disk (including default) by adding
keep_free_space_bytes tag
-->
</default>
<disk_1> <!-- disk name -->
<path>/mnt/disk_1/clickhouse/</path>
</disk_1>
</disks>
<policies>
<move_from_default_to_disk_1> <!-- name for new storage policy -->
<volumes>
<default>
<disk>default</disk>
<max_data_part_size_bytes>10000000</max_data_part_size_bytes>
</default>
<disk_1_vol> <!-- name of volume -->
<!--
we have only one disk in that volume
and we reference here the name of disk
as configured above in <disks> section
-->
<disk>disk_1</disk>
</disk_1_vol>
</volumes>
<move_factor>0.99</move_factor>
</move_from_default_to_disk_1>
</policies>
</storage_configuration>
</yandex>
#########################################################################################
- Update storage_policy setting of tables to new policy.
ALTER TABLE table_4 MODIFY SETTING storage_policy='move_from_default_to_disk_1';
- Wait till all parts of tables change their disk_name to new disk.
SELECT name,disk_name, path from system.parts WHERE table='table_4' and active;
SELECT disk_name, path, sum(rows), sum(bytes_on_disk), uniq(partition), count() FROM system.parts WHERE table='table_4' and active GROUP BY disk_name, path ORDER BY disk_name, path;
- Remove ‘default’ disk from new storage policy. In server shell:
nano /etc/clickhouse-server/config.d/storage.xml
###################/etc/clickhouse-server/config.d/storage.xml###########################
<yandex>
<storage_configuration>
<disks>
<!--
default disk is special, it always
exists even if not explicitly
configured here, but you can't change
it's path here (you should use <path>
on top level config instead)
-->
<default>
<!--
You can reserve some amount of free space
on any disk (including default) by adding
keep_free_space_bytes tag
-->
</default>
<disk_1> <!-- disk name -->
<path>/mnt/disk_1/clickhouse/</path>
</disk_1>
</disks>
<policies>
<move_from_default_to_disk_1> <!-- name for new storage policy -->
<volumes>
<disk_1_vol> <!-- name of volume -->
<!--
we have only one disk in that volume
and we reference here the name of disk
as configured above in <disks> section
-->
<disk>disk_1</disk>
</disk_1_vol>
</volumes>
<move_factor>0.99</move_factor>
</move_from_default_to_disk_1>
</policies>
</storage_configuration>
</yandex>
#########################################################################################
ClickHouse wouldn’t auto reload config, because we removed some disks from storage policy, so we need to restart it by hand.
- Restart ClickHouse server.
- Make sure that storage policy uses the right disks.
SELECT * FROM system.storage_policies WHERE policy_name='move_from_default_to_disk_1';
53 - MultiDisk (JBOD) Balancing
ClickHouse provides two options to balance an insert across disks in a volume with more than one disk: round_robin and least_used .
Round Robin (Default):
ClickHouse selects the next disk in a round robin manner to write a part.
This is the default setting and is most effective when parts created on insert are roughly the same size.
Drawbacks: may lead to disk skew
Least Used:
ClickHouse selects the disk with the most available space and writes to that disk.
Changing to least_used when even disk space consumption is desirable or when you have a JBOD volume with differing disk sizes. To prevent hot-spots, it is best to set this policy on a fresh volume or on a volume that has already been (re)balanced.
Drawbacks: may lead to hot-spots
Configurations
Configurations that can affect disk selected:
- storage policy volume configuration:
least_used_ttl_ms. Only applies toleast_usedpolicy, 60s default. - disk setting:
keep_free_space_bytes,keep_free_space_ratio
Configuration to assist rebalancing:
- The MergeTree setting
min_bytes_to_rebalance_partition_over_jboddoes not control where data is written during inserts. Instead, it governs how parts are redistributed across disks within the same volume during merge operations.
Note: setting
min_bytes_to_rebalance_partition_over_jboddoes not guarantee balanced partitions and balanced disk usage.
Example of least_used policy:
<clickhouse>
<storage_configuration>
<disks>
<default>
<path>/var/lib/clickhouse/</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk1>
<disk1>
<path>/mnt/disk1/</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk1>
<disk2>
<path>/mnt/disk2/</path>
<keep_free_space_bytes>10737418240</keep_free_space_bytes>
</disk2>
</disks>
<policies>
<hot>
<volumes>
<default>
<disk>disk1</disk>
<disk>disk2</disk>
<load_balancing>least_used</load_balancing>
<least_used_ttl_ms>60000</least_used_ttl_ms> <!-- 60s -->
</default>
</volumes>
</hot>
</policies>
</storage_configuration>
</clickhouse>
Manual Rebalancing Parts over JBOD Disks
Following query will select large parts in target_tables and target_databases that can be candidates to move to another disk. Disk chosen should comply with the following requirements:
- Should only select valid moves for the same storage_policy used by that table
- storage_policy must be JBODs type
- moves to other disks in the same volume
- select a different disk, i.e not the same disk as the one that part is in
- select the disk to move the part to by order of largest free_space on that disk
Set target_tables and target_databases based on requirements.
WITH
'%' AS target_tables,
'%' AS target_databases
SELECT sub.q FROM
(
SELECT
'ALTER TABLE ' || parts.database || '.' || parts.`table` || ' MOVE PART \'' || parts.name ||'\' TO DISK \'' || other_disk_candidate || '\';' as q,
parts.database as db,
parts.`table` as t,
parts.name as part_name,
parts.disk_name as part_disk_name,
parts.bytes_on_disk AS part_bytes_on_disk,
sp.storage_policy as part_storage_policy,
arrayJoin(arrayRemove(v.disks, parts.disk_name)) AS other_disk_candidate,
candidate_disks.free_space AS candidate_disk_free_space
FROM system.parts AS parts
INNER JOIN ( SELECT database, `table`, storage_policy FROM system.tables where (name LIKE target_tables) AND (database LIKE target_databases) group by 1, 2, 3 ) AS sp ON sp.`table` = parts.`table` AND sp.database = parts.database
INNER JOIN ( SELECT policy_name, volume_name, disks AS disks FROM system.storage_policies WHERE volume_type = 0 ) AS v ON sp.storage_policy = v.policy_name
INNER JOIN ( SELECT name, free_space FROM system.disks ORDER BY free_space DESC ) AS candidate_disks ON candidate_disks.name = other_disk_candidate
WHERE parts.active = 1
AND (parts.bytes_on_disk >= 10737418240) --10GB prioritize larger parts
AND (parts.`table` LIKE target_tables)
AND (parts.database LIKE target_databases)
AND candidate_disks.free_space > parts.bytes_on_disk*2 -- 2x buffer
ORDER BY parts.bytes_on_disk DESC, candidate_disk_free_space DESC
LIMIT 1 BY db, t, part_name
) as sub
FORMAT TSVRaw
54 - Object consistency in a cluster
List of missing tables
WITH (
SELECT groupArray(FQDN()) FROM clusterAllReplicas('{cluster}',system,one)
) AS hosts
SELECT database,
table,
arrayFilter( i-> NOT has(groupArray(host),i), hosts) miss_table
FROM (
SELECT FQDN() host, database, name table
FROM clusterAllReplicas('{cluster}',system,tables)
WHERE engine NOT IN ('Log','Memory','TinyLog')
)
GROUP BY database, table
HAVING miss_table <> []
SETTINGS skip_unavailable_shards=1;
┌─database─┬─table─┬─miss_table────────────────┐
│ default │ test │ ['host366.mynetwork.net'] │
└──────────┴───────┴───────────────────────────┘
List of inconsistent tables
SELECT database, name, engine, uniqExact(create_table_query) AS ddl
FROM clusterAllReplicas('{cluster}',system.tables)
GROUP BY database, name, engine HAVING ddl > 1
List of inconsistent columns
WITH (
SELECT groupArray(FQDN()) FROM clusterAllReplicas('{cluster}',system,one)
) AS hosts
SELECT database,
table,
column,
arrayStringConcat(arrayMap( i -> i.2 ||': '|| i.1,
(groupArray( (type,host) ) AS g)),', ') diff
FROM (
SELECT FQDN() host, database, table, name column, type
FROM clusterAllReplicas('{cluster}',system,columns)
)
GROUP BY database, table, column
HAVING length(arrayDistinct(g.1)) > 1 OR length(g.1) <> length(hosts)
SETTINGS skip_unavailable_shards=1;
┌─database─┬─table───┬─column────┬─diff────────────────────────────────┐
│ default │ z │ A │ ch-host22: Int64, ch-host21: String │
└──────────┴─────────┴───────────┴─────────────────────────────────────┘
List of inconsistent dictionaries
WITH (
SELECT groupArray(FQDN()) FROM clusterAllReplicas('{cluster}',system,one)
) AS hosts
SELECT database,
dictionary,
arrayFilter( i-> NOT has(groupArray(host),i), hosts) miss_dict,
arrayReduce('min', (groupArray((element_count, host)) AS ec).1) min,
arrayReduce('max', (groupArray((element_count, host)) AS ec).1) max
FROM (
SELECT FQDN() host, database, name dictionary, element_count
FROM clusterAllReplicas('{cluster}',system,dictionaries)
)
GROUP BY database, dictionary
HAVING miss_dict <> [] or min <> max
SETTINGS skip_unavailable_shards=1;
;
55 - Production Cluster Configuration Guide
Moving from a single ClickHouse® server to a clustered format provides several benefits:
- Replication guarantees data integrity.
- Provides redundancy.
- Failover by being able to restart half of the nodes without encountering downtime.
Moving from an unsharded ClickHouse environment to a sharded cluster requires redesign of schema and queries. Starting with a sharded cluster from the beginning makes it easier in the future to scale the cluster up.
Setting up a ClickHouse cluster for a production environment requires the following stages:
- Hardware Requirements
- Network Configuration
- Create Host Names
- Monitoring Considerations
- Configuration Steps
- Setting Up Backups
- Staging Plans
- Upgrading The Cluster
55.1 - Backups
ClickHouse® is currently at the design stage of creating some universal backup solution. Some custom backup strategies are:
- Each shard is backed up separately.
- FREEZE the table/partition. For more information, see Alter Freeze Partition
.
- This creates hard links in shadow subdirectory.
- rsync that directory to a backup location, then remove that subfolder from shadow.
- Cloud users are recommended to use Rclone .
- Always add the full contents of the metadata subfolder that contains the current DB schema and ClickHouse configs to your backup.
- For a second replica, it’s enough to copy metadata and configuration.
- Data in ClickHouse is already compressed with lz4, backup can be compressed bit better, but avoid using cpu-heavy compression algorithms like gzip, use something like zstd instead.
The tool automating that process: Altinity Backup for ClickHouse .
55.2 - Cluster Configuration FAQ
ClickHouse® does not start, some other unexpected behavior happening
Check ClickHouse logs, they are your friends:
tail -n 1000 /var/log/clickhouse-server/clickhouse-server.err.log | less tail -n 10000 /var/log/clickhouse-server/clickhouse-server.log | less
How Do I Restrict Memory Usage?
See our knowledge base article and official documentation for more information.
ClickHouse died during big query execution
Misconfigured ClickHouse can try to allocate more RAM than is available on the system.
In that case an OS component called oomkiller can kill the ClickHouse process.
That event leaves traces inside system logs (can be checked by running dmesg command).
How Do I make huge ‘Group By’ queries use less RAM?
Enable on disk GROUP BY (it is slower, so is disabled by default)
Set max_bytes_before_external_group_by to a value about 70-80% of your max_memory_usage value.
Data returned in chunks by clickhouse-client
See altinity-kb-clickhouse-client
I Can’t Connect From Other Hosts. What do I do?
Check the
55.3 - Cluster Configuration Process
So you set up 3 nodes with zookeeper (zookeeper1, zookeeper2, zookeeper3 - How to install zookeeper? ), and and 4 nodes with ClickHouse® (clickhouse-sh1r1,clickhouse-sh1r2,clickhouse-sh2r1,clickhouse-sh2r2 - how to install ClickHouse? ). Now we need to make them work together.
Use ansible/puppet/salt or other systems to control the servers’ configurations.
- Configure ClickHouse access to Zookeeper by adding the file zookeeper.xml in /etc/clickhouse-server/config.d/ folder. This file must be placed on all ClickHouse servers.
<yandex>
<zookeeper>
<node>
<host>zookeeper1</host>
<port>2181</port>
</node>
<node>
<host>zookeeper2</host>
<port>2181</port>
</node>
<node>
<host>zookeeper3</host>
<port>2181</port>
</node>
</zookeeper>
</yandex>
- On each server put the file macros.xml in
/etc/clickhouse-server/config.d/folder.
<yandex>
<!--
That macros are defined per server,
and they can be used in DDL, to make the DB schema cluster/server neutral
-->
<macros>
<cluster>prod_cluster</cluster>
<shard>01</shard>
<replica>clickhouse-sh1r1</replica> <!-- better - use the same as hostname -->
</macros>
</yandex>
- On each server place the file cluster.xml in /etc/clickhouse-server/config.d/ folder. Before 20.10 ClickHouse will use default user to connect to other nodes (configurable, other users can be used), since 20.10 we recommend to use passwordless intercluster authentication based on common secret (HMAC auth)
<yandex>
<remote_servers>
<prod_cluster> <!-- you need to give a some name for a cluster -->
<!--
<secret>some_random_string, same on all cluster nodes, keep it safe</secret>
-->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>clickhouse-sh1r1</host>
<port>9000</port>
</replica>
<replica>
<host>clickhouse-sh1r2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>clickhouse-sh2r1</host>
<port>9000</port>
</replica>
<replica>
<host>clickhouse-sh2r2</host>
<port>9000</port>
</replica>
</shard>
</prod_cluster>
</remote_servers>
</yandex>
- A good practice is to create 2 additional cluster configurations similar to prod_cluster above with the following distinction: but listing all nodes of single shard (all are replicas) and as nodes of 6 different shards (no replicas)
- all-replicated: All nodes are listed as replicas in a single shard.
- all-sharded: All nodes are listed as separate shards with no replicas.
Once this is complete, other queries that span nodes can be performed. For example:
CREATE TABLE test_table_local ON CLUSTER '{cluster}'
(
id UInt8
)
Engine=ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}')
ORDER BY (id);
That will create a table on all servers in the cluster. You can insert data into this table and it will be replicated automatically to the other shards.To store the data or read the data from all shards at the same time, create a Distributed table that links to the replicatedMergeTree table.
CREATE TABLE test_table ON CLUSTER '{cluster}'
Engine=Distributed('{cluster}', 'default', '
Hardening ClickHouse Security
See https://docs.altinity.com/operationsguide/security/
Additional Settings
See altinity-kb-settings-to-adjust
Users
Disable or add password for the default users default and readonly if your server is accessible from non-trusted networks.
If you add password to the default user, you will need to adjust cluster configuration, since the other servers need to know the default user’s should know the default user’s to connect to each other.
If you’re inside a trusted network, you can leave default user set to nothing to allow the ClickHouse nodes to communicate with each other.
Engines & ClickHouse building blocks
For general explanations of roles of different engines - check the post Distributed vs Shard vs Replicated ahhh, help me!!! .
Zookeeper Paths
Use conventions for zookeeper paths. For example, use:
ReplicatedMergeTree(’/clickhouse/{cluster}/tables/{shard}/table_name’, ‘{replica}’)
for:
SELECT * FROM system.zookeeper WHERE path=’/ …';
Configuration Best Practices
Attribution Modified by a post [on GitHub by Mikhail Filimonov](https://github.com/ClickHouse/ClickHouse/issues/3607#issuecomment-440235298). |
|---|
The following are recommended Best Practices when it comes to setting up a ClickHouse Cluster with Zookeeper:
- Don’t edit/overwrite default configuration files. Sometimes a newer version of ClickHouse introduces some new settings or changes the defaults in config.xml and users.xml.
- Set configurations via the extra files in conf.d directory. For example, to overwrite the interface save the file config.d/listen.xml, with the following:
<?xml version="1.0"?>
<yandex>
<listen_host replace="replace">::</listen_host>
</yandex>
- The same is true for users. For example, change the default profile by putting the file in users.d/profile_default.xml:
<?xml version="1.0"?>
<yandex>
<profiles>
<default replace="replace">
<max_memory_usage>15000000000</max_memory_usage>
<max_bytes_before_external_group_by>12000000000</max_bytes_before_external_group_by>
<max_bytes_before_external_sort>12000000000</max_bytes_before_external_sort>
<distributed_aggregation_memory_efficient>1</distributed_aggregation_memory_efficient>
<use_uncompressed_cache>0</use_uncompressed_cache>
<load_balancing>random</load_balancing>
<log_queries>1</log_queries>
<max_execution_time>600</max_execution_time>
</default>
</profiles>
</yandex>
- Or you can create a user by putting a file users.d/user_xxx.xml (since 20.5 you can also use CREATE USER)
<?xml version="1.0"?>
<yandex>
<users>
<xxx>
<!-- PASSWORD=$(base64 < /dev/urandom | head -c8); echo "$PASSWORD"; echo -n "$PASSWORD" | sha256sum | tr -d '-' -->
<password_sha256_hex>...</password_sha256_hex>
<networks incl="networks" />
<profile>readonly</profile>
<quota>default</quota>
<allow_databases incl="allowed_databases" />
</xxx>
</users>
</yandex>
- Some parts of configuration will contain repeated elements (like allowed ips for all the users). To avoid repeating that - use substitutions file. By default its /etc/metrika.xml, but you can change it for example to /etc/clickhouse-server/substitutions.xml with the <include_from> section of the main config. Put the repeated parts into substitutions file, like this:
<?xml version="1.0"?>
<yandex>
<networks>
<ip>::1</ip>
<ip>127.0.0.1</ip>
<ip>10.42.0.0/16</ip>
<ip>192.168.0.0/24</ip>
</networks>
</yandex>
These files can be common for all the servers inside the cluster or can be individualized per server. If you choose to use one substitutions file per cluster, not per node, you will also need to generate the file with macros, if macros are used.
This way you have full flexibility; you’re not limited to the settings described in the template. You can change any settings per server or data center just by assigning files with some settings to that server or server group. It becomes easy to navigate, edit, and assign files.
Other Configuration Recommendations
Other configurations that should be evaluated:
in config.xml: Determines which IP addresses and ports the ClickHouse servers listen for incoming communications. - <max_memory_..> and <max_bytes_before_external_…> in users.xml. These are part of the profile
. - <max_execution_time>
- <log_queries>
The following extra debug logs should be considered:
- part_log
- text_log
Understanding The Configuration
ClickHouse configuration stores most of its information in two files:
- config.xml: Stores Server configuration parameters
. They are server wide, some are hierarchical , and most of them can’t be changed in runtime. The list of settings to apply without a restart changes from version to version. Some settings can be verified using system tables, for example:
- macros (system.macros)
- remote_servers (system.clusters)
- users.xml: Configure users, and user level / session level settings
.
- Each user can change these during their session by:
- Using parameter in http query
- By using parameter for clickhouse-client
- Sending query like set allow_experimental_data_skipping_indices=1.
- Those settings and their current values are visible in system.settings. You can make some settings global by editing default profile in users.xml, which does not need restart.
- You can forbid users to change their settings by using readonly=2 for that user, or using setting constraints .
- Changes in users.xml are applied w/o restart.
- Each user can change these during their session by:
For both config.xml and users.xml, it’s preferable to put adjustments in the config.d and users.d subfolders instead of editing config.xml and users.xml directly.
You can check if the config file was reread by checking /var/lib/clickhouse/preprocessed_configs/ folder.
55.4 - Hardware Requirements
ClickHouse®
ClickHouse will use all available hardware to maximize performance. So the more hardware - the better. As of this publication, the hardware requirements are:
- Minimum Hardware: 4-core CPU with support of SSE4.2, 16 Gb RAM, 1Tb HDD.
- Recommended for development and staging environments.
- SSE4.2 is required, and going below 4 Gb of RAM is not recommended.
- Recommended Hardware: >=16-cores, >=64Gb RAM, HDD-raid or SSD.
- For processing up to hundreds of millions / billions of rows.
For clouds: disk throughput is the more important factor compared to IOPS. Be aware of burst / baseline disk speed difference.
See also: https://benchmark.clickhouse.com/hardware/
Zookeeper
Zookeeper requires separate servers from those used for ClickHouse. Zookeeper has poor performance when installed on the same node as ClickHouse.
Hardware Requirements for Zookeeper:
- Fast disk speed (ideally NVMe, 128Gb should be enough).
- Any modern CPU (one core, better 2)
- 4Gb of RAM
For clouds - be careful with burstable network disks (like gp2 on aws): you may need up to 1000 IOPs on the disk for on a long run, so gp3 with 3000 IOPs baseline is a better choice.
The number of Zookeeper instances depends on the environment:
- Production: 3 is an optimal number of zookeeper instances.
- Development and Staging: 1 zookeeper instance is sufficient.
See also:
- https://docs.altinity.com/operationsguide/clickhouse-zookeeper/
- altinity-kb-proper-setup
- zookeeper-monitoring
ClickHouse Hardware Configuration
Configure the servers according to those recommendations on the ClickHouse Usage Recommendations .
Test Your Hardware
Be sure to test the following:
- RAM speed.
- Network speed.
- Storage speed.
It’s better to find any performance issues before installing ClickHouse.
55.5 - Network Configuration
Networking And Server Room Planning
The network used for your ClickHouse® cluster should be a fast network, ideally 10 Gbit or more. ClickHouse nodes generate a lot of traffic to exchange the data between nodes (port 9009 for replication, and 9000 for distributed queries). Zookeeper traffic in normal circumstances is moderate, but in some special cases can also be very significant.
For the zookeeper low latency is more important than bandwidth.
Keep the replicas isolated on the hardware level. This allows for cluster failover from possible outages.
- For Physical Environments: Avoid placing 2 ClickHouse replicas on the same server rack. Ideally, they should be on isolated network switches and an isolated power supply.
- For Clouds Environments: Use different availability zones between the ClickHouse replicas when possible (but be aware of the interzone traffic costs)
These considerations are the same as the Zookeeper nodes.
For example:
| Rack | Server | Server | Server | Server |
|---|---|---|---|---|
| Rack 1 | CH_SHARD1_R1 | CH_SHARD2_R1 | CH_SHARD3_R1 | ZOO_1 |
| Rack 2 | CH_SHARD1_R2 | CH_SHARD2_R2 | CH_SHARD3_R2 | ZOO_2 |
| Rack 3 | ZOO3 |
Network Ports And Firewall
ClickHouse listens the following ports:
- 9000: clickhouse-client, native clients, other clickhouse-servers connect to here.
- 8123: HTTP clients
- 9009: Other replicas will connect here to download data.
For more information, see CLICKHOUSE NETWORKING, PART 1 .
Zookeeper listens the following ports:
- 2181: Client connections.
- 2888: Inter-ensemble connections.
- 3888: Leader election.
Outbound traffic from ClickHouse connects to the following ports:
- ZooKeeper: On port 2181.
- Other CH nodes in the cluster: On port 9000 and 9009.
- Dictionary sources: Depending on what was configured such as HTTP, MySQL, Mongo, etc.
- Kafka or Hadoop: If those integrations were enabled.
SSL
For non-trusted networks enable SSL/HTTPS. If acceptable, it is better to keep interserver communications unencrypted for performance reasons.
Naming Schema
The best time to start creating a naming schema for the servers is before they’re created and configured.
There are a few features based on good server naming in ClickHouse:
- clickhouse-client prompts: Allows a different prompt for clickhouse-client per server hostname.
- Nearest hostname load balancing: For more information, see Nearest Hostname .
A good option is to use the following:
{datacenter}-{serverroom}-{rack identifier}-{clickhouse cluster identifier}-{shard number or server number}.
Other examples:
- rxv-olap-ch-master-sh01-r01:
- rxv - location (rack#15)
- olap - product name
- ch = clickhouse
- master = stage
- sh01 = shard 1
- r01 = replica 1
- hetnzerde1-ch-prod-01.local:
- hetnzerde1 - location (also replica id)
- ch = clickhouse
- prod = stage
- 01 - server number / shard number in that DC
- sh01.ch-front.dev.aws-east1a.example.com:
- sh01 - shard 01
- ch-front - cluster name
- dev = stage
- aws = cloud provider
- east1a = region and availability zone
Host Name References
- What are the best practices for domain names (dev, staging, production)?
- 9 Best Practices and Examples for Working with Kubernetes Labels
- Thoughts On Hostname Nomenclature
Additional Hostname Tips
- Hostnames configured on the server should not change. If you do need to change the host name, one reference to use is How to Change Hostname on Ubuntu 18.04 .
- The server should be accessible to other servers in the cluster via it’s hostname. Otherwise you will need to configure interserver_hostname in your config.
- Ensure that
hostname --fqdnandgetent hosts $(hostname --fqdn)return the correct name and ip.
56 - System tables ate my disk
Note 1: System database stores virtual tables (parts, tables, columns, etc.) and *_log tables.
Virtual tables do not persist on disk. They reflect ClickHouse® memory (c++ structures). They cannot be changed or removed.
Log tables are named with postfix *_log and have the MergeTree engine . ClickHouse does not use information stored in these tables, this data is for you only.
You can drop / rename / truncate *_log tables at any time. ClickHouse will recreate them in about 7 seconds (flush period).
Note 2: Log tables with numeric postfixes (_1 / 2 / 3 …)
query_log_1 query_thread_log_3are results of ClickHouse upgrades (or other changes of schemas of these tables). When a new version of ClickHouse starts and discovers that a system log table’s schema is incompatible with a new schema, then ClickHouse renames the old *_log table to the name with the prefix and creates a table with the new schema. You can drop such tables if you don’t need such historic data.
You can disable all / any of them
Do not create log tables at all (a restart is needed for these changes to take effect).
$ cat /etc/clickhouse-server/config.d/z_log_disable.xml
<?xml version="1.0"?>
<clickhouse>
<asynchronous_metric_log remove="1"/>
<asynchronous_insert_log remove="1"/>
<backup_log remove="1"/>
<error_log remove="1"/>
<metric_log remove="1"/>
<query_metric_log remove="1"/>
<query_thread_log remove="1" />
<query_log remove="1" />
<query_views_log remove="1" />
<part_log remove="1"/>
<session_log remove="1"/>
<text_log remove="1" />
<trace_log remove="1"/>
<crash_log remove="1"/>
<opentelemetry_span_log remove="1"/>
<zookeeper_log remove="1"/>
<processors_profile_log remove="1"/>
<latency_log remove="1"/>
<background_schedule_pool_log remove="1"/>
<aggregated_zookeeper_log remove="1"/>
<zookeeper_connection_log remove="1"/>
</clickhouse>
Hint: z_log_disable.xml is named with z_ in the beginning, it means this config will be applied the last and will override all other config files with these sections (config are applied in alphabetical order).
We do not recommend removing query_log as it has very useful information for debugging, and logging can be easily turned off without a restart through user profiles:
$ cat /etc/clickhouse-server/users.d/z_log_queries.xml
<clickhouse>
<profiles>
<default>
<log_queries>0</log_queries> <!-- normally it's better to keep it turned on! -->
</default>
</profiles>
</clickhouse>
You can also configure these settings to reduce the amount of data in the system.query_log table:
name | value | description
----------------------------------+-------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------
log_queries_min_type | QUERY_START | Minimal type in query_log to log, possible values (from low to high): QUERY_START, QUERY_FINISH, EXCEPTION_BEFORE_START, EXCEPTION_WHILE_PROCESSING.
log_queries_min_query_duration_ms | 0 | Minimal time for the query to run, to get to the query_log/query_thread_log.
log_queries_cut_to_length | 100000 | If query length is greater than specified threshold (in bytes), then cut query when writing to query log. Also limit length of printed query in ordinary text log.
log_profile_events | 1 | Log query performance statistics into the query_log and query_thread_log.
log_query_settings | 1 | Log query settings into the query_log.
log_queries_probability | 1 | Log queries with the specified probabality.
The other system log tables that can be disabled in profiles are:
- query_views_log
- query_thread_log
- processors_profile_log
- query_metric_log
- trace_log (https://clickhouse.com/docs/operations/system-tables/trace_log )
$ cat /etc/clickhouse-server/users.d/z_log_tables.xml
<clickhouse>
<profiles>
<default>
<log_query_views>0</log_query_views>
<log_query_threads>0</log_query_threads>
<log_processors_profiles>0</log_processors_profiles>
<query_metric_log_interval>0</query_metric_log_interval>
</default>
</profiles>
</clickhouse>
You can configure TTL
Example for query_log. It drops partitions with data older than 14 days:
$ cat /etc/clickhouse-server/config.d/query_log_ttl.xml
<?xml version="1.0"?>
<clickhouse>
<query_log replace="1">
<database>system</database>
<table>query_log</table>
<engine>ENGINE = MergeTree PARTITION BY (event_date)
ORDER BY (event_time)
TTL event_date + INTERVAL 14 DAY DELETE
</engine>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>
</clickhouse>
After that you need to restart ClickHouse and if using old clickhouse versions like 20 or less, drop or rename the existing system.query_log table and then CH creates a new table with these settings. This is automatically done in newer versions 21+.
RENAME TABLE system.query_log TO system.query_log_1;
Important part here is a daily partitioning PARTITION BY (event_date) in this case TTL expression event_date + INTERVAL 14 DAY DELETE expires all rows at the same time. In this case ClickHouse drops whole partitions. Dropping of partitions is very easy operation for CPU / Disk I/O.
Usual TTL processing (when table partitioned by toYYYYMM and TTL by day) is heavy CPU / Disk I/O consuming operation which re-writes data parts without expired rows.
You can add TTL without ClickHouse restart (and table dropping or renaming):
ALTER TABLE system.query_log MODIFY TTL event_date + INTERVAL 14 DAY;
But in this case ClickHouse will drop only whole monthly partitions (will store data older than 14 days).
One more way to configure TTL for system tables
This way just adds TTL to a table and leaves monthly (default) partitioning (will store data older than 14 days).
$ cat /etc/clickhouse-server/config.d/query_log_ttl.xml
<?xml version="1.0"?>
<clickhouse>
<query_log>
<database>system</database>
<table>query_log</table>
<ttl>event_date + INTERVAL 30 DAY DELETE</ttl>
</query_log>
</clickhouse>
💡 For the clickhouse-operator
, the above method of using only the <engine> tag without <ttl> or <partition> is recommended, because of possible configuration clashes.
After that you need to restart ClickHouse and if using old clickhouse versions like 20 or less, drop or rename the existing system.query_log table and then CH creates a new table with these settings. This is automatically done in newer versions 21+.
57 - ClickHouse® Replication problems
replication_queueCommon problems & solutions
If the replication queue does not have any Exceptions only postponed reasons without exceptions just leave ClickHouse® do Merges/Mutations and it will eventually catch up and reduce the number of tasks in
replication_queue. Number of concurrent merges and fetches can be tuned but if it is done without an analysis of your workload then you may end up in a worse situation. If Delay in queue is going up actions may be needed:First simplest approach: try to
SYSTEM RESTART REPLICA db.table(This will DETACH/ATTACH table internally)
How to check for replication problems
Check
system.replicasfirst, cluster-wide. It allows to check if the problem is local to some replica or global, and allows to see the exception. allows to answer the following questions:- Are there any ReadOnly replicas?
- Is there the connection to zookeeper active?
- Is there the exception during table init? (
Code: 999. Coordination::Exception: Transaction failed (No node): Op #1)
Check
system.replication_queue.- How many tasks there / are they moving / are there some very old tasks there? (check
created_timecolumn, if tasks are 24h old, it is a sign of a problem): - You can use this qkb article query: https://kb.altinity.com/altinity-kb-setup-and-maintenance/altinity-kb-replication-queue/
- Check if there are tasks with a high number of
num_triesornum_postponedandpostponed_reasonthis is a sign of stuck tasks. - Check the problematic parts affecting the stuck tasks. You can use columns
new_part_nameorparts_to_merge - Check which type is the task. If it is
MUTATE_PARTthen it is a mutation task. If it isMERGE_PARTSthen it is a merge task. These tasks can be deleted from the replication queue butGET_PARTSshould not be deleted.
- How many tasks there / are they moving / are there some very old tasks there? (check
Check
system.errorsCheck
system.mutations:- You can check that in the replication queue are stuck tasks of type
MUTATE_PART, and that those mutations are still executingsystem.mutationsusing columnis_done
- You can check that in the replication queue are stuck tasks of type
Find the moment when the problem started and collect/analyze / preserve logs from that moment. It is usually during the first steps of a restart/crash
Use
part_logandsystem.partsto gather information of the parts related with the stuck tasks in the replication queue:- Check if those parts exist and are active from
system.parts(use partition_id, name as part and active columns to filter) - Extract the part history from
system.part_log - Example query from
part_log:
- Check if those parts exist and are active from
SELECT hostName(), * FROM
cluster('all-sharded',system.part_log)
WHERE
hostName() IN ('chi-prod-live-2-0-0','chi-prod-live-2-2-0','chi-prod-live-2-1-0')
AND table = 'sessions_local'
AND database = 'analytics'
AND part_name in ('20230411_33631_33654_3')
- If there are no errors, just everything get slower - check the load (usual system metrics)
Some stuck replication task for a partition that was already removed or has no data
This can be easily detected because some exceptions will be in the replication queue that reference a part from a partition that do not exist. Here the most probable scenario is that the partition was dropped and some tasks were left in the queue.
drop the partition manually once again (it should remove the task)
If the partition exists but the part is missing (maybe because it is superseded by a newer merged part) then you can try to DETACH/ATTACH the partition.
Below DML generates the ALTER commands to do this:
WITH
extract(new_part_name, '^[^_]+') as partition_id
SELECT
'/* count: ' || count() || ' */\n' ||
'ALTER TABLE ' || database || '.' || table || ' DETACH PARTITION ID \''|| partition_id || '\';\n' ||
'ALTER TABLE ' || database || '.' || table || ' ATTACH PARTITION ID \''|| partition_id || '\';\n'
FROM
system.replication_queue as rq
GROUP BY
database, table, partition_id
HAVING sum(num_tries) > 1000 OR count() > 100
ORDER BY count() DESC, sum(num_tries) DESC
FORMAT TSVRaw;
Problem with mutation stuck in the queue
This can happen if the mutation is finished and, for some reason, the task is not removed from the queue. This can be detected by checking
system.mutationstable and seeing if the mutation is done, but the task is still in the queue.kill the mutation (again)
Replica is not starting because local set of files differs too much
- First try increase the thresholds or set flag
force_restore_dataflag and restarting clickhouse/pod https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/replication#recovery-after-complete-data-loss
Replica is in Read-Only MODE
Sometimes, due to crashes, zookeeper unavailability, slowness, or other reasons, some of the tables can be in Read-Only mode. This allows SELECTS but not INSERTS. So we need to do DROP / RESTORE replica procedure.
Just to be clear, this procedure will not delete any data, it will just re-create the metadata in zookeeper with the current state of the ClickHouse replica .
How it works:
ALTER TABLE table_name DROP DETACHED PARTITION ALL -- clean detached folder before operation. PARTITION ALL works only for the fresh clickhouse versions
DETACH TABLE table_name; -- Required for DROP REPLICA
-- Use the zookeeper_path and replica_name from system.replicas.
SYSTEM DROP REPLICA 'replica_name' FROM ZKPATH '/table_path_in_zk'; -- It will remove everything from the /table_path_in_zk/replicas/replica_name
ATTACH TABLE table_name; -- Table will be in readonly mode, because there is no metadata in ZK and after that execute
SYSTEM RESTORE REPLICA table_name; -- It will detach all partitions, re-create metadata in ZK (like it's new empty table), and then attach all partitions back
SYSTEM SYNC REPLICA table_name; -- Not mandatory. It will Wait for replicas to synchronize parts. Also it's recommended to check `system.detached_parts` on all replicas after recovery is finished.
SELECT name FROM system.detached_parts WHERE table = 'table_name'; -- check for leftovers. See the potential problems here https://altinity.com/blog/understanding-detached-parts-in-clickhouse
Starting from version 23, it’s possible to use syntax SYSTEM DROP REPLICA 'replica_name' FROM TABLE db.table
instead of the ZKPATH variant, but you need to execute the above command from a different replica than the one you want to drop, which is not convenient sometimes. We recommend using the above method because it works with any version and is more reliable.
Procedure to restore multiple tables in Read-Only mode per replica
It is better to make an approach per replica, because restoring a replica using ON CLUSTER could lead to race conditions that would cause errors and a big stress in zookeeper/keeper
SELECT
'-- Table ' || toString(row_num) || '\n' ||
'DETACH TABLE `' || database || '`.`' || table || '`;\n' ||
'SYSTEM DROP REPLICA ''' || replica_name || ''' FROM ZKPATH ''' || zookeeper_path || ''';\n' ||
'ATTACH TABLE `' || database || '`.`' || table || '`;\n' ||
'SYSTEM RESTORE REPLICA `' || database || '`.`' || table || '`;\n'
FROM (
SELECT
*,
rowNumberInAllBlocks() + 1 as row_num
FROM (
SELECT
database,
table,
any(replica_name) as replica_name,
any(zookeeper_path) as zookeeper_path
FROM system.replicas
WHERE is_readonly
GROUP BY database, table
ORDER BY database, table
)
ORDER BY database, table
)
FORMAT TSVRaw;
This will generate the DDL statements to be executed per replica and generate an ouput that can be saved as an SQL file . It is important to execute the commands per replica in the sequence generated by the above DDL:
- DETACH the table
- DROP REPLICA
- ATTACH the table
- RESTORE REPLICA
If we do this in parallel a table could still be attaching while another query is dropping/restoring the replica in zookeeper, causing errors.
The following bash script will read the generated SQL file and execute the commands sequentially, asking for user input in case of errors. Simply save the generated SQL to a file (e.g. recovery_commands.sql) and run the script below (that you can name as clickhouse_replica_recovery.sh):
$ clickhouse_replica_recovery.sh recovery_commands.sql
Here the script:
#!/bin/bash
# ClickHouse Replica Recovery Script
# This script executes DETACH, DROP REPLICA, ATTACH, and RESTORE REPLICA commands sequentially
# Configuration
CLICKHOUSE_HOST="${CLICKHOUSE_HOST:-localhost}"
CLICKHOUSE_PORT="${CLICKHOUSE_PORT:-9000}"
CLICKHOUSE_USER="${CLICKHOUSE_USER:-clickhouse_operator}"
CLICKHOUSE_PASSWORD="${CLICKHOUSE_PASSWORD:-xxxxxxxxx}"
COMMANDS_FILE="${1:-recovery_commands.sql}"
LOG_FILE="recovery_$(date +%Y%m%d_%H%M%S).log"
# Colors for output
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
BLUE='\033[0;34m'
MAGENTA='\033[0;35m'
NC='\033[0m' # No Color
# Function to log messages
log() {
echo -e "[$(date '+%Y-%m-%d %H:%M:%S')] $1" | tee -a "$LOG_FILE"
}
# Function to execute a SQL statement with retry logic
execute_sql() {
local sql="$1"
local table_num="$2"
local step_name="$3"
while true; do
log "${YELLOW}Executing command for Table $table_num - $step_name:${NC}"
log "$sql"
# Build clickhouse-client command
local ch_cmd="clickhouse-client --host=$CLICKHOUSE_HOST --port=$CLICKHOUSE_PORT --user=$CLICKHOUSE_USER"
if [ -n "$CLICKHOUSE_PASSWORD" ]; then
ch_cmd="$ch_cmd --password=$CLICKHOUSE_PASSWORD"
fi
# Execute the command and capture output and exit code
local output
local exit_code
output=$(echo "$sql" | $ch_cmd 2>&1)
exit_code=$?
# Log the output
echo "$output" | tee -a "$LOG_FILE"
if [ $exit_code -eq 0 ]; then
log "${GREEN}✓ Successfully executed${NC}"
return 0
else
log "${RED}✗ Failed to execute (Exit code: $exit_code)${NC}"
log "${RED}Error output: $output${NC}"
# Ask user what to do
while true; do
echo ""
log "${MAGENTA}========================================${NC}"
log "${MAGENTA}Error occurred! Choose an option:${NC}"
log "${MAGENTA}========================================${NC}"
echo -e "${YELLOW}[R]${NC} - Retry this command"
echo -e "${YELLOW}[I]${NC} - Ignore this error and continue to next command in this table"
echo -e "${YELLOW}[S]${NC} - Skip this entire table and move to next table"
echo -e "${YELLOW}[A]${NC} - Abort script execution"
echo ""
echo -n "Enter your choice (R/I/S/A): "
# Read from /dev/tty to get user input from terminal
read -r response < /dev/tty
case "${response^^}" in
R|RETRY)
log "${BLUE}Retrying command...${NC}"
break # Break inner loop to retry
;;
I|IGNORE)
log "${YELLOW}Ignoring error and continuing to next command...${NC}"
return 1 # Return error but continue
;;
S|SKIP)
log "${YELLOW}Skipping entire table $table_num...${NC}"
return 2 # Return special code to skip table
;;
A|ABORT)
log "${RED}Aborting script execution...${NC}"
exit 1
;;
*)
echo -e "${RED}Invalid option '$response'. Please enter R, I, S, or A.${NC}"
;;
esac
done
fi
done
}
# Main execution function
main() {
log "${BLUE}========================================${NC}"
log "${BLUE}ClickHouse Replica Recovery Script${NC}"
log "${BLUE}========================================${NC}"
log "Host: $CLICKHOUSE_HOST:$CLICKHOUSE_PORT"
log "User: $CLICKHOUSE_USER"
log "Commands file: $COMMANDS_FILE"
log "Log file: $LOG_FILE"
echo ""
# Check if commands file exists
if [ ! -f "$COMMANDS_FILE" ]; then
log "${RED}Error: Commands file '$COMMANDS_FILE' not found!${NC}"
echo ""
echo "Usage: $0 [commands_file]"
echo " commands_file: Path to SQL commands file (default: recovery_commands.sql)"
echo ""
echo "Example: $0 my_commands.sql"
exit 1
fi
# Process SQL commands from file
local current_sql=""
local table_counter=0
local step_in_table=0
local failed_count=0
local success_count=0
local ignored_count=0
local skipped_tables=()
local skip_current_table=false
while IFS= read -r line || [ -n "$line" ]; do
# Skip empty lines
if [[ -z "$line" ]] || [[ "$line" =~ ^[[:space:]]*$ ]]; then
continue
fi
# Check if this is a comment line indicating a new table
if [[ "$line" =~ ^[[:space:]]*--[[:space:]]*Table[[:space:]]+([0-9]+) ]]; then
table_counter="${BASH_REMATCH[1]}"
step_in_table=0
skip_current_table=false
log ""
log "${BLUE}========================================${NC}"
log "${BLUE}Processing Table $table_counter${NC}"
log "${BLUE}========================================${NC}"
continue
elif [[ "$line" =~ ^[[:space:]]*-- ]]; then
# Skip other comment lines
continue
fi
# Skip if we're skipping this table
if [ "$skip_current_table" = true ]; then
# Check if line ends with semicolon to count statements
if [[ "$line" =~ \;[[:space:]]*$ ]]; then
step_in_table=$((step_in_table + 1))
fi
continue
fi
# Accumulate the SQL statement
current_sql+="$line "
# Check if we have a complete statement (ends with semicolon)
if [[ "$line" =~ \;[[:space:]]*$ ]]; then
step_in_table=$((step_in_table + 1))
# Determine the step name
local step_name=""
if [[ "$current_sql" =~ ^[[:space:]]*DETACH ]]; then
step_name="DETACH"
elif [[ "$current_sql" =~ ^[[:space:]]*SYSTEM[[:space:]]+DROP[[:space:]]+REPLICA ]]; then
step_name="DROP REPLICA"
elif [[ "$current_sql" =~ ^[[:space:]]*ATTACH ]]; then
step_name="ATTACH"
elif [[ "$current_sql" =~ ^[[:space:]]*SYSTEM[[:space:]]+RESTORE[[:space:]]+REPLICA ]]; then
step_name="RESTORE REPLICA"
fi
log ""
log "Step $step_in_table/4: $step_name"
# Execute the statement
local result
execute_sql "$current_sql" "$table_counter" "$step_name"
result=$?
if [ $result -eq 0 ]; then
success_count=$((success_count + 1))
sleep 1 # Small delay between commands
elif [ $result -eq 1 ]; then
# User chose to ignore this error
failed_count=$((failed_count + 1))
ignored_count=$((ignored_count + 1))
sleep 1
elif [ $result -eq 2 ]; then
# User chose to skip this table
skip_current_table=true
skipped_tables+=("$table_counter")
log "${YELLOW}Skipping remaining commands for Table $table_counter${NC}"
fi
# Reset current_sql for next statement
current_sql=""
fi
done < "$COMMANDS_FILE"
# Summary
log ""
log "${BLUE}========================================${NC}"
log "${BLUE}Execution Summary${NC}"
log "${BLUE}========================================${NC}"
log "Total successful commands: ${GREEN}$success_count${NC}"
log "Total failed commands: ${RED}$failed_count${NC}"
log "Total ignored errors: ${YELLOW}$ignored_count${NC}"
log "Total tables processed: $table_counter"
if [ ${#skipped_tables[@]} -gt 0 ]; then
log "Skipped tables: ${YELLOW}${skipped_tables[*]}${NC}"
fi
log "Log file: $LOG_FILE"
if [ $failed_count -eq 0 ]; then
log "${GREEN}All commands executed successfully!${NC}"
exit 0
else
log "${YELLOW}Some commands failed or were ignored. Please check the log file.${NC}"
exit 1
fi
}
# Run the main function
main
58 - Replication queue
SELECT
database,
table,
type,
max(last_exception),
max(postpone_reason),
min(create_time),
max(last_attempt_time),
max(last_postpone_time),
max(num_postponed) AS max_postponed,
max(num_tries) AS max_tries,
min(num_tries) AS min_tries,
countIf(last_exception != '') AS count_err,
countIf(num_postponed > 0) AS count_postponed,
countIf(is_currently_executing) AS count_executing,
count() AS count_all
FROM system.replication_queue
GROUP BY
database,
table,
type
ORDER BY count_all DESC
59 - Schema migration tools for ClickHouse®
- atlas
- golang-migrate tool - see golang-migrate
- liquibase
- HousePlant
- New CLI migration tool (Dec2024) for ClickHouse developed by June
- Documentation https://houseplant.readthedocs.io/en/latest/index.html
- Github https://github.com/juneHQ/houseplant
- ClickSuite
- developed by GameBeast
- A robust CLI tool for managing ClickHouse database migrations with environment-specific configurations and TypeScript support.
- Github https://github.com/GamebeastGG/clicksuite
- Flyway
- Official community supported plugin git https://github.com/flyway/flyway-community-db-support
- Old pull requests (latest at the top):
- https://github.com/flyway/flyway/pull/3333 СlickHouse support
- https://github.com/flyway/flyway/pull/3134 СlickHouse support
- https://github.com/flyway/flyway/pull/3133 Add support ClickHouse
- https://github.com/flyway/flyway/pull/2981 ClickHouse replicated
- https://github.com/flyway/flyway/pull/2640 Yet another ClickHouse support
- https://github.com/flyway/flyway/pull/2166 ClickHouse support (#1772)
- https://github.com/flyway/flyway/pull/1773 Fixed #1772: Add support for ClickHouse (https://clickhouse.yandex/ )
- alembic
- bytebase
- custom tool for ClickHouse for python
- phpMigrations
- dbmate
Know more?
https://clickhouse.com/docs/knowledgebase/schema_migration_tools
Article on migrations in ClickHouse https://posthog.com/blog/async-migrations
59.1 - golang-migrate
migrate
migrate is a simple schema migration tool written in golang. No external dependencies are required (like interpreter, jre), only one platform-specific executable. golang-migrate/migrate
migrate supports several databases, including ClickHouse® (support was introduced by @kshvakov
).
To store information about migrations state migrate creates one additional table in target database, by default that table is called schema_migrations.
Install
download
the migrate executable for your platform and put it to the folder listed in your %PATH.
#wget https://github.com/golang-migrate/migrate/releases/download/v3.2.0/migrate.linux-amd64.tar.gz
wget https://github.com/golang-migrate/migrate/releases/download/v4.14.1/migrate.linux-amd64.tar.gz
tar -xzf migrate.linux-amd64.tar.gz
mkdir -p ~/bin
mv migrate.linux-amd64 ~/bin/migrate
rm migrate.linux-amd64.tar.gz
Sample usage
mkdir migrations
echo 'create table test(id UInt8) Engine = Memory;' > migrations/000001_my_database_init.up.sql
echo 'DROP TABLE test;' > migrations/000001_my_database_init.down.sql
# you can also auto-create file with new migrations with automatic numbering like that:
migrate create -dir migrations -seq -digits 6 -ext sql my_database_init
edit migrations/000001_my_database_init.up.sql & migrations/000001_my_database_init.down.sql
migrate -database 'clickhouse://localhost:9000' -path ./migrations up
1/u my_database_init (6.502974ms)
migrate -database 'clickhouse://localhost:9000' -path ./migrations down
1/d my_database_init (2.164394ms)
# clears the database (use carefully - will not ask any confirmations)
➜ migrate -database 'clickhouse://localhost:9000' -path ./migrations drop
Connection string format
clickhouse://host:port?username=user&password=qwerty&database=clicks
| URL Query | Description |
|---|---|
x-migrations-table | Name of the migrations table |
x-migrations-table-engine | Engine to use for the migrations table, defaults to TinyLog |
x-cluster-name | Name of cluster for creating table cluster wide |
database | The name of the database to connect to |
username | The user to sign in as |
password | The user’s password |
host | The host to connect to. |
port | The port to bind to. |
secure | to use a secure connection (for self-signed also add skip_verify=1) |
Replicated / Distributed / Cluster environments
golang-migrate supports a clustered ClickHouse environment since v4.15.0.
If you provide x-cluster-name query param, it will create the table to store migration data on the passed cluster.
Known issues
could not load time location: unknown time zone Europe/Moscow in line 0:
It’s happens due of missing tzdata package in migrate/migrate docker image of golang-migrate. There is 2 possible solutions:
- You can build your own golang-migrate image from official with tzdata package.
- If you using it as part of your CI you can add installing tzdata package as one of step in CI before using golang-migrate.
Related GitHub issues: https://github.com/golang-migrate/migrate/issues/494 https://github.com/golang-migrate/migrate/issues/201
Using database name in x-migrations-table
- Creates table with
database.table - When running migrations migrate actually uses database from query settings and encapsulate
database.tableas table name: ``other_database.`database.table```
60 - Settings to adjust
query_logand other_logtables - set up TTL, or some other cleanup procedures.cat /etc/clickhouse-server/config.d/query_log.xml <clickhouse> <query_log replace="1"> <database>system</database> <table>query_log</table> <flush_interval_milliseconds>7500</flush_interval_milliseconds> <engine> ENGINE = MergeTree PARTITION BY event_date ORDER BY (event_time) TTL event_date + interval 90 day SETTINGS ttl_only_drop_parts=1 </engine> </query_log> </clickhouse>query_thread_log- typically is not too useful for end users, you can disable it (or set up TTL). We do not recommend removing this table completely as you might need it for debug one day and the threads’ logging can be easily disabled/enabled without a restart through user profiles:$ cat /etc/clickhouse-server/users.d/z_log_queries.xml <clickhouse> <profiles> <default> <log_query_threads>0</log_query_threads> </default> </profiles> </clickhouse>If you have a good monitoring outside ClickHouse® you don’t need to store the history of metrics in ClickHouse
cat /etc/clickhouse-server/config.d/disable_metric_logs.xml <clickhouse> <metric_log remove="1" /> <asynchronous_metric_log remove="1" /> </clickhouse>part_log- may be nice, especially at the beginning / during system tuning/analyze.cat /etc/clickhouse-server/config.d/part_log.xml <clickhouse> <part_log replace="1"> <database>system</database> <table>part_log</table> <flush_interval_milliseconds>7500</flush_interval_milliseconds> <engine> ENGINE = MergeTree PARTITION BY toYYYYMM(event_date) ORDER BY (event_time) TTL toStartOfMonth(event_date) + INTERVAL 3 MONTH SETTINGS ttl_only_drop_parts=1 </engine> </part_log> </clickhouse>on older versions
log_queriesis disabled by default, it’s worth having it enabled always.$ cat /etc/clickhouse-server/users.d/log_queries.xml <clickhouse> <profiles> <default> <log_queries>1</log_queries> </default> </profiles> </clickhouse>quite often you want to have on-disk group by / order by enabled (both disabled by default).
cat /etc/clickhouse-server/users.d/enable_on_disk_operations.xml <clickhouse> <profiles> <default> <max_bytes_before_external_group_by>2000000000</max_bytes_before_external_group_by> <max_bytes_before_external_sort>2000000000</max_bytes_before_external_sort> </default> </profiles> </clickhouse>quite often you want to create more users with different limitations. The most typical is
<max_execution_time>It’s actually also not a way to plan/share existing resources better, but it at least disciplines users.Also introducing some restrictions on query complexity can be a good option to discipline users.
You can find the preset example here . Also, force_index_by_date + force_primary_key can be a nice idea to avoid queries that ‘accidentally’ do full scans, max_concurrent_queries_for_user
merge_tree settings:
max_bytes_to_merge_at_max_space_in_pool(may be reduced in some scenarios),inactive_parts_to_throw_insert- can be enabled,replicated_deduplication_window- can be extended if single insert create lot of parts ,merge_with_ttl_timeout- when you use ttlinsert_distributed_sync- for small clusters you may sometimes want to enable itwhen the durability is the main requirement (or server / storage is not stable) - you may want to enable
fsync_*setting (impacts the write performance significantly!!), andinsert_quorumIf you use FINAL queries - usually you want to enable
do_not_merge_across_partitions_select_finalmemory usage per server / query / user: memory configuration settings
if you use async_inserts - you often may want to increase max_concurrent_queries
<clickhouse>
<max_concurrent_queries>500</max_concurrent_queries>
<max_concurrent_insert_queries>400</max_concurrent_insert_queries>
<max_concurrent_select_queries>100</max_concurrent_select_queries>
</clickhouse>
- materialize_ttl_after_modify=0
- access_management=1
- secret in <remote_servers>
See also:
https://docs.altinity.com/operationsguide/security/clickhouse-hardening-guide/
61 - Shutting down a node
It’s possible to shutdown server on fly, but that would lead to failure of some queries.
More safer way:
Remove server (which is going to be disabled) from remote_server section of config.xml on all servers.
- avoid removing the last replica of the shard (that can lead to incorrect data placement if you use non-random distribution)
Remove server from load balancer, so new queries wouldn’t hit it.
Detach Kafka / Rabbit / Buffer tables (if used), and Materialized* databases.
Wait until all already running queries would finish execution on it. It’s possible to check it via query:
SHOW PROCESSLIST;Ensure there is no pending data in distributed tables
SELECT * FROM system.distribution_queue; SYSTEM FLUSH DISTRIBUTED <table_name>;Run sync replica query in related shard replicas (others than the one you remove) via query:
SYSTEM SYNC REPLICA db.table;Shutdown server.
SYSTEM SHUTDOWN query by default doesn’t wait until query completion and tries to kill all queries immediately after receiving signal, if you want to change this behavior, you need to enable setting shutdown_wait_unfinished_queries.
62 - SSL connection unexpectedly closed
ClickHouse doesn’t probe CA path which is default on CentOS and Amazon Linux.
ClickHouse client
cat /etc/clickhouse-client/conf.d/openssl-ca.xml
<config>
<openSSL>
<client> <!-- Used for connection to server's secure tcp port -->
<caConfig>/etc/ssl/certs</caConfig>
</client>
</openSSL>
</config>
ClickHouse server
cat /etc/clickhouse-server/conf.d/openssl-ca.xml
<config>
<openSSL>
<server> <!-- Used for https server AND secure tcp port -->
<caConfig>/etc/ssl/certs</caConfig>
</server>
<client> <!-- Used for connecting to https dictionary source and secured Zookeeper communication -->
<caConfig>/etc/ssl/certs</caConfig>
</client>
</openSSL>
</config>
63 - Suspiciously many broken parts
Symptom:
clickhouse fails to start with a message DB::Exception: Suspiciously many broken parts to remove.
Cause:
That exception is just a safeguard check/circuit breaker, triggered when clickhouse detects a lot of broken parts during server startup.
Parts are considered broken if they have bad checksums or some files are missing or malformed. Usually, that means the data was corrupted on the disk.
Why data could be corrupted?
the most often reason is a hard restart of the system, leading to a loss of the data which was not fully flushed to disk from the system page cache. Please be aware that by default ClickHouse doesn’t do fsync, so data is considered inserted after it was passed to the Linux page cache. See fsync-related settings in ClickHouse.
it can also be caused by disk failures, maybe there are bad blocks on hard disk, or logical problems, or some raid issue. Check system journals, use
fsck/mdadmand other standard tools to diagnose the disk problem.other reasons: manual intervention/bugs etc, for example, the data files or folders are removed by mistake or moved to another folder.
Action:
If you are ok to accept the data loss : set up
force_restore_dataflag and clickhouse will move the parts to detached. Data loss is possible if the issue is a result of misconfiguration (i.e. someone accidentally has fixed xml configs with incorrect shard/replica macros , data will be moved to detached folder and can be recovered).sudo -u clickhouse touch /var/lib/clickhouse/flags/force_restore_datathen restart clickhouse. the table will be attached, and the broken parts will be detached, which means the data from those parts will not be available for the selects. You can see the list of those parts in the
system.detached_partstable and drop them if needed usingALTER TABLE ... DROP DETACHED PART ...commands.If you are ok to tolerate bigger losses automatically you can change that safeguard configuration to be less sensitive by increasing
max_suspicious_broken_partssetting:cat /etc/clickhouse-server/config.d/max_suspicious_broken_parts.xml <?xml version="1.0"?> <clickhouse> <merge_tree> <max_suspicious_broken_parts>50</max_suspicious_broken_parts> </merge_tree> </clickhouse>this limit is set to 100 by default in recent releases. We can set a bigger value (250 or more), but the data will be lost because of the corruption.
Check out also a similar setting
max_suspicious_broken_parts_bytes.
See https://clickhouse.com/docs/en/operations/settings/merge-tree-settings/If you can’t accept the data loss - you should recover data from backups / re-insert it once again etc.
If you don’t want to tolerate automatic detaching of broken parts, you can set
max_suspicious_broken_parts_bytesandmax_suspicious_broken_partsto 0.
Scenario illustrating / testing
- Create table
create table t111(A UInt32) Engine=MergeTree order by A settings max_suspicious_broken_parts=1;
insert into t111 select number from numbers(100000);
- Detach the table and make Data corruption
detach table t111;
cd /var/lib/clickhouse/data/default/t111/all_*** make data file corruption:
> data.bin
repeat for 2 or more data files.
- Attach the table:
attach table t111;
Received exception from server (version 21.12.3):
Code: 231. DB::Exception: Received from localhost:9000. DB::Exception: Suspiciously many (2) broken parts to remove.. (TOO_MANY_UNEXPEC
- setup force_restore_data flag
sudo -u clickhouse touch /var/lib/clickhouse/flags/force_restore_data
sudo service clickhouse-server restart
then the table t111 will be attached, losing the corrupted data.
64 - Threads
Count threads used by clickhouse-server
cat /proc/$(pidof -s clickhouse-server)/status | grep Threads
Threads: 103
ps hH $(pidof -s clickhouse-server) | wc -l
103
ps hH -AF | grep clickhouse | wc -l
116
Thread counts by type (using ps & clickhouse-local)
ps H -o 'tid comm' $(pidof -s clickhouse-server) | tail -n +2 | awk '{ printf("%s\t%s\n", $1, $2) }' | clickhouse-local -S "threadid UInt16, name String" -q "SELECT name, count() FROM table GROUP BY name WITH TOTALS ORDER BY count() DESC FORMAT PrettyCompact"
Threads used by running queries:
SELECT query, length(thread_ids) AS threads_count FROM system.processes ORDER BY threads_count;
Thread pools limits & usage
SELECT
name,
value
FROM system.settings
WHERE name LIKE '%pool%'
┌─name─────────────────────────────────────────┬─value─┐
│ connection_pool_max_wait_ms │ 0 │
│ distributed_connections_pool_size │ 1024 │
│ background_buffer_flush_schedule_pool_size │ 16 │
│ background_pool_size │ 16 │
│ background_move_pool_size │ 8 │
│ background_fetches_pool_size │ 8 │
│ background_schedule_pool_size │ 16 │
│ background_message_broker_schedule_pool_size │ 16 │
│ background_distributed_schedule_pool_size │ 16 │
│ postgresql_connection_pool_size │ 16 │
│ postgresql_connection_pool_wait_timeout │ -1 │
│ odbc_bridge_connection_pool_size │ 16 │
└──────────────────────────────────────────────┴───────┘
SELECT
metric,
value
FROM system.metrics
WHERE metric LIKE 'Background%'
┌─metric──────────────────────────────────┬─value─┐
│ BackgroundPoolTask │ 0 │
│ BackgroundFetchesPoolTask │ 0 │
│ BackgroundMovePoolTask │ 0 │
│ BackgroundSchedulePoolTask │ 0 │
│ BackgroundBufferFlushSchedulePoolTask │ 0 │
│ BackgroundDistributedSchedulePoolTask │ 0 │
│ BackgroundMessageBrokerSchedulePoolTask │ 0 │
└─────────────────────────────────────────┴───────┘
SELECT *
FROM system.asynchronous_metrics
WHERE lower(metric) LIKE '%thread%'
ORDER BY metric ASC
┌─metric───────────────────────────────────┬─value─┐
│ HTTPThreads │ 0 │
│ InterserverThreads │ 0 │
│ MySQLThreads │ 0 │
│ OSThreadsRunnable │ 2 │
│ OSThreadsTotal │ 2910 │
│ PostgreSQLThreads │ 0 │
│ TCPThreads │ 1 │
│ jemalloc.background_thread.num_runs │ 0 │
│ jemalloc.background_thread.num_threads │ 0 │
│ jemalloc.background_thread.run_intervals │ 0 │
└──────────────────────────────────────────┴───────┘
SELECT *
FROM system.metrics
WHERE lower(metric) LIKE '%thread%'
ORDER BY metric ASC
Query id: 6acbb596-e28f-4f89-94b2-27dccfe88ee9
┌─metric─────────────┬─value─┬─description───────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ GlobalThread │ 151 │ Number of threads in global thread pool. │
│ GlobalThreadActive │ 144 │ Number of threads in global thread pool running a task. │
│ LocalThread │ 0 │ Number of threads in local thread pools. The threads in local thread pools are taken from the global thread pool. │
│ LocalThreadActive │ 0 │ Number of threads in local thread pools running a task. │
│ QueryThread │ 0 │ Number of query processing threads │
└────────────────────┴───────┴───────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Stack traces of the working threads from the pools
SET allow_introspection_functions = 1;
WITH arrayMap(x -> demangle(addressToSymbol(x)), trace) AS all
SELECT
thread_id,
query_id,
arrayStringConcat(all, '\n') AS res
FROM system.stack_trace
WHERE res ILIKE '%Pool%'
FORMAT Vertical;
65 - Who ate my ClickHouse® memory?
SYSTEM JEMALLOC PURGE;
SELECT 'OS' as group, metric as name, toInt64(value) as val FROM system.asynchronous_metrics WHERE metric like 'OSMemory%'
UNION ALL
SELECT 'Caches' as group, metric as name, toInt64(value) FROM system.asynchronous_metrics WHERE metric LIKE '%CacheBytes'
UNION ALL
SELECT 'Caches' as group, metric as name, toInt64(value) FROM system.metrics WHERE metric LIKE '%CacheBytes'
UNION ALL
SELECT 'MMaps' as group, metric as name, toInt64(value) FROM system.metrics WHERE metric LIKE 'MMappedFileBytes'
UNION ALL
SELECT 'Process' as group, metric as name, toInt64(value) FROM system.asynchronous_metrics WHERE metric LIKE 'Memory%'
UNION ALL
SELECT 'MemoryTable', engine as name, toInt64(sum(total_bytes)) FROM system.tables WHERE engine IN ('Join','Memory','Buffer','Set') GROUP BY engine
UNION ALL
SELECT 'StorageBuffer' as group, metric as name, toInt64(value) FROM system.metrics WHERE metric='StorageBufferBytes'
UNION ALL
SELECT 'Queries' as group, left(query,7) as name, toInt64(sum(memory_usage)) FROM system.processes GROUP BY name
UNION ALL
SELECT 'Dictionaries' as group, type as name, toInt64(sum(bytes_allocated)) FROM system.dictionaries GROUP BY name
UNION ALL
SELECT 'PrimaryKeys' as group, 'db:'||database as name, toInt64(sum(primary_key_bytes_in_memory_allocated)) FROM system.parts GROUP BY name
UNION ALL
SELECT 'Merges' as group, 'db:'||database as name, toInt64(sum(memory_usage)) FROM system.merges GROUP BY name
UNION ALL
SELECT 'InMemoryParts' as group, 'db:'||database as name, toInt64(sum(data_uncompressed_bytes)) FROM system.parts WHERE part_type = 'InMemory' GROUP BY name
UNION ALL
SELECT 'AsyncInserts' as group, 'db:'||database as name, toInt64(sum(total_bytes)) FROM system.asynchronous_inserts GROUP BY name
UNION ALL
SELECT 'FileBuffersVirtual' as group, metric as name, toInt64(value * 2*1024*1024) FROM system.metrics WHERE metric like 'OpenFileFor%'
UNION ALL
SELECT 'ThreadStacksVirual' as group, metric as name, toInt64(value * 8*1024*1024) FROM system.metrics WHERE metric = 'GlobalThread'
UNION ALL
SELECT 'UserMemoryTracking' as group, user as name, toInt64(memory_usage) FROM system.user_processes
UNION ALL
select 'QueryCacheBytes' as group, '', toInt64(sum(result_size)) FROM system.query_cache
UNION ALL
SELECT 'MemoryTracking' as group, 'total' as name, toInt64(value) FROM system.metrics WHERE metric = 'MemoryTracking'
SELECT *, formatReadableSize(value)
FROM system.metrics
WHERE (metric ilike '%Cach%' or metric ilike '%Mem%') and value != 0
order by metric format PrettyCompactMonoBlock;
SELECT *, formatReadableSize(value)
FROM system.asynchronous_metrics
WHERE metric like '%Cach%' or metric like '%Mem%'
order by metric format PrettyCompactMonoBlock;
SELECT event_time, metric, value, formatReadableSize(value)
FROM system.asynchronous_metric_log
WHERE event_time > now() - 600 and (metric like '%Cach%' or metric like '%Mem%') and value <> 0
order by metric, event_time format PrettyCompactMonoBlock;
SELECT formatReadableSize(sum(bytes_allocated)) FROM system.dictionaries;
SELECT
database,
name,
formatReadableSize(total_bytes)
FROM system.tables
WHERE engine IN ('Memory','Set','Join');
SELECT
sumIf(data_uncompressed_bytes, part_type = 'InMemory') as memory_parts,
formatReadableSize(sum(primary_key_bytes_in_memory)) AS primary_key_bytes_in_memory,
formatReadableSize(sum(primary_key_bytes_in_memory_allocated)) AS primary_key_bytes_in_memory_allocated
FROM system.parts;
SELECT formatReadableSize(sum(memory_usage)) FROM system.merges;
SELECT formatReadableSize(sum(memory_usage)) FROM system.processes;
select formatReadableSize(sum(result_size)) FROM system.query_cache;
SELECT
initial_query_id,
elapsed,
formatReadableSize(memory_usage),
formatReadableSize(peak_memory_usage),
query
FROM system.processes
ORDER BY peak_memory_usage DESC
LIMIT 10;
SELECT
type,
event_time,
initial_query_id,
formatReadableSize(memory_usage),
query
FROM system.query_log
WHERE (event_date >= today()) AND (event_time >= (now() - 7200))
ORDER BY memory_usage DESC
LIMIT 10;
for i in `seq 1 600`; do clickhouse-client --empty_result_for_aggregation_by_empty_set=0 -q "select (select 'Merges: \
'||formatReadableSize(sum(memory_usage)) from system.merges), (select \
'Processes: '||formatReadableSize(sum(memory_usage)) from system.processes)";\
sleep 3; done
Merges: 96.57 MiB Processes: 41.98 MiB
Merges: 82.24 MiB Processes: 41.91 MiB
Merges: 66.33 MiB Processes: 41.91 MiB
Merges: 66.49 MiB Processes: 37.13 MiB
Merges: 67.78 MiB Processes: 37.13 MiB
echo " Merges Processes PrimaryK TempTabs Dicts"; \
for i in `seq 1 600`; do clickhouse-client --empty_result_for_aggregation_by_empty_set=0 -q "select \
(select leftPad(formatReadableSize(sum(memory_usage)),15, ' ') from system.merges)||
(select leftPad(formatReadableSize(sum(memory_usage)),15, ' ') from system.processes)||
(select leftPad(formatReadableSize(sum(primary_key_bytes_in_memory_allocated)),15, ' ') from system.parts)|| \
(select leftPad(formatReadableSize(sum(total_bytes)),15, ' ') from system.tables \
WHERE engine IN ('Memory','Set','Join'))||
(select leftPad(formatReadableSize(sum(bytes_allocated)),15, ' ') FROM system.dictionaries)
"; sleep 3; done
Merges Processes PrimaryK TempTabs Dicts
0.00 B 0.00 B 21.36 MiB 1.58 GiB 911.07 MiB
0.00 B 0.00 B 21.36 MiB 1.58 GiB 911.07 MiB
0.00 B 0.00 B 21.35 MiB 1.58 GiB 911.07 MiB
0.00 B 0.00 B 21.36 MiB 1.58 GiB 911.07 MiB
retrospection analysis of the RAM usage based on query_log and part_log (shows peaks)
WITH
now() - INTERVAL 24 HOUR AS min_time, -- you can adjust that
now() AS max_time, -- you can adjust that
INTERVAL 1 HOUR as time_frame_size
SELECT
toStartOfInterval(event_timestamp, time_frame_size) as timeframe,
formatReadableSize(max(mem_overall)) as peak_ram,
formatReadableSize(maxIf(mem_by_type, event_type='Insert')) as inserts_ram,
formatReadableSize(maxIf(mem_by_type, event_type='Select')) as selects_ram,
formatReadableSize(maxIf(mem_by_type, event_type='MergeParts')) as merge_ram,
formatReadableSize(maxIf(mem_by_type, event_type='MutatePart')) as mutate_ram,
formatReadableSize(maxIf(mem_by_type, event_type='Alter')) as alter_ram,
formatReadableSize(maxIf(mem_by_type, event_type='Create')) as create_ram,
formatReadableSize(maxIf(mem_by_type, event_type not IN ('Insert', 'Select', 'MergeParts','MutatePart', 'Alter', 'Create') )) as other_types_ram,
groupUniqArrayIf(event_type, event_type not IN ('Insert', 'Select', 'MergeParts','MutatePart', 'Alter', 'Create') ) as other_types
FROM (
SELECT
toDateTime( toUInt32(ts) ) as event_timestamp,
t as event_type,
SUM(mem) OVER (PARTITION BY t ORDER BY ts) as mem_by_type,
SUM(mem) OVER (ORDER BY ts) as mem_overall
FROM
(
WITH arrayJoin([(toFloat64(event_time_microseconds) - (duration_ms / 1000), toInt64(peak_memory_usage)), (toFloat64(event_time_microseconds), -peak_memory_usage)]) AS data
SELECT
CAST(event_type,'LowCardinality(String)') as t,
data.1 as ts,
data.2 as mem
FROM system.part_log
WHERE event_time BETWEEN min_time AND max_time AND peak_memory_usage != 0
UNION ALL
WITH arrayJoin([(toFloat64(query_start_time_microseconds), toInt64(memory_usage)), (toFloat64(event_time_microseconds), -memory_usage)]) AS data
SELECT
query_kind,
data.1 as ts,
data.2 as mem
FROM system.query_log
WHERE event_time BETWEEN min_time AND max_time AND memory_usage != 0
UNION ALL
WITH
arrayJoin([(toFloat64(event_time_microseconds) - (view_duration_ms / 1000), toInt64(peak_memory_usage)), (toFloat64(event_time_microseconds), -peak_memory_usage)]) AS data
SELECT
CAST(toString(view_type)||'View','LowCardinality(String)') as t,
data.1 as ts,
data.2 as mem
FROM system.query_views_log
WHERE event_time BETWEEN min_time AND max_time AND peak_memory_usage != 0
)
)
GROUP BY timeframe
ORDER BY timeframe
FORMAT PrettyCompactMonoBlock;
retrospection analysis of trace_log
WITH
now() - INTERVAL 24 HOUR AS min_time, -- you can adjust that
now() AS max_time -- you can adjust that
SELECT
trace_type,
count(),
topK(20)(query_id)
FROM system.trace_log
WHERE event_time BETWEEN min_time AND max_time
GROUP BY trace_type;
SELECT
t,
count() AS queries,
formatReadableSize(sum(peak_size)) AS sum_of_peaks,
formatReadableSize(max(peak_size)) AS biggest_query_peak,
argMax(query_id, peak_size) AS query
FROM
(
SELECT
toStartOfInterval(event_time, toIntervalMinute(5)) AS t,
query_id,
max(size) AS peak_size
FROM system.trace_log
WHERE (trace_type = 'MemoryPeak') AND (event_time > (now() - toIntervalHour(24)))
GROUP BY
t,
query_id
)
GROUP BY t
ORDER BY t ASC;
-- later on you can check particular query_ids in query_log
analysis of the server text logs
grep MemoryTracker /var/log/clickhouse-server.log
zgrep MemoryTracker /var/log/clickhouse-server.log.*.gz
66 - X rows of Y total rows in filesystem are suspicious
Warning
The local set of parts of table doesn’t look like the set of parts in ZooKeeper. 100.00 rows of 150.00 total rows in filesystem are suspicious. There are 1 unexpected parts with 100 rows (1 of them is not just-written with 100 rows), 0 missing parts (with 0 blocks).: Cannot attach table.ClickHouse has a registry of parts in ZooKeeper.
And during the start ClickHouse compares that list of parts on a local disk is consistent with a list in ZooKeeper. If the lists are too different ClickHouse denies to start because it could be an issue with settings, wrong Shard or wrong Replica macros. But this safe-limiter throws an exception if the difference is more 50% (in rows).
In your case the table is very small and the difference >50% ( 100.00 vs 150.00 ) is only a single part mismatch, which can be the result of hard restart.
SELECT * FROM system.merge_tree_settings WHERE name = 'replicated_max_ratio_of_wrong_parts'
┌─name────────────────────────────────┬─value─┬─changed─┬─description──────────────────────────────────────────────────────────────────────────┬─type──┐
│ replicated_max_ratio_of_wrong_parts │ 0.5 │ 0 │ If ratio of wrong parts to total number of parts is less than this - allow to start. │ Float │
└─────────────────────────────────────┴───────┴─────────┴──────────────────────────────────────────────────────────────────────────────────────┴───────┘
You can set another value of replicated_max_ratio_of_wrong_parts for all MergeTree tables or per table.
https://clickhouse.tech/docs/en/operations/settings/merge-tree-settings
After manipulation with storage_policies and disks
When storage policy changes (one disk was removed from it), ClickHouse compared parts on disk and this replica state in ZooKeeper and found out that a lot of parts (from removed disk) disappeared. So ClickHouse removed them from the replica state in ZooKeeper and scheduled to fetch them from other replicas.
After we add the removed disk to storage_policy back, ClickHouse finds missing parts, but at this moment they are not registered for that replica. ClickHouse produce error message like this:
Warning
default.tbl from metadata file /var/lib/clickhouse/metadata/default/tbl.sql from query ATTACH TABLE default.tbl … ENGINE=ReplicatedMergeTree(’/clickhouse/tables/0/default/tbl’, ‘replica-0’)… SETTINGS index_granularity = 1024, storage_policy = ’ebs_hot_and_cold’: while loading database default from path /var/lib/clickhouse/metadata/dataAt this point, it’s possible to either tune setting replicated_max_ratio_of_wrong_parts or do force restore, but it will end up downloading all “missing” parts from other replicas, which can take a lot of time for big tables.
ClickHouse 21.7+
- Rename table SQL attach script in order to prevent ClickHouse from attaching it at startup.
mv /var/lib/clickhouse/metadata/default/tbl.sql /var/lib/clickhouse/metadata/default/tbl.sql.bak
Start ClickHouse server.
Remove metadata for this replica from ZooKeeper.
SYSTEM DROP REPLICA 'replica-0' FROM ZKPATH '/clickhouse/tables/0/default/tbl';
SELECT * FROM system.zookeeper WHERE path = '/clickhouse/tables/0/default/tbl/replicas';
- Rename table SQL attach script back to normal name.
mv /var/lib/clickhouse/metadata/default/tbl.sql.bak /var/lib/clickhouse/metadata/default/tbl.sql
- Attach table to ClickHouse server, because there is no metadata in ZooKeeper, ClickHouse will attach it in read only state.
ATTACH TABLE default.tbl;
- Run
SYSTEM RESTORE REPLICAin order to sync state on disk and in ZooKeeper.
SYSTEM RESTORE REPLICA default.tbl;
- Run
SYSTEM SYNC REPLICAto download missing parts from other replicas.
SYSTEM SYNC REPLICA default.tbl;
67 - ZooKeeper
Requirements
TLDR version:
- USE DEDICATED FAST DISKS for the transaction log! (crucial for performance due to write-ahead-log, NVMe is preferred for heavy load setup).
- use 3 nodes (more nodes = slower quorum, less = no HA).
- low network latency between zookeeper nodes is very important (latency, not bandwidth).
- have at least 4Gb of RAM, disable swap, tune JVM sizes, and garbage collector settings
- ensure that zookeeper will not be CPU-starved by some other processes
- monitor zookeeper .
Side note: in many cases, the slowness of the zookeeper is actually a symptom of some issue with ClickHouse® schema/usage pattern (the most typical issues: an enormous number of partitions/tables/databases with real-time inserts, tiny & frequent inserts).
How to install
- https://docs.altinity.com/operationsguide/clickhouse-zookeeper/zookeeper-installation/
- altinity-kb-setup-and-maintenance/altinity-kb-zookeeper/install_ubuntu/
Random links on best practices
- https://docs.confluent.io/platform/current/zookeeper/deployment.html
- https://zookeeper.apache.org/doc/r3.4.9/zookeeperAdmin.html#sc_commonProblems
- https://clickhouse.tech/docs/en/operations/tips/#zookeeper
- https://lucene.apache.org/solr/guide/7_4/setting-up-an-external-zookeeper-ensemble.html
- https://cwiki.apache.org/confluence/display/ZOOKEEPER/Troubleshooting
Cite from https://zookeeper.apache.org/doc/r3.5.7/zookeeperAdmin.html#sc_commonProblems :
Things to Avoid
Here are some common problems you can avoid by configuring ZooKeeper correctly:
- inconsistent lists of servers : The list of ZooKeeper servers used by the clients must match the list of ZooKeeper servers that each ZooKeeper server has. Things work okay if the client list is a subset of the real list, but things will really act strange if clients have a list of ZooKeeper servers that are in different ZooKeeper clusters. Also, the server lists in each Zookeeper server configuration file should be consistent with one another.
- incorrect placement of transaction log : The most performance critical part of ZooKeeper is the transaction log. ZooKeeper syncs transactions to media before it returns a response. A dedicated transaction log device is key to consistent good performance. Putting the log on a busy device will adversely affect performance. If you only have one storage device, increase the snapCount so that snapshot files are generated less often; it does not eliminate the problem, but it makes more resources available for the transaction log.
- incorrect Java heap size : You should take special care to set your Java max heap size correctly. In particular, you should not create a situation in which ZooKeeper swaps to disk. The disk is death to ZooKeeper. Everything is ordered, so if processing one request swaps the disk, all other queued requests will probably do the same. the disk. DON’T SWAP. Be conservative in your estimates: if you have 4G of RAM, do not set the Java max heap size to 6G or even 4G. For example, it is more likely you would use a 3G heap for a 4G machine, as the operating system and the cache also need memory. The best and only recommend practice for estimating the heap size your system needs is to run load tests, and then make sure you are well below the usage limit that would cause the system to swap.
- Publicly accessible deployment : A ZooKeeper ensemble is expected to operate in a trusted computing environment. It is thus recommended to deploy ZooKeeper behind a firewall.
How to check number of followers:
echo mntr | nc zookeeper 2187 | grep foll
zk_synced_followers 2
zk_synced_non_voting_followers 0
zk_avg_follower_sync_time 0.0
zk_min_follower_sync_time 0
zk_max_follower_sync_time 0
zk_cnt_follower_sync_time 0
zk_sum_follower_sync_time 0
Tools
Alternative for zkCli
Web UI
67.1 - clickhouse-keeper-initd
clickhouse-keeper-initd
An init.d script for clickhouse-keeper. This example is based on zkServer.sh
#!/bin/bash
### BEGIN INIT INFO
# Provides: clickhouse-keeper
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Required-Start:
# Required-Stop:
# Short-Description: Start keeper daemon
# Description: Start keeper daemon
### END INIT INFO
NAME=clickhouse-keeper
ZOOCFGDIR=/etc/$NAME
ZOOCFG="$ZOOCFGDIR/keeper.xml"
ZOO_LOG_DIR=/var/log/$NAME
USER=clickhouse
GROUP=clickhouse
ZOOPIDDIR=/var/run/$NAME
ZOOPIDFILE=$ZOOPIDDIR/$NAME.pid
SCRIPTNAME=/etc/init.d/$NAME
#echo "Using config: $ZOOCFG" >&2
ZOOCMD="clickhouse-keeper -C ${ZOOCFG} start --daemon"
# ensure PIDDIR exists, otw stop will fail
mkdir -p "$(dirname "$ZOOPIDFILE")"
if [ ! -w "$ZOO_LOG_DIR" ] ; then
mkdir -p "$ZOO_LOG_DIR"
fi
case $1 in
start)
echo -n "Starting keeper ... "
if [ -f "$ZOOPIDFILE" ]; then
if kill -0 `cat "$ZOOPIDFILE"` > /dev/null 2>&1; then
echo already running as process `cat "$ZOOPIDFILE"`.
exit 0
fi
fi
sudo -u clickhouse `echo "$ZOOCMD"`
if [ $? -eq 0 ]
then
pgrep -f "$ZOOCMD" > "$ZOOPIDFILE"
echo "PID:" `cat $ZOOPIDFILE`
if [ $? -eq 0 ];
then
sleep 1
echo STARTED
else
echo FAILED TO WRITE PID
exit 1
fi
else
echo SERVER DID NOT START
exit 1
fi
;;
start-foreground)
sudo -u clickhouse clickhouse-keeper -C "$ZOOCFG" start
;;
print-cmd)
echo "sudo -u clickhouse ${ZOOCMD}"
;;
stop)
echo -n "Stopping keeper ... "
if [ ! -f "$ZOOPIDFILE" ]
then
echo "no keeper to stop (could not find file $ZOOPIDFILE)"
else
ZOOPID=$(cat "$ZOOPIDFILE")
echo $ZOOPID
kill $ZOOPID
while true; do
sleep 3
if kill -0 $ZOOPID > /dev/null 2>&1; then
echo $ZOOPID is still running
else
break
fi
done
rm "$ZOOPIDFILE"
echo STOPPED
fi
exit 0
;;
restart)
shift
"$0" stop ${@}
sleep 3
"$0" start ${@}
;;
status)
clientPortAddress="localhost"
clientPort=2181
STAT=`echo srvr | nc $clientPortAddress $clientPort 2> /dev/null | grep Mode`
if [ "x$STAT" = "x" ]
then
echo "Error contacting service. It is probably not running."
exit 1
else
echo $STAT
exit 0
fi
;;
*)
echo "Usage: $0 {start|start-foreground|stop|restart|status|print-cmd}" >&2
esac
67.2 - clickhouse-keeper-service
clickhouse-keeper-service
installation
Need to install clickhouse-common-static + clickhouse-keeper OR clickhouse-common-static + clickhouse-server.
Both OK, use the first if you don’t need ClickHouse® server locally.
dpkg -i clickhouse-common-static_{%version}.deb clickhouse-keeper_{%version}.deb
dpkg -i clickhouse-common-static_{%version}.deb clickhouse-server_{%version}.deb clickhouse-client_{%version}.deb
Create directories
mkdir -p /etc/clickhouse-keeper/config.d
mkdir -p /var/log/clickhouse-keeper
mkdir -p /var/lib/clickhouse-keeper/coordination/log
mkdir -p /var/lib/clickhouse-keeper/coordination/snapshots
mkdir -p /var/lib/clickhouse-keeper/cores
chown -R clickhouse.clickhouse /etc/clickhouse-keeper /var/log/clickhouse-keeper /var/lib/clickhouse-keeper
config
cat /etc/clickhouse-keeper/config.xml
<?xml version="1.0"?>
<clickhouse>
<logger>
<!-- Possible levels [1]:
- none (turns off logging)
- fatal
- critical
- error
- warning
- notice
- information
- debug
- trace
- test (not for production usage)
[1]: https://github.com/pocoproject/poco/blob/poco-1.9.4-release/Foundation/include/Poco/Logger.h#L105-L114
-->
<level>trace</level>
<log>/var/log/clickhouse-keeper/clickhouse-keeper.log</log>
<errorlog>/var/log/clickhouse-keeper/clickhouse-keeper.err.log</errorlog>
<!-- Rotation policy
See https://github.com/pocoproject/poco/blob/poco-1.9.4-release/Foundation/include/Poco/FileChannel.h#L54-L85
-->
<size>1000M</size>
<count>10</count>
<!-- <console>1</console> --> <!-- Default behavior is autodetection (log to console if not daemon mode and is tty) -->
<!-- Per level overrides (legacy):
For example to suppress logging of the ConfigReloader you can use:
NOTE: levels.logger is reserved, see below.
-->
<!--
<levels>
<ConfigReloader>none</ConfigReloader>
</levels>
-->
<!-- Per level overrides:
For example to suppress logging of the RBAC for default user you can use:
(But please note that the logger name maybe changed from version to version, even after minor upgrade)
-->
<!--
<levels>
<logger>
<name>ContextAccess (default)</name>
<level>none</level>
</logger>
<logger>
<name>DatabaseOrdinary (test)</name>
<level>none</level>
</logger>
</levels>
-->
<!-- Structured log formatting:
You can specify log format(for now, JSON only). In that case, the console log will be printed
in specified format like JSON.
For example, as below:
{"date_time":"1650918987.180175","thread_name":"#1","thread_id":"254545","level":"Trace","query_id":"","logger_name":"BaseDaemon","message":"Received signal 2","source_file":"../base/daemon/BaseDaemon.cpp; virtual void SignalListener::run()","source_line":"192"}
To enable JSON logging support, just uncomment <formatting> tag below.
-->
<!-- <formatting>json</formatting> -->
</logger>
<!-- Listen specified address.
Use :: (wildcard IPv6 address), if you want to accept connections both with IPv4 and IPv6 from everywhere.
Notes:
If you open connections from wildcard address, make sure that at least one of the following measures applied:
- server is protected by firewall and not accessible from untrusted networks;
- all users are restricted to subset of network addresses (see users.xml);
- all users have strong passwords, only secure (TLS) interfaces are accessible, or connections are only made via TLS interfaces.
- users without password have readonly access.
See also: https://www.shodan.io/search?query=clickhouse
-->
<!-- <listen_host>::</listen_host> -->
<!-- Same for hosts without support for IPv6: -->
<!-- <listen_host>0.0.0.0</listen_host> -->
<!-- Default values - try listen localhost on IPv4 and IPv6. -->
<!--
<listen_host>::1</listen_host>
<listen_host>127.0.0.1</listen_host>
-->
<!-- <interserver_listen_host>::</interserver_listen_host> -->
<!-- Listen host for communication between replicas. Used for data exchange -->
<!-- Default values - equal to listen_host -->
<!-- Don't exit if IPv6 or IPv4 networks are unavailable while trying to listen. -->
<!-- <listen_try>0</listen_try> -->
<!-- Allow multiple servers to listen on the same address:port. This is not recommended.
-->
<!-- <listen_reuse_port>0</listen_reuse_port> -->
<!-- <listen_backlog>4096</listen_backlog> -->
<path>/var/lib/clickhouse-keeper/</path>
<core_path>/var/lib/clickhouse-keeper/cores</core_path>
<keeper_server>
<tcp_port>2181</tcp_port>
<server_id>1</server_id>
<log_storage_path>/var/lib/clickhouse-keeper/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse-keeper/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
<rotate_log_storage_interval>10000</rotate_log_storage_interval>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>localhost</hostname>
<port>9444</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
cat /etc/clickhouse-keeper/config.d/keeper.xml
<?xml version="1.0"?>
<clickhouse>
<listen_host>::</listen_host>
<keeper_server>
<tcp_port>2181</tcp_port>
<server_id>1</server_id>
<raft_configuration>
<server>
<id>1</id>
<hostname>keeper-host-1</hostname>
<port>9444</port>
</server>
<server>
<id>2</id>
<hostname>keeper-host-2</hostname>
<port>9444</port>
</server>
<server>
<id>3</id>
<hostname>keeper-host-3</hostname>
<port>9444</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
systemd service
cat /lib/systemd/system/clickhouse-keeper.service
[Unit]
Description=ClickHouse Keeper (analytic DBMS for big data)
Requires=network-online.target
# NOTE: that After/Wants=time-sync.target is not enough, you need to ensure
# that the time was adjusted already, if you use systemd-timesyncd you are
# safe, but if you use ntp or some other daemon, you should configure it
# additionaly.
After=time-sync.target network-online.target
Wants=time-sync.target
[Service]
Type=simple
User=clickhouse
Group=clickhouse
Restart=always
RestartSec=30
RuntimeDirectory=clickhouse-keeper
ExecStart=/usr/bin/clickhouse-keeper --config=/etc/clickhouse-keeper/config.xml --pid-file=/run/clickhouse-keeper/clickhouse-keeper.pid
# Minus means that this file is optional.
EnvironmentFile=-/etc/default/clickhouse
LimitCORE=infinity
LimitNOFILE=500000
CapabilityBoundingSet=CAP_NET_ADMIN CAP_IPC_LOCK CAP_SYS_NICE CAP_NET_BIND_SERVICE
[Install]
# ClickHouse should not start from the rescue shell (rescue.target).
WantedBy=multi-user.target
systemctl daemon-reload
systemctl status clickhouse-keeper
systemctl start clickhouse-keeper
debug start without service (as foreground application)
sudo -u clickhouse /usr/bin/clickhouse-keeper --config=/etc/clickhouse-keeper/config.xml
67.3 - Install standalone Zookeeper for ClickHouse® on Ubuntu / Debian
Reference script to install standalone Zookeeper for Ubuntu / Debian
Tested on Ubuntu 20.
# install java runtime environment
sudo apt-get update
sudo apt install default-jre
# prepare folders, logs folder should be on the low-latency disk.
sudo mkdir -p /var/lib/zookeeper/data /var/lib/zookeeper/logs /etc/zookeeper /var/log/zookeeper /opt
# download and install files
export ZOOKEEPER_VERSION=3.6.3
wget https://dlcdn.apache.org/zookeeper/zookeeper-${ZOOKEEPER_VERSION}/apache-zookeeper-${ZOOKEEPER_VERSION}-bin.tar.gz -O /tmp/apache-zookeeper-${ZOOKEEPER_VERSION}-bin.tar.gz
sudo tar -xvf /tmp/apache-zookeeper-${ZOOKEEPER_VERSION}-bin.tar.gz -C /opt
rm -rf /tmp/apache-zookeeper-${ZOOKEEPER_VERSION}-bin.tar.gz
# create the user
sudo groupadd -r zookeeper
sudo useradd -r -g zookeeper --home-dir=/var/lib/zookeeper --shell=/bin/false zookeeper
# symlink pointing to the used version of zookeeper distibution
sudo ln -s /opt/apache-zookeeper-${ZOOKEEPER_VERSION}-bin /opt/zookeeper
sudo chown -R zookeeper:zookeeper /var/lib/zookeeper /var/log/zookeeper /etc/zookeeper /opt/apache-zookeeper-${ZOOKEEPER_VERSION}-bin
sudo chown -h zookeeper:zookeeper /opt/zookeeper
# shortcuts in /usr/local/bin/
echo -e '#!/usr/bin/env bash\n/opt/zookeeper/bin/zkCli.sh "$@"' | sudo tee /usr/local/bin/zkCli
echo -e '#!/usr/bin/env bash\n/opt/zookeeper/bin/zkServer.sh "$@"' | sudo tee /usr/local/bin/zkServer
echo -e '#!/usr/bin/env bash\n/opt/zookeeper/bin/zkCleanup.sh "$@"' | sudo tee /usr/local/bin/zkCleanup
echo -e '#!/usr/bin/env bash\n/opt/zookeeper/bin/zkSnapShotToolkit.sh "$@"' | sudo tee /usr/local/bin/zkSnapShotToolkit
echo -e '#!/usr/bin/env bash\n/opt/zookeeper/bin/zkTxnLogToolkit.sh "$@"' | sudo tee /usr/local/bin/zkTxnLogToolkit
sudo chmod +x /usr/local/bin/zkCli /usr/local/bin/zkServer /usr/local/bin/zkCleanup /usr/local/bin/zkSnapShotToolkit /usr/local/bin/zkTxnLogToolkit
# put in the config
sudo cp opt/zookeeper/conf/* /etc/zookeeper
cat <<EOF | sudo tee /etc/zookeeper/zoo.cfg
initLimit=20
syncLimit=10
maxSessionTimeout=60000000
maxClientCnxns=2000
preAllocSize=131072
snapCount=3000000
dataDir=/var/lib/zookeeper/data
dataLogDir=/var/lib/zookeeper/logs # use low-latency disk!
clientPort=2181
#clientPortAddress=nthk-zoo1.localdomain
autopurge.snapRetainCount=10
autopurge.purgeInterval=1
4lw.commands.whitelist=*
EOF
sudo chown -R zookeeper:zookeeper /etc/zookeeper
# create systemd service file
cat <<EOF | sudo tee /etc/systemd/system/zookeeper.service
[Unit]
Description=Zookeeper Daemon
Documentation=http://zookeeper.apache.org
Requires=network.target
After=network.target
[Service]
Type=forking
WorkingDirectory=/var/lib/zookeeper
User=zookeeper
Group=zookeeper
Environment=ZK_SERVER_HEAP=1536 # in megabytes, adjust to ~ 80-90% of avaliable RAM (more than 8Gb is rather overkill)
Environment=SERVER_JVMFLAGS="-Xms256m -XX:+AlwaysPreTouch -Djute.maxbuffer=8388608 -XX:MaxGCPauseMillis=50"
Environment=ZOO_LOG_DIR=/var/log/zookeeper
ExecStart=/opt/zookeeper/bin/zkServer.sh start /etc/zookeeper/zoo.cfg
ExecStop=/opt/zookeeper/bin/zkServer.sh stop /etc/zookeeper/zoo.cfg
ExecReload=/opt/zookeeper/bin/zkServer.sh restart /etc/zookeeper/zoo.cfg
TimeoutSec=30
Restart=on-failure
[Install]
WantedBy=default.target
EOF
# start zookeeper
sudo systemctl daemon-reload
sudo systemctl start zookeeper.service
# check status etc.
echo stat | nc localhost 2181
echo ruok | nc localhost 2181
echo mntr | nc localhost 2181
67.4 - How to check the list of watches
Zookeeper use watches to notify a client on znode changes. This article explains how to check watches set by ZooKeeper servers and how it is used.
Solution:
Zookeeper uses the 'wchc' command to list all watches set on the Zookeeper server.
# echo wchc | nc zookeeper 2181
Reference
https://zookeeper.apache.org/doc/r3.4.12/zookeeperAdmin.html
The wchp and wchc commands are not enabled by default because of their known DOS vulnerability. For more information, see ZOOKEEPER-2693
and Zookeeper 3.5.2 - Denial of Service
.
By default those commands are disabled, they can be enabled via Java system property:
-Dzookeeper.4lw.commands.whitelist=*
on in zookeeper config: 4lw.commands.whitelist=*\
67.5 - JVM sizes and garbage collector settings
TLDR version
use fresh Java version (11 or newer), disable swap and set up (for 4 Gb node):
JAVA_OPTS="-Xms512m -Xmx3G -XX:+AlwaysPreTouch -Djute.maxbuffer=8388608 -XX:MaxGCPauseMillis=50"
If you have a node with more RAM - change it accordingly, for example for 8Gb node:
JAVA_OPTS="-Xms512m -Xmx7G -XX:+AlwaysPreTouch -Djute.maxbuffer=8388608 -XX:MaxGCPauseMillis=50"
Details
ZooKeeper runs as in JVM. Depending on version different garbage collectors are available.
Recent JVM versions (starting from 10) use
G1garbage collector by default (should work fine). On JVM 13-14 usingZGCorShenandoahgarbage collector may reduce pauses. On older JVM version (before 10) you may want to make some tuning to decrease pauses, ParNew + CMS garbage collectors (like in Yandex config) is one of the best options.One of the most important setting for JVM application is heap size. A heap size of >1 GB is recommended for most use cases and monitoring heap usage to ensure no delays are caused by garbage collection. We recommend to use at least 4Gb of RAM for zookeeper nodes (8Gb is better, that will make difference only when zookeeper is heavily loaded).
Set the Java heap size smaller than available RAM size on the node. This is very important to avoid swapping, which will seriously degrade ZooKeeper performance. Be conservative - use a maximum heap size of 3GB for a 4GB machine.
Add
XX:+AlwaysPreTouchflag as well to load the memory pages into memory at the start of the zookeeper.Set min (
Xms) heap size to the values like 512Mb, or even to the same value as max (Xmx) to avoid resizing and returning the RAM to OS. AddXX:+AlwaysPreTouchflag as well to load the memory pages into memory at the start of the zookeeper.MaxGCPauseMillis=50(by default 200) - the ’target’ acceptable pause for garbage collection (milliseconds)jute.maxbufferlimits the maximum size of znode content. By default it’s 1Mb. In some usecases (lot of partitions in table) ClickHouse® may need to create bigger znodes.(optional) enable GC logs:
-Xloggc:/path_to/gc.log
Zookeeper configuration used by Yandex Metrika (from 2017)
The configuration used by Yandex ( https://clickhouse.com/docs/en/operations/tips#zookeeper
) - they use older JVM version (with UseParNewGC garbage collector), and tune GC logs heavily:
JAVA_OPTS="-Xms{{ cluster.get('xms','128M') }} \
-Xmx{{ cluster.get('xmx','1G') }} \
-Xloggc:/var/log/$NAME/zookeeper-gc.log \
-XX:+UseGCLogFileRotation \
-XX:NumberOfGCLogFiles=16 \
-XX:GCLogFileSize=16M \
-verbose:gc \
-XX:+PrintGCTimeStamps \
-XX:+PrintGCDateStamps \
-XX:+PrintGCDetails
-XX:+PrintTenuringDistribution \
-XX:+PrintGCApplicationStoppedTime \
-XX:+PrintGCApplicationConcurrentTime \
-XX:+PrintSafepointStatistics \
-XX:+UseParNewGC \
-XX:+UseConcMarkSweepGC \
-XX:+CMSParallelRemarkEnabled"
See also
- https://wikitech.wikimedia.org/wiki/JVM_Tuning#G1_for_full_gcs
- https://sematext.com/blog/java-garbage-collection-tuning/
- https://www.oracle.com/technical-resources/articles/java/g1gc.html
- https://docs.oracle.com/cd/E40972_01/doc.70/e40973/cnf_jvmgc.htm#autoId2
- https://docs.cloudera.com/runtime/7.2.7/kafka-performance-tuning/topics/kafka-tune-broker-tuning-jvm.html
- https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/cm-tune-g1gc.html
- https://www.maknesium.de/21-most-important-java-8-vm-options-for-servers
- https://docs.oracle.com/javase/10/gctuning/introduction-garbage-collection-tuning.htm#JSGCT-GUID-326EB4CF-8C8C-4267-8355-21AB04F0D304
- https://github.com/chewiebug/GCViewer
67.6 - Proper setup
Main docs article
https://docs.altinity.com/operationsguide/clickhouse-zookeeper/zookeeper-installation/
Hardware requirements
TLDR version:
- USE DEDICATED FAST DISKS for the transaction log! (crucial for performance due to write-ahead-log, NVMe is preferred for heavy load setup).
- use 3 nodes (more nodes = slower quorum, less = no HA).
- low network latency between zookeeper nodes is very important (latency, not bandwidth).
- have at least 4Gb of RAM, disable swap, tune JVM sizes, and garbage collector settings.
- ensure that zookeeper will not be CPU-starved by some other processes
- monitor zookeeper.
Side note: in many cases, the slowness of the zookeeper is actually a symptom of some issue with ClickHouse® schema/usage pattern (the most typical issues: an enormous number of partitions/tables/databases with real-time inserts, tiny & frequent inserts).
Some doc about that subject:
- https://docs.confluent.io/platform/current/zookeeper/deployment.html
- https://zookeeper.apache.org/doc/r3.4.9/zookeeperAdmin.html#sc_commonProblems
- https://clickhouse.tech/docs/en/operations/tips/#zookeeper
- https://lucene.apache.org/solr/guide/7_4/setting-up-an-external-zookeeper-ensemble.html
- https://cwiki.apache.org/confluence/display/ZOOKEEPER/Troubleshooting
Cite from https://zookeeper.apache.org/doc/r3.5.7/zookeeperAdmin.html#sc_commonProblems :
Things to Avoid
Here are some common problems you can avoid by configuring ZooKeeper correctly:
- inconsistent lists of servers : The list of ZooKeeper servers used by the clients must match the list of ZooKeeper servers that each ZooKeeper server has. Things work okay if the client list is a subset of the real list, but things will really act strange if clients have a list of ZooKeeper servers that are in different ZooKeeper clusters. Also, the server lists in each Zookeeper server configuration file should be consistent with one another.
- incorrect placement of transaction log : The most performance critical part of ZooKeeper is the transaction log. ZooKeeper syncs transactions to media before it returns a response. A dedicated transaction log device is key to consistent good performance. Putting the log on a busy device will adversely affect performance. If you only have one storage device, increase the snapCount so that snapshot files are generated less often; it does not eliminate the problem, but it makes more resources available for the transaction log.
- incorrect Java heap size : You should take special care to set your Java max heap size correctly. In particular, you should not create a situation in which ZooKeeper swaps to disk. The disk is death to ZooKeeper. Everything is ordered, so if processing one request swaps the disk, all other queued requests will probably do the same. the disk. DON’T SWAP. Be conservative in your estimates: if you have 4G of RAM, do not set the Java max heap size to 6G or even 4G. For example, it is more likely you would use a 3G heap for a 4G machine, as the operating system and the cache also need memory. The best and only recommend practice for estimating the heap size your system needs is to run load tests, and then make sure you are well below the usage limit that would cause the system to swap.
- Publicly accessible deployment : A ZooKeeper ensemble is expected to operate in a trusted computing environment. It is thus recommended to deploy ZooKeeper behind a firewall.
67.7 - Recovering from complete metadata loss in ZooKeeper
Problem
Every ClickHouse® user experienced a loss of ZooKeeper one day. While the data is available and replicas respond to queries, inserts are no longer possible. ClickHouse uses ZooKeeper in order to store the reference version of the table structure and part of data, and when it is not available can not guarantee data consistency anymore. Replicated tables turn to the read-only mode. In this article we describe step-by-step instructions of how to restore ZooKeeper metadata and bring ClickHouse cluster back to normal operation.
In order to restore ZooKeeper we have to solve two tasks. First, we need to restore table metadata in ZooKeeper. Currently, the only way to do it is to recreate the table with the CREATE TABLE DDL statement.
CREATE TABLE table_name ... ENGINE=ReplicatedMergeTree('zookeeper_path','replica_name');
The second and more difficult task is to populate zookeeper with information of ClickHouse data parts. As mentioned above, ClickHouse stores the reference data about all parts of replicated tables in ZooKeeper, so we have to traverse all partitions and re-attach them to the recovered replicated table in order to fix that.
Info
Starting from ClickHouse version 21.7 there is SYSTEM RESTORE REPLICA commandhttps://altinity.com/blog/a-new-way-to-restore-clickhouse-after-zookeeper-metadata-is-lost
Test case
Let’s say we have replicated table table_repl.
CREATE TABLE table_repl
(
`number` UInt32
)
ENGINE = ReplicatedMergeTree('/clickhouse/{cluster}/tables/{shard}/table_repl','{replica}')
PARTITION BY intDiv(number, 1000)
ORDER BY number;
And populate it with some data
SELECT * FROM system.zookeeper WHERE path='/clickhouse/cluster_1/tables/01/';
INSERT INTO table_repl SELECT * FROM numbers(1000,2000);
SELECT partition, sum(rows) AS rows, count() FROM system.parts WHERE table='table_repl' AND active GROUP BY partition;
Now let’s remove metadata in zookeeper using ZkCli.sh at ZooKeeper host:
deleteall /clickhouse/cluster_1/tables/01/table_repl
And try to resync ClickHouse replica state with zookeeper:
SYSTEM RESTART REPLICA table_repl;
If we try to insert some data in the table, error happens:
INSERT INTO table_repl SELECT number AS number FROM numbers(1000,2000) WHERE number % 2 = 0;
And now we have an exception that we lost all metadata in zookeeper. It is time to recover!
Current Solution
Detach replicated table.
DETACH TABLE table_repl;Save the table’s attach script and change engine of replicated table to non-replicated *mergetree analogue. Table definition is located in the ‘metadata’ folder, ‘
/var/lib/clickhouse/metadata/default/table_repl.sql’ in our example. Please make a backup copy and modify the file as follows:ATTACH TABLE table_repl ( `number` UInt32 ) ENGINE = ReplicatedMergeTree('/clickhouse/{cluster}/tables/{shard}/table_repl', '{replica}') PARTITION BY intDiv(number, 1000) ORDER BY number SETTINGS index_granularity = 8192Needs to be replaced with this:
ATTACH TABLE table_repl ( `number` UInt32 ) ENGINE = MergeTree() PARTITION BY intDiv(number, 1000) ORDER BY number SETTINGS index_granularity = 8192Attach non-replicated table.
ATTACH TABLE table_repl;Rename non-replicated table.
RENAME TABLE table_repl TO table_repl_old;Create a new replicated table. Take the saved attach script and replace ATTACH with CREATE, and run it.
CREATE TABLE table_repl ( `number` UInt32 ) ENGINE = ReplicatedMergeTree('/clickhouse/{cluster}/tables/{shard}/table_repl', '{replica}') PARTITION BY intDiv(number, 1000) ORDER BY number SETTINGS index_granularity = 8192Attach parts from old table to new.
ALTER TABLE table_repl ATTACH PARTITION 1 FROM table_repl_old; ALTER TABLE table_repl ATTACH PARTITION 2 FROM table_repl_old;
If the table has many partitions, it may require some shell script to make it easier.
Automated approach
For a large number of tables, you can use script https://github.com/Altinity/clickhouse-zookeeper-recovery which partially automates the above approach.
67.8 - Using clickhouse-keeper
Since 2021 the development of built-in ClickHouse® alternative for Zookeeper is happening, whose goal is to address several design pitfalls, and get rid of extra dependency.
See slides: https://presentations.clickhouse.com/meetup54/keeper.pdf and video https://youtu.be/IfgtdU1Mrm0?t=2682
Current status (last updated: March 2026)
ClickHouse Keeper is the recommended choice for new installations. It yields better performance in many cases due to the new features, like async replication or multi read. Some ClickHouse server features cannot be used without Keeper, for example the S3Queue.
- Use the latest Keeper version available in your supported upgrade path whenever possible.
- The Keeper version doesn’t need to match the ClickHouse server version
- Modern Keeper usually performs better than older versions because the codebase has matured significantly, new protocol feature flags have been added, and internal replication has improved.
For existing systems that currently use Apache Zookeeper, you can consider upgrading to clickhouse-keeper especially if you will upgrade ClickHouse also.
Warning
Before upgrading ClickHouse Keeper from version older than 23.9 please check Upgrade caveat for async_replication Upgrade caveat for async_replicationHow does clickhouse-keeper differ from Zookeeper?
Keeper is optimized for ClickHouse workloads and written in C++ (and can be used as single-binary), so it don’t need any external dependencies. It uses the same client protocol but both are implementing different consensus protocol: Zookeeper is using ZAB, while ClickHouse Keeper implements eBay NuRAFT GitHub - eBay/NuRaft: C++ implementation of Raft core logic as a replication library which improves stability and performance of base RAFT protocol.
ClickHouse Keeper can also run in embedded mode, operating as a separate thread within the ClickHouse server process, which may be suitable for testing purposes or smaller instances where some performance can be sacrificed for simplicity
Migration and upgrade guide
- A mixed ZooKeeper / ClickHouse Keeper quorum is not supported. Those are different consensus protocols.
- ZooKeeper snapshots and transaction logs are not format-compatible with Keeper. For data migration use
clickhouse-keeper-converter. - If the above is too complex you can switch to new, empty Keeper ensemble and recreate the Keeper metadata using
SYSTEM RESTORE REPLICAcalls. This method takes longer time but it is suitable for smaller clusters. Check procedure to restore multiple tables in RO mode article - Keep in mind that some metadata is available in ZooKeeper only and will be lost if you don’t migrate with clickhouse-keeper-converter using above guide. For example: Distributed DDL queue, RBAC data (if configured), etc. Check Keeper depended features for more information.
Upgrade caveat for async_replication
async_replication is an internal Keeper optimization for RAFT replication and it’s turned on by default starting from 25.10
. It does not change ClickHouse replicated table semantics, but it can improve Keeper performance.
If you upgrade directly from a version older than 23.9 to 25.10+:
- either upgrade Keeper to
23.9+first, and then continue to25.10+ - or temporarily set
keeper_server.coordination_settings.async_replication=0during the upgrade and enable it after the upgrade is finished
Keeper in kubernetes
If you run ClickHouse on Kubernetes with Altinity operator, Keeper can be managed as a dedicated ClickHouseKeeperInstallation resource (often abbreviated as CHK). That is usually the cleanest way to run and upgrade a separate Keeper ensemble on Kubernetes. Please check examples here
.
systemd service file
init.d script
More than 3 Keeper nodes
The main issue with a larger Keeper ensemble is that it takes more time to re-elect a leader, and commits take longer, which can slow down insertions and DDL queries.
It should be fine, but we don’t recommend running more than three Keeper nodes (excluding observers).
Increasing the number of nodes offers no significant advantages (unless you need to tolerate the simultaneous failure of two Keeper nodes). In terms of performance, it doesn’t perform better—and may even perform worse—and it consumes additional resources (ZooKeeper requires fast, dedicated disks to perform well, as well as some RAM and CPU).
clickhouse-keeper-client
In clickhouse-keeper-client, paths are now parsed more strictly and must be passed as string literals. In practice, this means using single quotes around paths—for example, ls '/' instead of ls /, and get '/clickhouse/path' instead of get /clickhouse/path.
Embedded Keeper
To use the embedded ClickHouse Keeper, add the <keeper_server> section to the ClickHouse server configuration. In this setup, a separate client-side <keeper> section is not required. If your ClickHouse servers use an external ClickHouse Keeper or ZooKeeper ensemble instead, see the section below.
Example of a simple cluster
The Keeper ensemble size must be odd because it requires a majority (50% + 1 nodes) to form a quorum. A 2-node Keeper setup will lose quorum after a single node failure, so the recommended number of Keeper replicas is 3.
hostname1
$ cat /etc/clickhouse-server/config.d/keeper.xml
<?xml version="1.0" ?>
<clickhouse>
<keeper_server>
<tcp_port>2181</tcp_port>
<server_id>1</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
<rotate_log_storage_interval>10000</rotate_log_storage_interval>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>hostname1</hostname>
<port>9444</port>
</server>
<server>
<id>2</id>
<hostname>hostname2</hostname>
<port>9444</port>
</server>
<server>
<id>3</id>
<hostname>hostname3</hostname>
<port>9444</port>
</server>
</raft_configuration>
</keeper_server>
<distributed_ddl>
<path>/clickhouse/testcluster/task_queue/ddl</path>
</distributed_ddl>
</clickhouse>
$ cat /etc/clickhouse-server/config.d/macros.xml
<?xml version="1.0" ?>
<clickhouse>
<macros>
<cluster>testcluster</cluster>
<replica>replica1</replica>
<shard>1</shard>
</macros>
</clickhouse>
hostname2
$ cat /etc/clickhouse-server/config.d/keeper.xml
<?xml version="1.0" ?>
<clickhouse>
<keeper_server>
<tcp_port>2181</tcp_port>
<server_id>2</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
<rotate_log_storage_interval>10000</rotate_log_storage_interval>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>hostname1</hostname>
<port>9444</port>
</server>
<server>
<id>2</id>
<hostname>hostname2</hostname>
<port>9444</port>
</server>
<server>
<id>3</id>
<hostname>hostname3</hostname>
<port>9444</port>
</server>
</raft_configuration>
</keeper_server>
<distributed_ddl>
<path>/clickhouse/testcluster/task_queue/ddl</path>
</distributed_ddl>
</clickhouse>
$ cat /etc/clickhouse-server/config.d/macros.xml
<?xml version="1.0" ?>
<clickhouse>
<macros>
<cluster>testcluster</cluster>
<replica>replica2</replica>
<shard>1</shard>
</macros>
</clickhouse>
hostname3
$ cat /etc/clickhouse-keeper/keeper_config.xml
<?xml version="1.0" ?>
<clickhouse>
<keeper_server>
<tcp_port>2181</tcp_port>
<server_id>3</server_id>
<log_storage_path>/var/lib/clickhouse/coordination/log</log_storage_path>
<snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path>
<coordination_settings>
<operation_timeout_ms>10000</operation_timeout_ms>
<session_timeout_ms>30000</session_timeout_ms>
<raft_logs_level>trace</raft_logs_level>
<rotate_log_storage_interval>10000</rotate_log_storage_interval>
</coordination_settings>
<raft_configuration>
<server>
<id>1</id>
<hostname>hostname1</hostname>
<port>9444</port>
</server>
<server>
<id>2</id>
<hostname>hostname2</hostname>
<port>9444</port>
</server>
<server>
<id>3</id>
<hostname>hostname3</hostname>
<port>9444</port>
</server>
</raft_configuration>
</keeper_server>
</clickhouse>
$ clickhouse-keeper --config /etc/clickhouse-keeper/keeper_config.xml
on both ClickHouse nodes
$ cat /etc/clickhouse-server/config.d/clusters.xml
<?xml version="1.0" ?>
<clickhouse>
<remote_servers>
<testcluster>
<shard>
<replica>
<host>hostname1</host>
<port>9000</port>
</replica>
<replica>
<host>hostname2</host>
<port>9000</port>
</replica>
</shard>
</testcluster>
</remote_servers>
</clickhouse>
Then create a table
create table test on cluster '{cluster}' ( A Int64, S String)
Engine = ReplicatedMergeTree('/clickhouse/{cluster}/tables/{database}/{table}','{replica}')
Order by A;
insert into test select number, '' from numbers(100000000);
-- on both nodes:
select count() from test;
Useful references
- Official Keeper guide: https://clickhouse.com/docs/en/guides/sre/keeper/clickhouse-keeper/
clickhouse-keeper-client: https://clickhouse.com/docs/en/operations/utilities/clickhouse-keeper-client- Keeper HTTP API and dashboard (
26.1+): https://clickhouse.com/docs/operations/utilities/clickhouse-keeper-http-api system.zookeeper: https://clickhouse.com/docs/operations/system-tables/zookeepersystem.zookeeper_connection: https://clickhouse.com/docs/operations/system-tables/zookeeper_connectionsystem.zookeeper_connection_log: https://clickhouse.com/docs/operations/system-tables/zookeeper_connection_logsystem.zookeeper_info(26.1+): https://clickhouse.com/docs/operations/system-tables/zookeeper_infosystem.zookeeper_log: https://clickhouse.com/docs/operations/system-tables/zookeeper_logaggregated_zookeeper_logupstream PR: resubmit https://github.com/ClickHouse/ClickHouse/pull/87208- Altinity operator CHK examples: https://github.com/Altinity/clickhouse-operator/tree/master/docs/chk-examples
- Altinity operator Keeper dashboard JSON: https://github.com/Altinity/clickhouse-operator/blob/master/grafana-dashboard/ClickHouseKeeper_dashboard.json
- Altinity operator Keeper alert rules: https://github.com/Altinity/clickhouse-operator/blob/master/deploy/prometheus/prometheus-alert-rules-chkeeper.yaml
67.9 - ZooKeeper backup
Question: Do I need to backup Zookeeper Database, because it’s pretty important for ClickHouse®?
TLDR answer: NO, just backup ClickHouse data itself, and do SYSTEM RESTORE REPLICA during recovery to recreate zookeeper data
Details:
Zookeeper does not store any data, it stores the STATE of the distributed system (“that replica have those parts”, “still need 2 merges to do”, “alter is being applied” etc). That state always changes, and you can not capture / backup / and recover that state in a safe manner. So even backup from few seconds ago is representing some ‘old state from the past’ which is INCONSISTENT with actual state of the data.
In other words - if ClickHouse is working - then the state of distributed system always changes, and it’s almost impossible to collect the current state of zookeeper (while you collecting it it will change many times). The only exception is ‘stop-the-world’ scenario - i.e. shutdown all ClickHouse nodes, with all other zookeeper clients, then shutdown all the zookeeper, and only then take the backups, in that scenario and backups of zookeeper & ClickHouse will be consistent. In that case restoring the backup is as simple (and is equal to) as starting all the nodes which was stopped before. But usually that scenario is very non-practical because it requires huge downtime.
So what to do instead? It’s enough if you will backup ClickHouse data itself, and to recover the state of zookeeper you can just run the command SYSTEM RESTORE REPLICA command AFTER restoring the ClickHouse data itself. That will recreate the state of the replica in the zookeeper as it exists on the filesystem after backup recovery.
Normally Zookeeper ensemble consists of 3 nodes, which is enough to survive hardware failures.
On older version (which don’t have SYSTEM RESTORE REPLICA command - it can be done manually, using instruction https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/replication/#converting-from-mergetree-to-replicatedmergetree)
, on scale you can try https://github.com/Altinity/clickhouse-zookeeper-recovery
67.10 - ZooKeeper cluster migration
Here is a plan for ZK 3.4.9 (no dynamic reconfiguration):
- Add the 3 new ZK nodes to the old cluster. No changes needed for the 3 old ZK nodes at this time.
- Configure one of the new ZK nodes as a cluster of 4 nodes (3 old + 1 new), start it.
- Configure the other two new ZK nodes as a cluster of 6 nodes (3 old + 3 new), start them.
- Make sure the 3 new ZK nodes connected to the old ZK cluster as followers (run
echo stat | nc localhost 2181on the 3 new ZK nodes) - Confirm that the leader has 5 synced followers (run
echo mntr | nc localhost 2181on the leader, look forzk_synced_followers) - Stop data ingestion in CH (this is to minimize errors when CH loses ZK).
- Change the zookeeper section in the configs on the CH nodes (remove the 3 old ZK servers, add the 3 new ZK servers)
- Make sure that there are no connections from CH to the 3 old ZK nodes (run
echo stat | nc localhost 2181on the 3 old nodes, check theirClientssection). Restart all CH nodes if necessary (In some cases CH can reconnect to different ZK servers without a restart). - Remove the 3 old ZK nodes from
zoo.cfgon the 3 new ZK nodes. - Restart the 3 new ZK nodes. They should form a cluster of 3 nodes.
- When CH reconnects to ZK, start data loading.
- Turn off the 3 old ZK nodes.
This plan works, but it is not the only way to do this, it can be changed if needed.
67.11 - ZooKeeper cluster migration when using K8s node local storage
Describes how to migrate a ZooKeeper cluster when using K8s node-local storage such as static PV, local-path, TopoLVM.
Requires HA setup (3+ pods).
This solution is more risky than migration by adding followers
because it reduces
the number of active consensus members but is operationally simpler. When running with clickhouse-keeper, it can be
performed gracefully so that quorum is maintained during the whole operation.
- Find the leader pod and note its name
- To detect leader run
echo stat | nc 127.0.0.1 2181 | grep leaderinside pods
- To detect leader run
- Make sure the ZK cluster is healthy and all nodes are in sync
- (run on leader)
echo mntr | nc 127.0.0.1 2181 | grep zk_synced_followersshould be N-1 for N member cluster
- (run on leader)
- Pick the first non-leader pod and delete its
PVC,kubectl delete --wait=false pvc clickhouse-keeper-data-0-> status should beTerminating- Also delete
PVif yourStorageClassreclaim policy is set toRetain
- If you are using dynamic volume provisioning make adjustments based on your k8s infrastructure (such as moving labels and taints or cordoning node) so that after pod delete the new one will be scheduled on the planned node
kubectl label node planned-node dedicated=zookeeperkubectl label node this-pod-node dedicated-kubectl taint node planned-node dedicated=zookeeper:NoSchedulekubectl taint node this-pod-node dedicated=zookeeper:NoSchedule-
- For manual volume provisioning wait till a new
PVCis created and then provision volume on the planned node - Delete the first non-leader pod and wait for its PV to be deleted
kubectl delete pod clickhouse-keeper-0kubectl wait --for=delete pv/pvc-0a823311-616f-4b7e-9b96-0c059c62ab3b --timeout=120s
- Wait for the new pod to be scheduled and volume provisioned (or provision manual volume per instructions above)
- Ensure new member joined and synced
- (run on leader)
echo mntr | nc 127.0.0.1 2181 | grep zk_synced_followersshould be N-1 for N member cluster
- (run on leader)
- Repeat for all other non-leader pods
- (ClickHouse® Keeper only), for Zookeeper you will need to force an election by stopping the leader
- Ask the current leader to yield leadership
echo ydld | nc 127.0.0.1 2181-> should print something likeSent yield leadership request to ...- Make sure a different leader was elected by finding your new leader
- Finally repeat for the leader pod
67.12 - ZooKeeper Monitoring
ZooKeeper
scrape metrics
- embedded exporter since version 3.6.0
- standalone exporter
Install dashboards
- embedded exporter https://grafana.com/grafana/dashboards/10465
- dabealu exporter https://grafana.com/grafana/dashboards/11442
See also https://grafana.com/grafana/dashboards?search=ZooKeeper&dataSource=prometheus
setup alert rules
- embedded exporter link
See also
- https://www.datadoghq.com/blog/monitoring-kafka-performance-metrics/#zookeeper-metrics
- https://dzone.com/articles/monitoring-apache-zookeeper-servers - note exhibitor is no longer maintained
- https://github.com/samber/awesome-prometheus-alerts/blob/c3ba0cf1997c7e952369a090aeb10343cdca4878/_data/rules.yml#L1146-L1170 (or https://awesome-prometheus-alerts.grep.to/rules.html#zookeeper )
- https://alex.dzyoba.com/blog/prometheus-alerts/
- https://docs.datadoghq.com/integrations/zk/?tab=host
- https://statuslist.app/uptime-monitoring/zookeeper/
67.13 - ZooKeeper schema
/metadata
Table schema.
date column -> legacy MergeTree partition expression.
sampling expression -> SAMPLE BY
index granularity -> index_granularity
mode -> type of MergeTree table
sign column -> sign - CollapsingMergeTree / VersionedCollapsingMergeTree
primary key -> ORDER BY key if PRIMARY KEY not defined.
sorting key -> ORDER BY key if PRIMARY KEY defined.
data format version -> 1
partition key -> PARTITION BY
granularity bytes -> index_granularity_bytes
types of MergeTree tables:
Ordinary = 0
Collapsing = 1
Summing = 2
Aggregating = 3
Replacing = 5
Graphite = 6
VersionedCollapsing = 7
/mutations
Log of latest mutations
/columns
List of columns for latest (reference) table version. Replicas would try to reach this state.
/log
Log of latest actions with table.
Related settings:
┌─name────────────────────────┬─value─┬─changed─┬─description────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬─type───┐
│ max_replicated_logs_to_keep │ 1000 │ 0 │ How many records may be in log, if there is inactive replica. Inactive replica becomes lost when when this number exceed. │ UInt64 │
│ min_replicated_logs_to_keep │ 10 │ 0 │ Keep about this number of last records in ZooKeeper log, even if they are obsolete. It doesn't affect work of tables: used only to diagnose ZooKeeper log before cleaning. │ UInt64 │
└─────────────────────────────┴───────┴─────────┴────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┴────────┘
/replicas
List of table replicas.
/replicas/replica_name/
/replicas/replica_name/mutation_pointer
Pointer to the latest mutation executed by replica
/replicas/replica_name/log_pointer
Pointer to the latest task from replication_queue executed by replica
/replicas/replica_name/max_processed_insert_time
/replica/replica_name/metadata
Table schema of specific replica
/replica/replica_name/columns
Columns list of specific replica.
/quorum
Used for quorum inserts.